

Hadoop配置文件与HBase配置文件

本Hadoop与HBase集群有1台NameNode, 7台DataNode 1. /etc/hostname文件 NameNode: node1 DataNode 1: node2 DataNode 2: node3 ....... DataNode 7: node8 2. /etc/hosts文件 NameNode: 127.0.0.1localhost#127.0.1.1node1#-------edit by HY(2014-05-04)---
本Hadoop与HBase集群有1台NameNode, 7台DataNode
1. /etc/hostname文件
NameNode:
node1
DataNode 1:
node2
DataNode 2:
node3.......
DataNode 7:
node8
2. /etc/hosts文件
NameNode:
127.0.0.1 localhost #127.0.1.1 node1 #-------edit by HY(2014-05-04)-------- #127.0.1.1 node1 125.216.241.113 node1 125.216.241.112 node2 125.216.241.96 node3 125.216.241.111 node4 125.216.241.114 node5 125.216.241.115 node6 125.216.241.116 node7 125.216.241.117 node8 #-------end edit-------- # The following lines are desirable for IPv6 capable hosts ::1 ip6-localhost ip6-loopback fe00::0 ip6-localnet ff00::0 ip6-mcastprefix ff02::1 ip6-allnodes ff02::2 ip6-allrouters
127.0.0.1 localhost #127.0.0.1 node2 #127.0.1.1 node2 #--------eidt by HY(2014-05-04)-------- 125.216.241.113 node1 125.216.241.112 node2 125.216.241.96 node3 125.216.241.111 node4 125.216.241.114 node5 125.216.241.115 node6 125.216.241.116 node7 125.216.241.117 node8 #-------end eidt--------- # The following lines are desirable for IPv6 capable hosts ::1 ip6-localhost ip6-loopback fe00::0 ip6-localnet ff00::0 ip6-mcastprefix ff02::1 ip6-allnodes ff02::2 ip6-allrouters
其他的DataNode类似,只是注意要保持hostname与hosts中的域名要一样, 如果不一样, 在集群上跑任务时会出一些莫名奇妙的问题, 具体什么问题忘记了.
3. 在hadoop-env.sh中注释
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
增加
JAVA_HOME=/usr/lib/jvm/java-6-sun
4. core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:49000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/newdata/hadoop-1.2.1/tmp</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>dfs.datanode.socket.write.timeout</name>
<value>3000000</value>
</property>
<property>
<name>dfs.socket.timeout</name>
<value>3000000</value>
</property>
</configuration><?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.name.dir</name> <value>/home/hadoop/newdata/hadoop-1.2.1/name1,/home/hadoop/newdata/hadoop-1.2.1/name2</value> <description>数据元信息存储位置</description> </property> <property> <name>dfs.data.dir</name> <value>/home/hadoop/newdata/hadoop-1.2.1/data1,/home/hadoop/newdata/hadoop-1.2.1/data2</value> <description>数据块存储位置</description> </property> <property> <name>dfs.replication</name> <!-- 这里备份两份 --> <value>2</value> </property> </configuration>
6. mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>node1:49001</value> </property> <property> <name>mapred.local.dir</name> <value>/home/hadoop/newdata/hadoop-1.2.1/tmp</value> </property> <property> <name>mapred.compress.map.output</name> <value>true</value> <!-- map 和 reduce 输出中间文件默认开启压缩 --> </property> <property> <name>mapred.map.output.compression.codec</name> <value>com.hadoop.compression.lzo.LzoCodec</value> <!-- 使用 Lzo 库作为压缩算法 --> </property> </configuration>
7. masters
node1
8. slaves
node2 node3 node4 node5 node6 node7 node8
9. 在hbase-env.sh
增加
JAVA_HOME=/usr/lib/jvm/java-6-sun
并启用export HBASE_MANAGES_ZK=true //为true表示使用自带的Zookeeper, 如果需要独立的Zookeeper,则设置为false, 并且安装Zookeeper
10. hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:49000/hbase</value>
<description>The directory shared by RegionServers.</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed Zookeeper
true: fully-distributed with unmanaged Zookeeper Quorum (see hbase-env.sh)
</description>
</property>
<property>
<name>hbase.master</name>
<value>node1:60000</value>
<description>
</description>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadoop/newdata/hbase/tmp</value>
<description>
Temporary directory on the local filesystem.
Change this setting to point to a location more permanent than '/tmp',
the usual resolve for java.io.tmpdir,
as the '/tmp' directory is cleared on machine restart.
Default: ${java.io.tmpdir}/hbase-${user.name}
</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node2,node3,node4,node5,node6,node7,node8</value>
<description>
要单数台,Comma separated list of servers in the ZooKeeper ensemble (This config.
should have been named hbase.zookeeper.ensemble).
For example, "host1.mydomain.com,host2.mydomain.com,host3.mydomain.com".
By default this is set to localhost for local and pseudo-distributed
modes of operation.
For a fully-distributed setup,
this should be set to a full list of ZooKeeper ensemble servers.
If HBASE_MANAGES_ZK is set in hbase-env.sh this is the list of servers
which hbase will start/stop ZooKeeper on as part of cluster start/stop.
Client-side, we will take this list of ensemble members and put it
together with the hbase.zookeeper.clientPort config.
and pass it into zookeeper constructor as the connectString parameter.
Default: localhost
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/newdata/zookeeper</value>
<description>
Property from ZooKeeper's config zoo.cfg.
The directory where the snapshot is stored.
Default: ${hbase.tmp.dir}/zookeeper
</description>
</property>
<property>
<name></name>
<value></value>
</property>
</configuration>11. regionservers
node2 node3 node4 node5 node6 node7 node8
每台机器配置都要一样

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



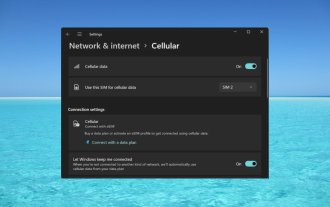 如何在 Windows 11 上啟用或停用 eSIM
Sep 20, 2023 pm 05:17 PM
如何在 Windows 11 上啟用或停用 eSIM
Sep 20, 2023 pm 05:17 PM
如果你從行動電信商購買了筆記型電腦,則很可能可以選擇啟動eSIM並使用手機網路將電腦連接到網路。有了eSIM,您無需將另一張實體SIM卡插入筆記型電腦,因為它已經內建。當您的裝置無法連接到網路時,它非常有用。如何檢查我的Windows11裝置是否相容於eSIM卡?點擊“開始”按鈕,然後轉到“網路和互聯網”>“蜂窩>設定”。如果您沒有看到「蜂窩行動網路」選項,則您的裝置沒有eSIM功能,您應該選取其他選項,例如使用行動裝置將筆記型電腦連接到熱點。為了激活和
 超全! Python中常見的設定檔寫法
Apr 11, 2023 pm 10:22 PM
超全! Python中常見的設定檔寫法
Apr 11, 2023 pm 10:22 PM
為什麼要寫設定檔這個固定檔我們可以直接寫成一個.py 文件,例如settings.py 或config.py,這樣的好處就是能夠在同一工程下直接透過import 來導入當中的部分;但如果我們需要在其他非Python 的平台進行設定檔共用時,寫成單一.py 就不是一個很好的選擇。這時我們就應該選擇通用的設定檔類型來作為儲存這些固定的部分。目前常用且流行的設定檔格式類型主要有 ini、json、toml、yaml、xml 等,這些類型的設定檔我們都可以透過標準函式庫或第三方函式庫來進
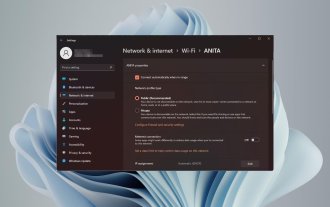 如何在 Windows 11 中變更網路類型為專用或公用
Aug 24, 2023 pm 12:37 PM
如何在 Windows 11 中變更網路類型為專用或公用
Aug 24, 2023 pm 12:37 PM
設定無線網路很常見,但選擇或變更網路類型可能會令人困惑,尤其是在您不知道後果的情況下。如果您正在尋找有關如何在Windows11中將網路類型從公用變更為私有或反之亦然的建議,請繼續閱讀以取得一些有用的資訊。 Windows11中有哪些不同的網路設定檔? Windows11附帶了許多網路設定文件,這些設定檔本質上是可用於配置各種網路連線的設定集。如果您在家中或辦公室有多個連接,這將非常有用,因此您不必每次連接到新網路時都進行所有設定。專用和公用網路設定檔是Windows11中的兩種常見類型,但通
 Java錯誤:Hadoop錯誤,如何處理與避免
Jun 24, 2023 pm 01:06 PM
Java錯誤:Hadoop錯誤,如何處理與避免
Jun 24, 2023 pm 01:06 PM
Java錯誤:Hadoop錯誤,如何處理和避免使用Hadoop處理大數據時,常常會遇到一些Java異常錯誤,這些錯誤可能會影響任務的執行,導致資料處理失敗。本文將介紹一些常見的Hadoop錯誤,並提供處理和避免這些錯誤的方法。 Java.lang.OutOfMemoryErrorOutOfMemoryError是Java虛擬機器記憶體不足的錯誤。當Hadoop任
 win10使用者設定檔在哪? Win10設定使用者設定檔的方法
Jun 25, 2024 pm 05:55 PM
win10使用者設定檔在哪? Win10設定使用者設定檔的方法
Jun 25, 2024 pm 05:55 PM
最近有不少Win10系統的使用者想要更改使用者設定文件,但不清楚具體如何操作,本文將為大家帶來Win10系統設定使用者設定檔的操作方法吧! Win10如何設定使用者設定檔1、首先,按下「Win+I」鍵開啟設定介面,並點選進入「系統」設定。 2、接著,在打開的介面中,點擊左側的“關於”,再找到並點擊其中的“高級系統設定”。 3、然後,在彈出的視窗中,切換到「」選項欄,並點擊下方「用戶配
 超全! Python 中常見的設定檔寫法
Apr 13, 2023 am 08:31 AM
超全! Python 中常見的設定檔寫法
Apr 13, 2023 am 08:31 AM
為什麼要寫設定檔在開發過程中,我們常常會用到一些固定參數或是常數。對於這些較為固定且常用到的部分,往往會將其寫到一個固定檔案中,避免在不同的模組程式碼中重複出現從而保持核心程式碼整潔。這個固定文件我們可以直接寫成一個.py 文件,例如settings.py 或config.py,這樣的好處就是能夠在同一工程下直接透過import 來導入當中的部分;但如果我們需要在其他非Python 的平台進行設定檔共享時,寫成單一.py 就不是一個很好的選擇。這時我們就應該選擇通用的設定檔類型來
 有效的解決eclipse編輯器中亂碼問題的方法
Jan 04, 2024 pm 06:56 PM
有效的解決eclipse編輯器中亂碼問題的方法
Jan 04, 2024 pm 06:56 PM
解決eclipse亂碼問題的有效方法,需要具體程式碼範例近年來,隨著軟體開發的飛速發展,eclipse作為最受歡迎的整合開發環境之一,為眾多開發者提供了便利和高效。然而,使用eclipse時可能會遇到亂碼問題,這對於專案開發和程式碼閱讀帶來了困擾。本文將介紹一些解決eclipse亂碼問題的有效方法,並提供具體程式碼範例。修改eclipse檔案編碼設定:在eclip
 在Ubuntu上安裝Helm
Mar 20, 2024 pm 06:41 PM
在Ubuntu上安裝Helm
Mar 20, 2024 pm 06:41 PM
Helm是Kubernetes的一個重要元件,它透過將設定檔捆綁到一個稱為HelmChart的套件中來簡化Kubernetes應用程式的部署。這種方法使得更新單一設定檔比修改多個檔案更便捷。借助Helm,使用者可以輕鬆部署Kubernetes應用程序,簡化了整個部署過程,提高了效率。在本指南中,我將介紹在Ubuntu上實作Helm的不同方法。請注意:以下指南中的命令適用於Ubuntu22.04以及所有Ubuntu版本和基於Debian的發行版。這些命令經過測試,應該會在您的系統上正常運作。在U
