I use Jsoup to write a crawler, and I usually encounter HTML that returns no content. But the browser displays some content. They all analyze the http request log of the page. Analyze the JS code of the page to solve it.
1. Some page elements are hidden ->Change the selector to solve the problem 2. Some data are stored in js/json objects->Intercept the corresponding strings, analyze and solve the problem 3. Call through the api interface->Fake requests Get data
There is another ultimate method 4. Use a headless browser like phantomjs or casperjs
Some of the answers mentioned that it is possible to analyze the interface and crawl the interface directly. Moreover, crawling the interface directly does not require you to parse the HTML yourself, because most interfaces return json. I feel happy just thinking about it~
However, there are still other methods, such as using Phantomjs, which is simple and easy to use. Python is not omnipotent and will have greater value when combined with other tools. I also have some small projects that are such a combination.
This is an official example code, which can be achieved with a little modification.
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://phantomjs.org/';
page.open(url, function (status) {
//Page is loaded!
phantom.exit();
});
Renovated
var page = require('webpage').create();
var url = 'http://phantomjs.org/';
page.open(url, function (status) {
page.evaluate(function() {
// 页面被执行完之后,一般js生成的内容也可以获得了,但是Ajax生成的内容则不一定
document.getElementById('xxx'); // 可以操作DOM,这里你就可以尝试获取你想要的内容了
// ...
})
phantom.exit();
});
But in fact, in many cases, you need to wait for Ajax to be executed before starting to parse the content of the page. At this time, you can use an official sample code. Using this function, you can wait for all requests for this page to be loaded before continuing. Processing, then you can get the fully loaded page, and then you can do whatever you need to do.
Example of using selenium to mine new disc charts:
from selenium import webdriver
dirver = webdriver.Chrome()
dirver.get('https://music.douban.com/')
for i in dirver.find_elements_by_css_selector('.new-albums .album-title'):
print i.text
Results: Open today Jay Chou's Bedside Story H.A.M. 3집 EX'ACT Wild Dangerous Woman In the dark Last Year Was Complicated
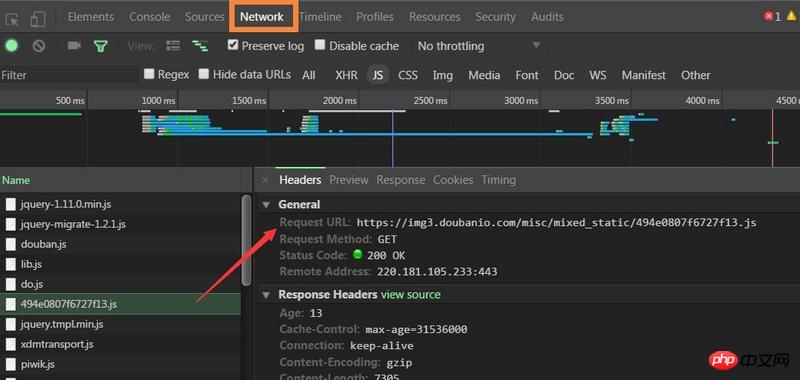
Chrome, press F12, click, view the request, it is easy to find the URL and parameters, just construct it yourself, and then parse the returned content.
Open chrome to inspect the element and look for js in the network. Generally, the js with a special name may be what you are looking for. For example, this one,
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




I use Jsoup to write a crawler, and I usually encounter HTML that returns no content. But the browser displays some content. They all analyze the http request log of the page. Analyze the JS code of the page to solve it.
1. Some page elements are hidden ->Change the selector to solve the problem
2. Some data are stored in js/json objects->Intercept the corresponding strings, analyze and solve the problem
3. Call through the api interface->Fake requests Get data
There is another ultimate method
4. Use a headless browser like phantomjs or casperjs
Some of the answers mentioned that it is possible to analyze the interface and crawl the interface directly. Moreover, crawling the interface directly does not require you to parse the HTML yourself, because most interfaces return json. I feel happy just thinking about it~
However, there are still other methods, such as using Phantomjs, which is simple and easy to use. Python is not omnipotent and will have greater value when combined with other tools. I also have some small projects that are such a combination.
This is an official example code, which can be achieved with a little modification.
Renovated
But in fact, in many cases, you need to wait for Ajax to be executed before starting to parse the content of the page. At this time, you can use an official sample code. Using this function, you can wait for all requests for this page to be loaded before continuing. Processing, then you can get the fully loaded page, and then you can do whatever you need to do.
Find the data interface yourself
They should all be generated by the API interface
Example of using selenium to mine new disc charts:
Results:
Open today
Jay Chou's Bedside Story
H.A.M.
3집 EX'ACT
Wild
Dangerous Woman
In the dark
Last Year Was Complicated
Chrome, press F12, click, view the request, it is easy to find the URL and parameters, just construct it yourself, and then parse the returned content.
Index.html, this line of js is quoted.
Open this js file and you can see
Open chrome to inspect the element and look for js in the network. Generally, the js with a special name may be what you are looking for. For example, this one,
The most direct way is to use selenium