

分库分表的排序

分库分表的排序 分库分表的排序 1. 对于单库,冗余一个汇总所有数据表,用于全部数据的排序,但是当数据量大,汇总表将会成为瓶颈。这不是一个很好的方案 2. 无论单库还是多个分库,都由程序读取需要数据并作排序。 排序的几种方式: 大都是按时间排序的,如
分库分表的排序
分库分表的排序
1. 对于单库,冗余一个汇总所有数据表,用于全部数据的排序,但是当数据量大,汇总表将会成为瓶颈。这不是一个很好的方案
2. 无论单库还是多个分库,都由程序读取需要数据并作排序。
排序的几种方式:
大都是按时间排序的,如果在客户端可以直接判断在哪个分表最好,可以直接读取指定分表并作排序
例如:
汇总表td_test_all;而分表是按companyid分表的
原始sql:
SELECT * FROM td_test_all
WHERE companyid = 15997
order by productid desc limit 0,20
程序端完全可以通过companyid判断在哪个分表读取数据,改为
SELECT * FROM td_test7
WHERE companyid = 15997
order by productid desc limit 0,20
这样数据的排序还是通过数据实现的。
如果where条件里没有分区字段的话,如何定位到具体分区呢?可以在设计阶段,在常用字段上埋下分区规则的种子, 比如在td_test7.groupid字段设计由int+7(7表示在分表td_test7里)
如果数据必须从多个分表取数据的话:
对于取top N条记录的话场景
程序分表读取每个分表的前N条记录(理想的认为数据都来源一个分表,从而减小结果集),如分区td_test0所示:
SELECT *
FROM td_test0
WHERE createtime> STR_TO_DATE('2013-04-28 15:34:02','%Y-%m-%d %H:%i:%s')
ORDER BY createtime DESC
LIMIT 0,5
然后程序读取这些结果集,在应用端汇总排序取top N记录
对于需要分页的话场景
这个就只能把每个分表、满足条件的的所有记录都load到应用端,然后在程序端很容易做汇总,排序分页操作
------end----

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



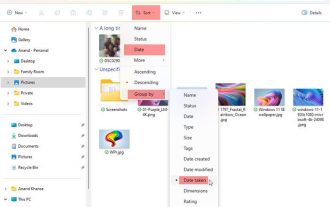 如何在Windows 11/10中按拍攝日期對照片進行排序
Feb 19, 2024 pm 08:45 PM
如何在Windows 11/10中按拍攝日期對照片進行排序
Feb 19, 2024 pm 08:45 PM
本文將介紹如何在Windows11/10中根據拍攝日期對圖片進行排序,同時探討如果Windows未按日期排序圖片應該如何處理。在Windows系統中,合理整理照片對於方便尋找影像檔案至關重要。使用者可以根據不同的排序方式(如日期、大小和名稱)來管理包含照片的資料夾。此外,還可以根據需要設定升序或降序排列,以便更靈活地組織文件。如何在Windows11/10中按拍攝日期對照片進行排序要按在Windows中拍攝的日期對照片進行排序,請執行以下步驟:打開圖片、桌面或放置照片的任何資料夾在功能區選單中,單
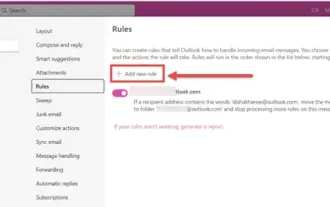 如何在Outlook中按寄件者、主題、日期、類別、大小對電子郵件進行排序
Feb 19, 2024 am 10:48 AM
如何在Outlook中按寄件者、主題、日期、類別、大小對電子郵件進行排序
Feb 19, 2024 am 10:48 AM
Outlook提供了許多設定和功能,可協助您更有效地管理工作。其中之一是排序選項,可讓您根據需要對電子郵件進行分類。在這個教學中,我們將學習如何利用Outlook的排序功能,根據寄件者、主題、日期、類別或大小等條件對電子郵件進行整理。這將讓您更輕鬆地處理和查找重要訊息,提高工作效率。 MicrosoftOutlook是一個功能強大的應用程序,可以輕鬆地集中管理您的電子郵件和日曆安排。您可以輕鬆地發送、接收和組織電子郵件,而內建的日曆功能也讓您能夠輕鬆追蹤您即將面臨的活動和約會。如何在Outloo
 PHP開發:如何實作表格資料排序與分頁功能
Sep 20, 2023 am 11:28 AM
PHP開發:如何實作表格資料排序與分頁功能
Sep 20, 2023 am 11:28 AM
PHP開發:如何實現表格資料排序和分頁功能在進行Web開發中,處理大量資料是一項常見的任務。對於需要展示大量資料的表格,通常需要實現資料排序和分頁功能,以提供良好的使用者體驗和最佳化系統效能。本文將介紹如何使用PHP實作表格資料的排序和分頁功能,並給出具體的程式碼範例。排序功能實作在表格中實作排序功能,可以讓使用者根據不同的欄位進行升序或降序排序。以下是一個實作表格
 使用Python實現XML資料的篩選和排序
Aug 07, 2023 pm 04:17 PM
使用Python實現XML資料的篩選和排序
Aug 07, 2023 pm 04:17 PM
使用Python實現XML資料的篩選和排序引言:XML是一種常用的資料交換格式,它以標籤和屬性的形式儲存資料。在處理XML資料時,我們經常需要對資料進行篩選和排序。 Python提供了許多有用的工具和函式庫來處理XML數據,本文將介紹如何使用Python實現XML資料的篩選和排序。讀取XML檔案在開始之前,我們需要先讀取XML檔案。 Python有許多XML處理函式庫,
 C++程式:按字母順序重新排列單字的位置
Sep 01, 2023 pm 11:37 PM
C++程式:按字母順序重新排列單字的位置
Sep 01, 2023 pm 11:37 PM
在這個問題中,一個字串被當作輸入,我們必須按字典順序對字串中出現的單字進行排序。為此,我們為字串中的每個單字(之間用空格區分)分配一個從1開始的索引,並以排序索引的形式獲得輸出。 String={“Hello”,“World”}“Hello”=1“World”=2由於輸入字串中的單字已按字典順序排列,因此輸出將列印為“12”。讓我們看看一些輸入/結果場景-假設輸入字串中的所有單字都相同,讓我們看看結果-Input:{“hello”,“hello”,“hello”}Result:3獲得的結
 Java中的Arrays.sort()方法如何依照自訂比較器對陣列進行排序?
Nov 18, 2023 am 11:36 AM
Java中的Arrays.sort()方法如何依照自訂比較器對陣列進行排序?
Nov 18, 2023 am 11:36 AM
Java中的Arrays.sort()方法如何依照自訂比較器對陣列進行排序?在Java中,Arrays.sort()方法是一個非常有用的方法,可以對陣列進行排序。預設情況下,方法會依照升序排序。但是有時候,我們需要依照自己定義的規則來對陣列進行排序。這時,就需要用到自訂比較器(Comparator)。自訂比較器是一個實作了Comparator介面的類,
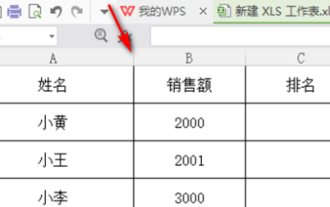 wps怎麼排序成績高低
Mar 20, 2024 am 11:28 AM
wps怎麼排序成績高低
Mar 20, 2024 am 11:28 AM
在我們的工作中,常常會用到wps軟體,wps軟體處理資料的方式方法是非常多的,而且函數功能也是非常強大的,我們常用函數來求平均值,求總和等,可以說只要是統計數據能用的方法,wps軟體庫裡都已經為大家準備好了,下面我們要介紹的是wps怎麼排序成績高低的操作步驟,看完以後大家可以藉鑑經驗。 1.先開啟需要排名的表格。如下圖所示。 2、然後輸入公式=rank(B2,B2:B5,0),一定要輸入0。如下圖所示。 3、輸入完公式以後,按下電腦鍵盤上的F4鍵,這一步驟操作是為了讓相對引用變成絕對引用。
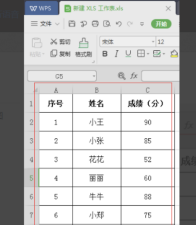 WPS表格怎麼排序方便資料統計
Mar 20, 2024 pm 04:31 PM
WPS表格怎麼排序方便資料統計
Mar 20, 2024 pm 04:31 PM
WPS是一款功能非常完善的辦公室軟體,其中包含文字編輯、資料表、PPT簡報、PDF格式、流程圖等功能。其中我們使用最多的就是文字、表格、演示,也是我們最熟悉的。我們在學習工作中,有時會使用WPS表格製作一些數據統計,例如學校裡會對每個學生的成績進行統計,那麼多的學生如果我們要透過手動進行學生成績排序的話,那真是讓人頭疼,其實我們可以不必煩心,因為我們的WPS表格中有排序這個功能為我們解決這個問題。接下來我們就一起學習WPS怎麼排序的方法。方法步驟:第一步:首先我們要開啟需要排序的WPS表格
