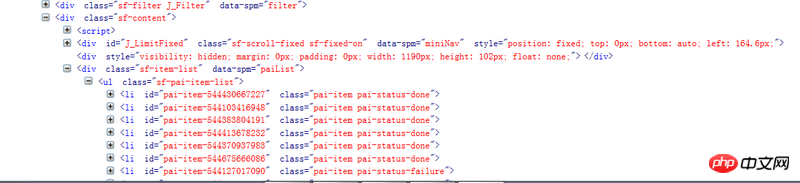
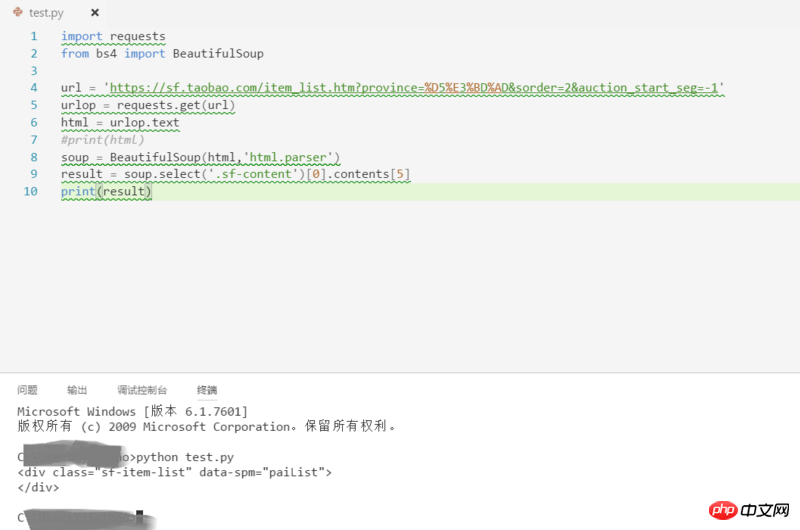
Tips, if you use Chrome F12 to view it, there will be dynamically loaded content, and you cannot get this content by directly requesting the URL of the page. It is recommended that you right-click to view the source code of the web page and compare it with the content in F12. If there is no content in the source code, check other requests in the Network to see if there is any data you need.
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Have you never considered dynamic loading with javascript?
Tips, if you use Chrome F12 to view it, there will be dynamically loaded content, and you cannot get this content by directly requesting the URL of the page. It is recommended that you right-click to view the source code of the web page and compare it with the content in F12. If there is no content in the source code, check other requests in the Network to see if there is any data you need.