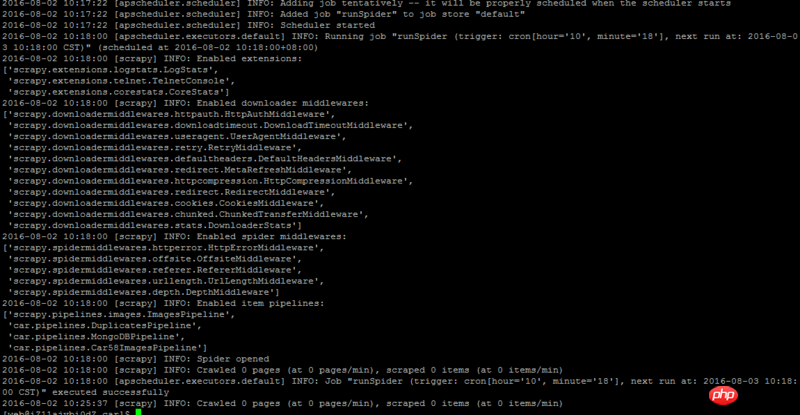
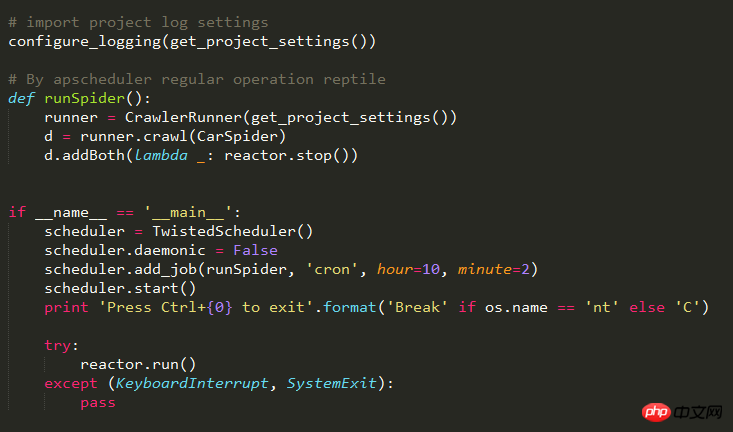
After much fiddling and searching over the wall, I finally got it running under Linux. The first time the crawler job was scheduled, it was turned on, but the web page was not parsed. Only when it was scheduled for the second time did it start parsing and work normally. My own guess is that it is related to react.run(). When the apscheduler task scheduling framework is used in conjunction with Scrapy, it must be used under the twisted framework. When the crawler task is to be executed regularly, the parsing will not be performed for the first time, but will be parsed for the second time.















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




After much fiddling and searching over the wall, I finally got it running under Linux. The first time the crawler job was scheduled, it was turned on, but the web page was not parsed. Only when it was scheduled for the second time did it start parsing and work normally. My own guess is that it is related to react.run(). When the apscheduler task scheduling framework is used in conjunction with Scrapy, it must be used under the twisted framework. When the crawler task is to be executed regularly, the parsing will not be performed for the first time, but will be parsed for the second time.