The queue to be crawled cannot be shared, and distribution is nonsense. scrapy-redis提供了一个解决方法,把collection.deque换成redis数据库,多个爬虫从同一个redis服务器存放要爬取的request,这样就能让多个spiderRead in the same database, so that the main problem of distribution is solved.
Note: It does not mean that it will be distributed directly by changing redis来存放request,scrapy!
scrapy中跟待爬队列直接相关的就是调度器Scheduler.
Referencescrapy structure
It is responsible for new request进行入列操作,取出下一个要爬取的request and other operations. Therefore, after replacing redis, other components must be changed.
So, my personal understanding is to deploy the same crawler on multiple machines, distributed deploymentredis,参考地址 我的博客,比较简单。而这些工作,包括url去重,就是已经写好的scrapy-redisfunction of the framework.
The reference address is here, you can download the example to see the specific implementation. I've been working on this recentlyscrapy-redis, and I'll update this answer after I deploy it.
If you have new progress, you can share it and communicate.
@伟兴 Hello, I saw this comment on 15.10.11. Do you have any results now? Can you recommend some of your blogs? Thank you~ You can contact me at chenjian158978@gmail.com
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




I feel like this cannot be described clearly in one or two sentences.
This blog post I referred to before, I hope it will be helpful to you.
Let me talk about my personal understanding.
What aboutscrapy使用改良之后的python自带的collection.deque来存放待爬取的request,该怎么让两个以上的Spider共用这个deque?The queue to be crawled cannot be shared, and distribution is nonsense.
scrapy-redis提供了一个解决方法,把collection.deque换成redis数据库,多个爬虫从同一个redis服务器存放要爬取的request,这样就能让多个spiderRead in the same database, so that the main problem of distribution is solved.Note: It does not mean that it will be distributed directly by changing
redis来存放request,scrapy!scrapy中跟待爬队列直接相关的就是调度器Scheduler.Reference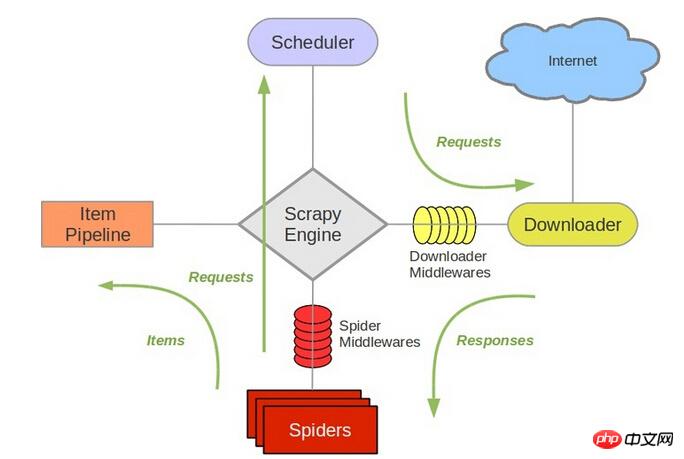
scrapystructureIt is responsible for new
request进行入列操作,取出下一个要爬取的requestand other operations. Therefore, after replacing redis, other components must be changed.So, my personal understanding is to deploy the same crawler on multiple machines, distributed deployment
redis,参考地址我的博客,比较简单。而这些工作,包括url去重,就是已经写好的
scrapy-redisfunction of the framework.The reference address is here, you can download the example to see the specific implementation. I've been working on this recently
scrapy-redis, and I'll update this answer after I deploy it.If you have new progress, you can share it and communicate.
@伟兴 Hello, I saw this comment on 15.10.11. Do you have any results now?
Can you recommend some of your blogs? Thank you~
You can contact me at chenjian158978@gmail.com