

【OpenCV2.4】SVM处理线性不可分的例子

【原文:http://www.cnblogs.com/justany/archive/2012/11/26/2788509.html】 目的 实际事物模型中,并非所有东西都是线性可分的。 需要寻找一种方法对线性不可分数据进行划分。 原理 ,我们推导出对于线性可分数据,最佳划分超平面应满足: 现在我们想引入
【原文:http://www.cnblogs.com/justany/archive/2012/11/26/2788509.html】
目的
- 实际事物模型中,并非所有东西都是线性可分的。
- 需要寻找一种方法对线性不可分数据进行划分。
原理
,我们推导出对于线性可分数据,最佳划分超平面应满足:

现在我们想引入一些东西,来表示那些被错分的数据点(比如噪点),对划分的影响。
如何来表示这些影响呢?
被错分的点,离自己应当存在的区域越远,就代表了,这个点“错”得越严重。
所以我们引入 ,为对应样本离同类区域的距离。
,为对应样本离同类区域的距离。

接下来的问题是,如何将这种错的程度,转换为和原模型相同的度量呢?
我们再引入一个常量C,表示和原模型度量的转换关系,用C对进行加权和,来表征错分点对原模型的影响,这样我们得到新的最优化问题模型:

关于参数C的选择, 明显的取决于训练样本的分布情况。 尽管并不存在一个普遍的答案,但是记住下面几点规则还是有用的:
- C比较大时分类错误率较小,但是间隔也较小。 在这种情形下, 错分类对模型函数产生较大的影响,既然优化的目的是为了最小化这个模型函数,那么错分类的情形必然会受到抑制。
- C比较小时间隔较大,但是分类错误率也较大。 在这种情形下,模型函数中错分类之和这一项对优化过程的影响变小,优化过程将更加关注于寻找到一个能产生较大间隔的超平面。
说白了,C的大小表征了,错分数据对原模型的影响程度。于是C越大,优化时越关注错分问题。反之越关注能否产生一个较大间隔的超平面。
开始使用

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
|
设置SVM参数
这里的参数设置可以参考一下的API。
1
2
3
4
5
<span>CvSVMParams</span> <span>params</span><span>;</span>
<span>params</span><span>.</span><span>svm_type</span> <span>=</span> <span>SVM</span><span>::</span><span>C_SVC</span><span>;</span>
<span>params</span><span>.</span><span>C</span> <span>=</span> <span>0.1</span><span>;</span>
<span>params</span><span>.</span><span>kernel_type</span> <span>=</span> <span>SVM</span><span>::</span><span>LINEAR</span><span>;</span>
<span>params</span><span>.</span><span>term_crit</span> <span>=</span> <span>TermCriteria</span><span>(</span><span>CV_TERMCRIT_ITER</span><span>,</span> <span>(</span><span>int</span><span>)</span><span>1e7</span><span>,</span> <span>1e-6</span><span>);</span>登入後複製
可以看到,这次使用的是C类支持向量分类机。其参数C的值为0.1。
结果
- 程序创建了一张图像,在其中显示了训练样本,其中一个类显示为浅绿色圆圈,另一个类显示为浅蓝色圆圈。
- 训练得到SVM,并将图像的每一个像素分类。 分类的结果将图像分为蓝绿两部分,中间线就是最优分割超平面。由于样本非线性可分, 自然就有一些被错分类的样本。 一些绿色点被划分到蓝色区域, 一些蓝色点被划分到绿色区域。
- 最后支持向量通过灰色边框加重显示。

被山寨的原文
Support Vector Machines for Non-Linearly Separable Data . OpenCV.org

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!
熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 WIN10服務主機太佔cpu的處理操作過程
Mar 27, 2024 pm 02:41 PM
WIN10服務主機太佔cpu的處理操作過程
Mar 27, 2024 pm 02:41 PM
1.首先我們右鍵點選任務列空白處,選擇【任務管理器】選項,或右鍵開始徽標,然後再選擇【任務管理器】選項。 2.在開啟的任務管理器介面,我們點選最右邊的【服務】選項卡。 3.在開啟的【服務】選項卡,點選下方的【開啟服務】選項。 4.在開啟的【服務】窗口,右鍵點選【InternetConnectionSharing(ICS)】服務,然後選擇【屬性】選項。 5.在開啟的屬性窗口,將【開啟方式】修改為【禁用】,點選【應用程式】後點選【確定】。 6.點選開始徽標,然後點選關機按鈕,選擇【重啟】,完成電腦重啟就行了。
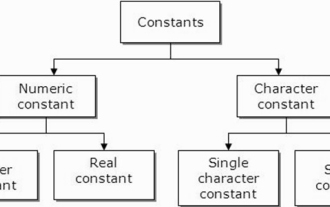 C語言中的常數是什麼,可以舉例嗎?
Aug 28, 2023 pm 10:45 PM
C語言中的常數是什麼,可以舉例嗎?
Aug 28, 2023 pm 10:45 PM
常量也稱為變量,一旦定義,其值在程式執行期間就不會改變。因此,我們可以將變數宣告為引用固定值的常數。它也被稱為文字。必須使用Const關鍵字來定義常數。語法C程式語言中使用的常數語法如下-consttypeVariableName;(or)consttype*VariableName;不同類型的常數在C程式語言中使用的不同類型的常數如下所示:整數常數-例如:1,0,34, 4567浮點數常數-例如:0.0,156.89,23.456八進制和十六進制常數-例如:十六進制:0x2a,0xaa..八進制
 Excel資料匯入Mysql常見問題總表:如何處理匯入資料時遇到的錯誤日誌問題?
Sep 10, 2023 pm 02:21 PM
Excel資料匯入Mysql常見問題總表:如何處理匯入資料時遇到的錯誤日誌問題?
Sep 10, 2023 pm 02:21 PM
Excel資料匯入Mysql常見問題總表:如何處理匯入資料時遇到的錯誤日誌問題?導入Excel資料到MySQL資料庫是一項常見的任務。然而,在這個過程中,我們經常會遇到各種錯誤和問題。其中之一就是錯誤日誌問題。當我們嘗試匯入資料時,系統可能會產生一個錯誤日誌,列出了發生錯誤的具體資訊。那麼,當我們遇到這種情況時,我們應該如何處理錯誤日誌呢?首先,我們需要知道如何
 CSV檔案操作速成指南
Dec 26, 2023 pm 02:23 PM
CSV檔案操作速成指南
Dec 26, 2023 pm 02:23 PM
快速學會開啟和處理CSV格式檔案的方法指南隨著資料分析和處理的不斷發展,CSV格式成為了廣泛使用的檔案格式之一。 CSV文件是一種簡單且易於閱讀的文字文件,其以逗號分隔不同的資料欄位。無論是在學術研究、商業分析或資料處理方面,都經常會遇到需要開啟和處理CSV檔案的情況。以下的指南將向您介紹如何快速學會開啟和處理CSV格式檔案。步驟一:了解CSV檔案格式首先,
 學習PHP中如何處理特殊字元轉換單引號
Mar 27, 2024 pm 12:39 PM
學習PHP中如何處理特殊字元轉換單引號
Mar 27, 2024 pm 12:39 PM
在PHP開發過程中,處理特殊字元是常見的問題,尤其是在字串處理中經常會遇到特殊字元轉義的情況。其中,將特殊字元轉換單引號是比較常見的需求,因為在PHP中,單引號是一種常用的字串包裹方式。在本文中,我們將介紹如何在PHP中處理特殊字元轉換單引號,並提供具體的程式碼範例。在PHP中,特殊字元包括但不限於單引號(')、雙引號(")、反斜線()等。在字串
 如何處理Java中的java.lang.UnsatisfiedLinkError錯誤?
Aug 24, 2023 am 11:01 AM
如何處理Java中的java.lang.UnsatisfiedLinkError錯誤?
Aug 24, 2023 am 11:01 AM
Java.lang.UnsatisfiedLinkError異常在執行時發生,當嘗試存取或載入本機方法或函式庫時,由於其架構、作業系統或函式庫路徑配置與引用的不符而失敗。它通常表示存在與架構、作業系統配置或路徑配置不相容的問題,導致無法成功-通常引用的本地庫與系統上安裝的庫不匹配,並且在運行時不可用要克服這個錯誤,關鍵是原生庫與您的系統相容並且可以透過其庫路徑設定進行存取。應該驗證庫文件是否存在於其指定位置,並滿足系統要求。 java.lang.UnsatisfiedLinkErrorjava.lang
 win7升級至win10失敗後,如何解決?
Dec 26, 2023 pm 07:49 PM
win7升級至win10失敗後,如何解決?
Dec 26, 2023 pm 07:49 PM
如果我們使用的作業系統是win7的話,對於升級的時候有的小夥伴們可能就會出現win7升win10失敗的情況。小編覺得我們可以嘗試重新升級看下能不能解決。詳細內容就來看下小編是怎麼做的吧~win7升win10失敗怎麼辦方法一:1.建議下載個驅動人生先評估下你電腦是否可以升級到Win10,2.然後升級後用驅動人生檢測下有沒有驅動異常這些,然後一鍵修復。方法二:1.刪除C:\Windows\SoftwareDistribution\Download下的所有檔案。 2.win+R運行“wuauclt.e
 如何在PHP專案中透過呼叫API介面來實現資料的爬取與處理?
Sep 05, 2023 am 08:41 AM
如何在PHP專案中透過呼叫API介面來實現資料的爬取與處理?
Sep 05, 2023 am 08:41 AM
如何在PHP專案中透過呼叫API介面來實現資料的爬取與處理?一、介紹在PHP專案中,我們經常需要爬取其他網站的數據,並對這些數據進行處理。而許多網站提供了API接口,我們可以透過呼叫這些接口來取得資料。本文將介紹如何使用PHP來呼叫API接口,實現資料的爬取與處理。二、取得API介面的URL和參數在開始之前,我們需要先取得目標API介面的URL以及所需的
