

hive分区(partition)简介

网上有篇关于hive的partition的使用讲解的比较好,转载了: 一、背景 1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。 2、分区表指的是在创建表时指定
网上有篇关于hive的partition的使用讲解的比较好,转载了:
一、背景
1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。
2、分区表指的是在创建表时指定的partition的分区空间。
3、如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by,详见表创建的语法结构。
二、技术细节
1、一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
2、表和列名不区分大小写。
3、分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
4、建表的语法(建分区可参见PARTITIONED BY参数):
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
5、分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
a、单分区建表语句:create table day_table (id int, content string) partitioned by (dt string);单分区表,按天分区,在表结构中存在id,content,dt三列。
b、双分区建表语句:create table day_hour_table (id int, content string) partitioned by (dt string, hour string);双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。
表文件夹目录示意图(多分区表):
6、添加分区表语法(表已创建,在此基础上添加分区):
ALTER TABLE table_name ADD partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ... partition_spec: : PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
用户可以用 ALTER TABLE ADD PARTITION 来向一个表中增加分区。当分区名是字符串时加引号。例:
ALTER TABLE day_table ADD PARTITION (dt='2008-08-08', hour='08') location '/path/pv1.txt' PARTITION (dt='2008-08-08', hour='09') location '/path/pv2.txt';
7、删除分区语法:
ALTER TABLE table_name DROP partition_spec, partition_spec,...
用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。例:
ALTER TABLE day_hour_table DROP PARTITION (dt='2008-08-08', hour='09');
8、数据加载进分区表中语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
例:
LOAD DATA INPATH '/user/pv.txt' INTO TABLE day_hour_table PARTITION(dt='2008-08- 08', hour='08'); LOAD DATA local INPATH '/user/hua/*' INTO TABLE day_hour partition(dt='2010-07- 07');
当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录,文件存放在该分区下。
9、基于分区的查询的语句:
SELECT day_table.* FROM day_table WHERE day_table.dt>= '2008-08-08';
10、查看分区语句:
hive> show partitions day_hour_table; OK dt=2008-08-08/hour=08 dt=2008-08-08/hour=09 dt=2008-08-09/hour=09
三、总结
1、在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在最字集的目录中。
2、总的说来partition就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
——————————————————————————————————————
hive中关于partition的操作:
hive> create table mp (a string) partitioned by (b string, c string);
OK
Time taken: 0.044 seconds
hive> alter table mp add partition (b='1', c='1');
OK
Time taken: 0.079 seconds
hive> alter table mp add partition (b='1', c='2');
OK
Time taken: 0.052 seconds
hive> alter table mp add partition (b='2', c='2');
OK
Time taken: 0.056 seconds
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=2/c=2
Time taken: 0.046 seconds
hive> explain extended alter table mp drop partition (b='1');
OK
ABSTRACT SYNTAX TREE:
(TOK_ALTERTABLE_DROPPARTS mp (TOK_PARTSPEC (TOK_PARTVAL b '1')))
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Drop Table Operator:
Drop Table
table: mp
Time taken: 0.048 seconds
hive> alter table mp drop partition (b='1');
FAILED: Error in metadata: table is partitioned but partition spec is not specified or tab: {b=1}
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=2/c=2
Time taken: 0.044 seconds
hive> alter table mp add partition ( b='1', c = '3') partition ( b='1' , c='4');
OK
Time taken: 0.168 seconds
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=1/c=3
b=1/c=4
b=2/c=2
b=2/c=3
Time taken: 0.066 seconds
hive>insert overwrite table mp partition (b='1', c='1') select cnt from tmp_et3 ;
hive>alter table mp add columns (newcol string);
location指定目录结构
hive> alter table alter2 add partition (insertdate='2008-01-01') location '2008/01/01';
hive> alter table alter2 add partition (insertdate='2008-01-02') location '2008/01/02';

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 【Linux系統】fdisk相關分區指令。
Feb 19, 2024 pm 06:00 PM
【Linux系統】fdisk相關分區指令。
Feb 19, 2024 pm 06:00 PM
fdisk是常用的Linux命令列工具,用於建立、管理和修改磁碟分割區。以下是一些常用的fdisk指令:顯示磁碟分割資訊:fdisk-l此指令將顯示系統中所有磁碟的分割區資訊。選擇要操作的磁碟:fdisk/dev/sdX將/dev/sdX替換為要操作的實際磁碟裝置名稱,如/dev/sda。建立新分割區:n這將引導您建立一個新的分割區。依照指示輸入分割區類型、起始磁區、大小等資訊。刪除分割區:d這將引導您選擇要刪除的分割區。依照提示選擇要刪除的分割區編號。修改分割區類型:t這將引導您選擇要修改類型的分割區。按照提
 win10安裝後無法分割的解決方法
Jan 02, 2024 am 09:17 AM
win10安裝後無法分割的解決方法
Jan 02, 2024 am 09:17 AM
我們再重裝win10作業系統的時候,到了磁碟分割的步驟卻發現出現系統提示無法建立新的分割區也找不到現有分割區。對於這種情況小編覺得可以嘗試將整個硬碟重新進行格式化再次安裝系統進行分割區,或透過軟體重新進行系統安裝等等。具體內容就來看看小編是怎麼做的吧~希望可以幫助到你。安裝win10無法建立新的分割區怎麼辦方法一:格式化整個硬碟重新分割區或嘗試插拔U盤幾次並刷新,如果你的硬碟上沒有重要資料的話,到了分割區這一步時,將硬碟上的所有分割區都刪除了。重新格式化整個硬碟,然後重新分割區,再進行安裝就正常了。方法二:P
 Python ORM 效能基準測試:比較不同 ORM 框架
Mar 18, 2024 am 09:10 AM
Python ORM 效能基準測試:比較不同 ORM 框架
Mar 18, 2024 am 09:10 AM
物件關聯映射(ORM)框架在python開發中扮演著至關重要的角色,它們透過在物件和關聯式資料庫之間建立橋樑,簡化了資料存取和管理。為了評估不同ORM框架的效能,本文將針對以下流行框架進行基準測試:sqlAlchemyPeeweeDjangoORMPonyORMTortoiseORM測試方法基準測試使用了一個包含100萬筆記錄的SQLite資料庫。測試對資料庫執行了以下操作:插入:向表中插入10,000條新記錄讀取:讀取表中的所有記錄更新:更新表中所有記錄的單一欄位刪除:刪除表中的所有記錄每個操作
 詳解Linux Opt分區的設定方法
Mar 20, 2024 am 11:30 AM
詳解Linux Opt分區的設定方法
Mar 20, 2024 am 11:30 AM
LinuxOpt分區的設定方法及程式碼範例在Linux系統中,Opt分割區通常用於儲存可選軟體包和應用程式資料。合理設定Opt分割區可以有效管理系統資源,避免磁碟空間不足等問題。本文將詳細介紹如何設定LinuxOpt分區,並提供具體的程式碼範例。 1.確定分割空間大小首先,我們要確定Opt分割區所需的空間大小。一般建議將Opt分區的大小設定為系統總空間的5%-1
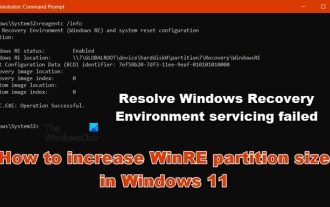 如何在Windows 11中增加WinRE分割區大小
Feb 19, 2024 pm 06:06 PM
如何在Windows 11中增加WinRE分割區大小
Feb 19, 2024 pm 06:06 PM
在這篇文章中,我們將向您展示如何在Windows11/10中變更或增加WinRE分割區大小。微軟現在將在每月累積更新的同時更新Windows復原環境(WinRE),開始於Windows11版本22H2。然而,並非所有電腦都有足夠大的恢復分區以容納新的更新,這可能導致錯誤訊息出現。 Windows復原環境服務失敗如何在Windows11中增加WinRE分割區大小要在您的電腦上手動增加WinRE分割區大小,請執行下面提到的步驟。檢查並停用WinRE縮小作業系統分區建立新的復原分區確認分區並啟用WinRE
 深度Linux硬碟分割區及安裝教學:一步步實現系統的高效部署
Feb 10, 2024 pm 07:06 PM
深度Linux硬碟分割區及安裝教學:一步步實現系統的高效部署
Feb 10, 2024 pm 07:06 PM
在進行深度Linux的安裝之前,我們需要對硬碟進行分區,硬碟分區是將一塊實體硬碟劃分為多個邏輯區域的過程,每個區域可以獨立使用和管理,正確的分區方式可以提高系統的效能和穩定性,因此這一步非常重要,本文將為您提供詳細的深度Linux硬碟分割區及安裝教學。準備工作1.確保您已經備份了重要的數據,因為分割過程會清除硬碟上的所有資料。 2.準備一個深度Linux的安裝媒介,例如USB或光碟。硬碟分區1.開機進入BIOS設置,將啟動媒介設定為首選啟動設備。 2.重啟計算機,從啟動媒介引導進入系統安裝介面。 3.選擇
 Win11怎麼分割區硬碟分割區? win11磁碟怎麼分割硬碟教學
Feb 19, 2024 pm 06:01 PM
Win11怎麼分割區硬碟分割區? win11磁碟怎麼分割硬碟教學
Feb 19, 2024 pm 06:01 PM
不少的用戶覺得系統預設的分區空間太小了,那麼Win11如何分區硬碟分區?使用者可以直接的點擊此電腦下的管理,然後點擊磁碟管理來進行操作設定就可以了。下面就讓本站來為用戶們來仔細的介紹一下win11磁碟怎麼分區硬碟教學吧。 win11磁碟怎麼分割硬碟教學1、先右鍵此電腦,開啟電腦管理。 3.然後查看右側磁碟狀況,是否有可用空間。 (如果有可用空間就跳到第6步)。 5、然後選擇需要騰出的空間量,點選壓縮。 7.再輸入想要的簡單磁碟大小,點選下一頁。 9.最後點擊完成就可以建立新的分區了。
 Python ORM 在大數據專案的應用
Mar 18, 2024 am 09:19 AM
Python ORM 在大數據專案的應用
Mar 18, 2024 am 09:19 AM
物件關係映射(ORM)是一種程式設計技術,允許開發人員使用物件程式語言來操作資料庫,而無需直接編寫sql查詢。 python中的ORM工具(例如SQLAlchemy、Peewee和DjangoORM)簡化了大數據專案的資料庫互動。優點程式碼簡潔性:ORM消除了編寫冗長的SQL查詢的需要,這提高了程式碼簡潔性和可讀性。資料抽象化:ORM提供了一個抽象層,將應用程式程式碼與資料庫實作細節隔離開來,提高了靈活性。效能最佳化:ORM通常會使用快取和批次操作來優化資料庫查詢,從而提高效能。可移植性:ORM允許開發人員在不
