
我在爬取凤凰网却出现
UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position 151120: illegal multibyte sequence
这是我的代码
__author__ = 'my'
import urllib.request
url = 'http://www.ifeng.com/'
req = urllib.request.urlopen(url)
req = req.read()
req = req.decode('utf-8')
print(req)
为什么utf8却报错GBK?














![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




This is a problem with cmd.exe, other software can decode it correctly. For example, notepad, browser. . . .
Added:
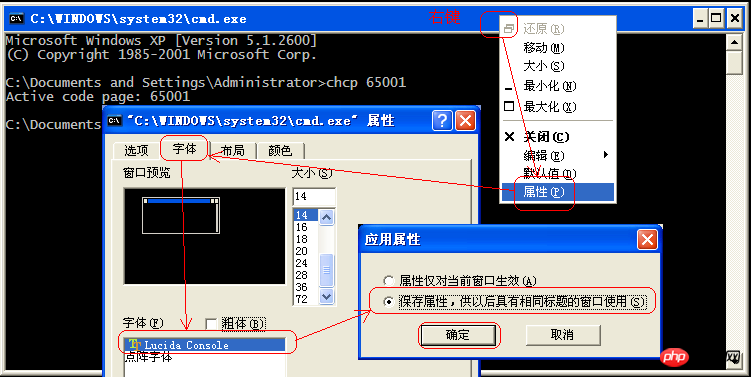
In fact, you can also modify the encoding of cmd.exe to utf-8 (cp65001)
Steps:
1. Run CMD.exe
2, chcp 65001
3. Modify the font of the window properties
On the CMD window title bar Right-click, select "Properties"->"Font", and change the font to the True Type font "Lucida Console"
As shown in the picture:
4. Run python
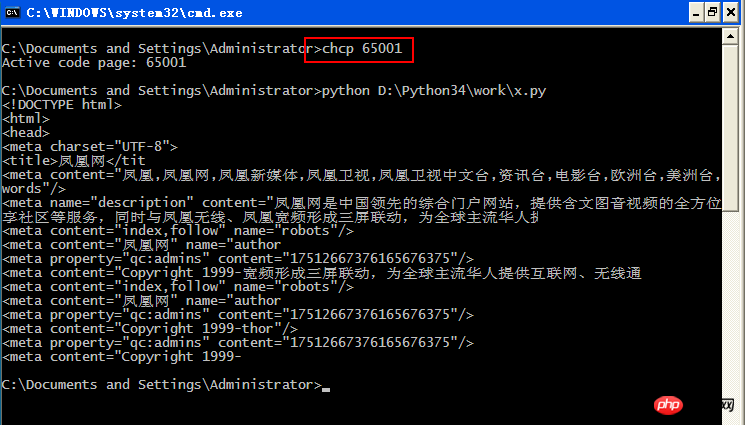
Contents ofx.py:
I just put the code of the question into pycharm, and this problem did not occur. Then I used the Windows command prompt to type line by line, and this problem occurred. The windows command prompt uses gbk encoding, and the web page itself uses utf-8 for encoding. If you want to run it from the command line, you need to write:
Here
req = req.decode('gbk', 'ignore')Let me explain: To display in the windows command prompt, it needs to be decoded to gbk, but utf-8 itself has some characters that will fail to decode using gbk, so the second parameter ignore is needed , this parameter means discarding characters that cannot be decoded.As an aside, encoding may also encounter this problem. For example, if you use the requests library to request, it will be the requested string instead of the byte type. If you encounter problems with encoding, you can also use str.encode('encoding', 'ingore ').decode('decode') to solve similar problems.
If you don’t understand, you can read this blog of mine
To answer a question from the subject, some web pages are fine. It may be that some web pages use GBK encoding or the text is compatible with both GBK and UTF-8
It is estimated that the default encoding of your system is gbk, you can try it
Are you running it using Windows console? Because the default encoding of the console is gbk.
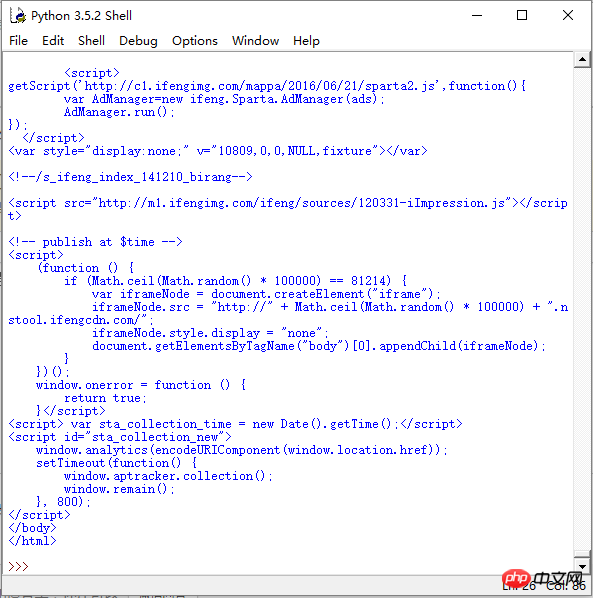
There is no problem if you use the interpreter that comes with python:
or use other tools instead of using the console.
# _*_ coding: utf-8 _*_Specify file encoding
Declare the encoding of your program.