

MongoDB入门学习(四):MongoDB的索引

上一篇讲到了MongoDB的基本操作增删查改,对于查询来说,必须按照我们的查询要求去集合中,并将查找到的结果返回,在这个过程中其实是对整个集合中每个文档进行了扫描,如果满足我们的要求就添加到结果集中最后返回。对于小集合来说,这个过程没什么,但是集
上一篇讲到了MongoDB的基本操作增删查改,对于查询来说,必须按照我们的查询要求去集合中,并将查找到的结果返回,在这个过程中其实是对整个集合中每个文档进行了扫描,如果满足我们的要求就添加到结果集中最后返回。对于小集合来说,这个过程没什么,但是集合中数据很大的时候,进行表扫描是一个非常恐怖的事情,于是有了索引一说,索引是用来加速查询的,相当于书籍的目录,有了目录可以很精准的定位要查找内容的位置,从而减少无谓的查找。
1.索引的类型
创建索引可以是在单个字段上,也可以是在多个字段上,这个根据自己的实际情况来选择,创建索引时字段的顺序也是有讲究的。创建索引是通过ensureIndex()方法,需要给该方法传递一个文档形式的数据,其中指定索引的字段和顺序,1代表升序,-1代表降序。
1).默认索引
还记得"_id"吗,这个字段的数据是不能重复的,它就是MongoDB的默认索引,而且不能被删除。
2).单列索引
在单个字段上创建的索引就是单列索引,在查询的过程中可以对该加速对该键的查询,然而对其他键的查询是没有帮助的。单列索引的顺序是不会影响对该键的随即查询,创建单列索引:
> db.people.ensureIndex({"name" : 1})3).组合索引
还可以在多个键上创建组合索引,此时键的位置和索引的顺序都会影响查询的效率,看下面创建组合索引:
> db.people.ensureIndex({"name" : 1, "age" : 1})
> db.people.ensureIndex({"age" : 1, "name" : 1})第一种情况会对name排序组织,当name一样时在对age排序,所以对{"name" : 1}和{“name” : 1, "age" : 1}的查询更高效,而第二种情况则对age排序,当age一样再对name排序,所以对{"age" : 1}和{"age" : 1, "name" : 1}的查询更高效。当组合索引包含很多字段的时候,会对前几个键的查询有帮助。
4).内嵌文档索引
还可以对内嵌文档创建索引,和普通键创建索引一样差不多,也可以对内嵌文档创建组合索引:
> db.people.ensureIndex({"friends.name" : 1})
> db.people.ensureIndex({"friends.name" : 1, "friends.age" : 1})在来看看其他几种形式的索引:
唯一索引
> db.people.ensureIndex({"name" : 1}, {"unique" : true})
> db.people.ensureIndex({"name" : 1}, {"unique" : true, "dropDups" : true})
松散索引
> db.people.ensureIndex({"name" : 1}, {"sparse" : true})
多值索引
> db.people.find()
{"name" : ["mary", "rose"]}
> db.people.ensureIndex({"name" : 1})唯一索引unique可以保证该键对应的值在集合中是唯一的,如果创建唯一索引的时候,该字段原来就存在了重复的数据,那么就会创建失败,可以加上dropDups字段来消除重复数据,它会保留发现的第一个文档,其他有重复数据的文档都将被删除。
集合中有的文档不存在某些字段,或者某些字段的值为null,那么我们在该字段上创建索引的时候不希望让这些空值的文档参与,那么就定义为松散索引sparse,比如在name上创建索引时,发现有的人在数据库中只有学号,没有名字,那么我们不希望把它们也包含进来,此时就定义为松散索引。
一个键对应的值是一个数组,在该键上创建索引时是一个多值索引,会为数组中每个值生成一个索引元素,相当于分裂成了几个独立的索引项,但是它们还是对应同一个文档数据。
2.索引的管理
索引固然是为查询而生,而且可以为每个键都创建索引,但是索引是需要存储空间的,所以索引不是越多越好,而且创建索引后,每次的插入,更新和删除文档都会产生额外的开销,因为数据库中不但要执行这些操作,而且还要在集合索引中标记这些操作。所以要根据实际情况来创建索引,索引没用之后将其删除。
创建索引是ensureIndex()方法,创建完成后可以通过getIndexes()来查看集合中创建的索引情况:
> db.people.ensureIndex({"name" : 1, "age" : 1})
> db.people.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "test.people",
"name" : "_id_"
},
{
"v" : 1,
"key" : {
"name" : 1,
"age" : 1
},
"ns" : "test.people",
"name" : "name_1_age_1"
}
]可以看到people集合创建了两个索引,一个是"_id",这个是默认索引,另外一个是name和age的组合索引,名字为keyname1_dir_keyname2_dir_...,keyname代表索引的键,dir代表方向,1代表升序,-1代表降序。当然我们也可以自定义索引的名称:
> db.people.ensureIndex({"name" : 1, "age" : 1}, {"name" : "myIndex"})
> db.people.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "test.people",
"name" : "_id_"
},
{
"v" : 1,
"key" : {
"name" : 1,
"age" : 1
},
"ns" : "test.people",
"name" : "myIndex"
}
]删除索引是通过dropIndex():
方式一:
> db.people.dropIndex({"name" : 1, "age" : 1})
{ "nIndexesWas" : 2, "ok" : 1 }
方式二:
> db.runCommand({"dropIndexes" : "people", "index" : "myIndex"})
{ "nIndexesWas" : 2, "ok" : 1 }索引的元信息存储在每个数据库的system.indexes集合中,不能对其进行插入和删除文档的操作,只能通过ensureIndex和dropIndex进行。
> db.system.indexes.find()
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.people", "name" : "_id_" }
{ "v" : 1, "key" : { "name" : 1, "age" : 1 }, "ns" : "test.people", "name" : "myIndex" }清空集合中所有的文档是不会将索引删除的,原来创建的索引依然存在,但是直接删除集合的话,该集合的索引也是会被删除的。
3.索引的效率
如果我们定义了很多的索引,那么MongoDB会根据我们的查询选项重新排序,并智能的选择一个最优的来使用,比如我们创建了{"name" : 1, "age" : 1}和{"age" : 1, "class" : 1}两个索引,但是我们的查询项为find({"age" : 10, "name" : "mary"}),那么MongoDB会自动重新排序为find({"name" : "mary", "age" : 10}),并且利用索引{"name" : 1, "age" : 1}来查询。
MongoDB提供了explain工具来帮助我们获得查询方面的很多有用信息,只要对游标调用这个方法就可以得到查询的细节。下面给math集合中添加10W个文档,再来看看使用索引前后的效率对比:
> var arr = [];
> for(var i = 0; i < 100000; i++){
... var doc = {};
... var value = Math.floor(Math.random() * 1000);
... doc["number"] = value;
... arr.push(doc);
... }
100000
> db.math.insert(arr)
> db.math.count()
100000
> db.math.find().limit(10)
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe5"), "number" : 462 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe6"), "number" : 123 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe7"), "number" : 90 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe8"), "number" : 46 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe9"), "number" : 244 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fea"), "number" : 972 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61feb"), "number" : 925 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fec"), "number" : 110 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fed"), "number" : 739 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fee"), "number" : 945 }通过for循环给arr数组中添加10W条数据,然后再批量插入这些数据到math集合中,查看前10条数据,因为是随即生成的值,所以number字段的值会有重复值,我们就来查询462这个值:
创建索引前:
> db.math.find({"number" : 462}).explain()
{
"cursor" : "BasicCursor",
"isMultiKey" : false,
"n" : 94,
"nscannedObjects" : 100000,
"nscanned" : 100000,
"nscannedObjectsAllPlans" : 100000,
"nscannedAllPlans" : 100000,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 35,
"indexBounds" : {
},
"server" : "server0.169:9352"
}
创建索引后:
> db.math.ensureIndex({"number" : 1})
> db.math.find({"number" : 462}).explain()
{
"cursor" : "BtreeCursor number_1",
"isMultiKey" : false,
"n" : 94,
"nscannedObjects" : 94,
"nscanned" : 94,
"nscannedObjectsAllPlans" : 94,
"nscannedAllPlans" : 94,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"number" : [
[
462,
462
]
]
},
"server" : "server0.169:9352"
}这里来看一下有用的信息,"cursor"指用的哪个索引,"nscanned"代表查找了多少个文档,"n"指返回文档的数量,"millis"表示查询所花时间,单位是毫秒。可以看出创建索引前没有使用索引,在全部的文档中查询的,花费了35毫秒,而创建索引后,使用了number_1索引查询,索引存储在B树结构中,只在94个文档中查询,几乎不花时间。
如果有很多索引的话,MongoDB会自动选一个来查询,你也可以通过hint来强制使用某个索引,这里强制使用{"age" : 1, "name" : 1}这个索引:
> db.people.find({"age" : {"$gt" : 10}, "name" : "mary"}).hint({"age" : 1, "name" : 1})
熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 一鍵生成PPT! Kimi :讓「PPT民工」先浪起來
Aug 01, 2024 pm 03:28 PM
一鍵生成PPT! Kimi :讓「PPT民工」先浪起來
Aug 01, 2024 pm 03:28 PM
Kimi:一句話,十幾秒鐘,一份PPT就新鮮出爐了。 PPT這玩意兒,可太招人煩了!開個碰頭會,要有PPT;寫個週報,要做PPT;拉個投資,要展示PPT;就連控訴出軌,都得發個PPT。大學比較像是學了個PPT專業,上課看PPT,下課做PPT。或許,37年前丹尼斯・奧斯汀發明PPT時也沒想到,有一天PPT竟然如此氾濫成災。嗎嘍們做PPT的苦逼經歷,說起來都是淚。 「一份二十多頁的PPT花了三個月,改了幾十遍,看到PPT都想吐」;「最巔峰的時候,一天做了五個PPT,連呼吸都是PPT」;「臨時開個會,都要做個
 從裸機到700億參數大模型,這裡有一個教程,還有現成可用的腳本
Jul 24, 2024 pm 08:13 PM
從裸機到700億參數大模型,這裡有一個教程,還有現成可用的腳本
Jul 24, 2024 pm 08:13 PM
我們知道LLM是在大規模電腦叢集上使用海量資料訓練得到的,本站曾介紹過不少用於輔助和改進LLM訓練流程的方法和技術。而今天,我們要分享的是一篇深入技術底層的文章,介紹如何將一堆連作業系統也沒有的「裸機」變成用來訓練LLM的電腦叢集。這篇文章來自於AI新創公司Imbue,該公司致力於透過理解機器的思維方式來實現通用智慧。當然,將一堆連作業系統也沒有的「裸機」變成用於訓練LLM的電腦叢集並不是一個輕鬆的過程,充滿了探索和試錯,但Imbue最終成功訓練了一個700億參數的LLM,並在此過程中積累
 AI在用 | AI製作獨居女孩生活Vlog,3天狂攬萬點讚量
Aug 07, 2024 pm 10:53 PM
AI在用 | AI製作獨居女孩生活Vlog,3天狂攬萬點讚量
Aug 07, 2024 pm 10:53 PM
機器之能報道編輯:楊文以大模型、AIGC為代表的人工智慧浪潮已經在悄悄改變我們生活及工作方式,但絕大部分人依然不知道該如何使用。因此,我們推出了「AI在用」專欄,透過直覺、有趣且簡潔的人工智慧使用案例,來具體介紹AI使用方法,並激發大家思考。我們也歡迎讀者投稿親自實踐的創新用例。影片連結:https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ最近,獨居女孩的生活Vlog在小紅書上走紅。一個插畫風格的動畫,再配上幾句治癒系文案,短短幾天就能輕鬆狂攬上
 又一Sora級選手來炸街!我們拿它和Sora、可靈PK了下
Aug 02, 2024 am 10:19 AM
又一Sora級選手來炸街!我們拿它和Sora、可靈PK了下
Aug 02, 2024 am 10:19 AM
當Sora「千呼萬喚」不出來時,OpenAI的對手們卻紛紛祭出大殺器來炸街。 Sora再不開放使用,真的要被偷家了!今日,舊金山新創公司LumaAI打出一手王牌,推出新一代AI影片生成模型DreamMachine。人人免費可用。據介紹,該模型能夠根據簡單的文字描述生成高品質、逼真視頻,效果堪比Sora。消息一出,大批用戶擠進官網嚐鮮。儘管官方聲稱該模型能在短短兩分鐘內生成120幀視頻,但由於訪問量激增,許多用戶在官網中苦苦等待數小時。 Luma的產品成長主管BarkleyDai不得不在Discord
 快手可靈AI全球全面開放內測,模型效果再次升級
Jul 24, 2024 pm 08:34 PM
快手可靈AI全球全面開放內測,模型效果再次升級
Jul 24, 2024 pm 08:34 PM
7月24日,快手视频生成大模型可灵AI宣布基础模型再次升级,并全面开放内测。快手表示,为了让更多用户能使用可灵AI,更好满足创作者不同层次的使用需求,即日起,在全面开放内测的基础上,还将正式上线会员体系,针对不同类别的会员,提供相应的专属功能服务。同时,可灵AI的基础模型也再次迎来升级,进一步提升用户体验。基础模型效果再升级进一步提升用户体验发布一个多月以来,可灵AI已经多次升级迭代,随着本次会员体系的推出,可灵AI的基础模型效果再次迎来蜕变。首先是画面质量显著提升,通过升级后的基础模型生成的视
 為什麼學線代時不知道:矩陣與圖竟然存在等價關係
Aug 19, 2024 pm 04:52 PM
為什麼學線代時不知道:矩陣與圖竟然存在等價關係
Aug 19, 2024 pm 04:52 PM
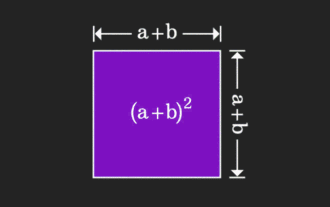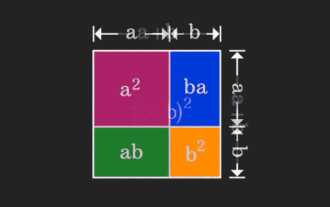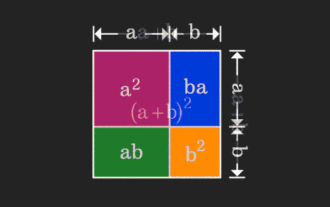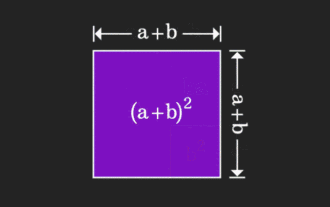
矩陣很難理解,但換個視角或許會不一樣。在學習數學時,我們常因所學知識的難度和抽象而受挫;但有些時候,只要換個角度,我們就能為問題的解答找到一個簡單又直觀的解法。舉個例子,小時候在學習和的平方(a+b)²公式時,我們可能不理解為什麼它等於a²+2ab+b²,只知道書上這麼寫,老師讓這麼記;直到某天我們看見了這張動圖:登時恍然大悟,原來我們可以從幾何角度來理解它!現在,這種恍然大悟之感又出現了:非負矩陣可以等價地轉換成對應的有向圖!如下圖所示,左邊的3×3矩陣其實可
 開發者利器! XREAL Air 2 ULTRA開售,沉浸式體驗AI開發
Aug 07, 2024 pm 06:40 PM
開發者利器! XREAL Air 2 ULTRA開售,沉浸式體驗AI開發
Aug 07, 2024 pm 06:40 PM
北京時間7月31日下午2點整,XREAL系列AR眼鏡的最新成員XREALAir2Ultra在國內正式發售,目前在京東、天貓和抖音等平台都已上線,首發價3999元。這款AR眼鏡是主要針對開發者群體打造的旗艦產品,旨在降低廣大開發者進入空間運算的門檻,推動空間運算領域革新,建立更繁榮的AR生態體系。賦能開發者六大核心能力作為XREAL第二款6DoF(SixDegreesofFreedom,六自由度)全功能眼鏡,XREALAir2Ultra也是目前業界唯一透過雙環境感知感測器(SLAMCamera)
 如何在Debian上配置MongoDB自動擴容
Apr 02, 2025 am 07:36 AM
如何在Debian上配置MongoDB自動擴容
Apr 02, 2025 am 07:36 AM
本文介紹如何在Debian系統上配置MongoDB實現自動擴容,主要步驟包括MongoDB副本集的設置和磁盤空間監控。一、MongoDB安裝首先,確保已在Debian系統上安裝MongoDB。使用以下命令安裝:sudoaptupdatesudoaptinstall-ymongodb-org二、配置MongoDB副本集MongoDB副本集確保高可用性和數據冗餘,是實現自動擴容的基礎。啟動MongoDB服務:sudosystemctlstartmongodsudosys
