

mongoDB入门需要了解的基本知识

MongoDB是一个开源的,高性能,无模式(或者说是模式自由),使用C++语言编写的面向文档的数据库。正因为MongoDB是面向文档的,所以它可以管理类似JSON的文档集合。又因为数据可以被嵌套到复杂的体系中并保持可以查询可索引,这样一来,应用程序便可以以一种
MongoDB是一个开源的,高性能,无模式(或者说是模式自由),使用C++语言编写的面向文档的数据库。正因为MongoDB是面向文档的,所以它可以管理类似JSON的文档集合。又因为数据可以被嵌套到复杂的体系中并保持可以查询可索引,这样一来,应用程序便可以以一种更加自然的方式来为数据建模。
下面介绍MongoDB的特点:
- 统一的UTF-8编码:不是UTF-8编码集合的数据也可以通过使用一种特殊的二进制数据类型来保存,查询。
- 跨平台支持:二进制文件可以在Windows,Linux,OS X和Solaris平台上使用。MongoDB可以在大多数小端系统上编译通过。
- 支持丰富的类型:支持 dates, regular expressions, code, binary data 等类型。
- 查询结果支持Cursor操作。
- 支持Ad hoc queries(Ad hoc query:即席查询,数据库应用最普遍的一种查询,利用数据仓库技术,可以让用户随时可以面对数据库,获取所希望的数据。在MongoDB中,可以在任何时候查询任何一个field。它支持 range queries,regular expression searches 和其他特殊的查询类型。同时查询也可以包含用户定义的javascript函数。
- 支持嵌套域的查询:查询可以深入到嵌套的对象和数组中,如果下面的对象被插入到users集合。
- 支持索引:支持二级索引包括 single-key, compound, unique, non-unique, geospatial indexes.嵌套的域同样也可以被索引。如果我们对一个数组类型进行索引,那么数组中所有元素也会自动被索引。当一个查询执行时,MongoDB的查询优化器会尝试多个不同的query plan,并选择执行速度最快的。开发者可以通过explain功能看到索引被使用的过程,然后可以通过hint功能来选择另一个不同的索引。可以在任何时候创建和删除索引。
- aggregation:除了ad hoc queries外,MongoDB还支持一系列工具来支持聚合,例如MapReduce和其他类似于SQL的GROUP BY的函数集合。
- 文件存储:该软件实现了一个称为GridFS的协议,这个协议是用来帮助从数据库中存储和获取文件的。
- 支持服务器端javascript执行:javaScript是MongoDB的一种通用语言,它可以被用在查询,聚集函数,直接由数据库执行。
- capped collection:MongoDB支持被称为capped collections(定量集合)的定长集合。Capped collections是唯一一种维持插入顺序的集合,其中,如果达到容量最大值,那么就会覆盖第一个元素,也就是说capped collection的行为类似于一个环形队列。一种特殊的cursor类型,称为tailable cursor,可以被用在capped collection上,当完成结果返回时,这种cursor不会关闭,而是会继续等待更多的结果来返回。也就是说如果有新的记录插入到capped collection的话,cursor会自动返回。
- 目前提供多种语言的driver。
- 部署:MongoDB使用的是memory-mapped files(内存映射文件),所以在32位机器上限制数据的最大大小为2GB,同时MongoDB服务器只能在小端系统上运行。
- Replication:MongoDB不应被部署到少于两台的服务器上,也就是说至少有一台作为master,另一台作为slave。Master可以用来执行读写,而slave可以从master上复制数据,但是它只能执行读操作或备份操作。开发者可以根据情况让一个operation可以被replicate到多个servers上。
{
"username" : "bob",
"address" : {
"street" : "123 Main Street",
"city" : "Springfield",
"state" : "NY"
}
}
我们可以这样查询嵌套在里层的域:db.users.find({“address.state”:"NY”})
数组元素则可以被这样查询:> db.food.insert({"fruit" : ["peach", "plum", "pear"]})或> db.food.find({"fruit" : "pear"})
下面是一个使用javascript的查询例子:db.foo.find({$where:function(){return this.x==this.y;}})
发送代码到数据库执行:db.eval(function(name){return “Hello, ”+name;},[“Joe”])
javaScript的变量可以被存储在数据库中并被其他javas作为全局变量使用。任何合法的javascript类型包括函数和对象,都可以被存储在MongoDB中,所以javascript可以被用来写<存储过程>
下面的代码是启动一个master服务器和对应的slave服务器:
$ mkdir –p ~/dbs/master ~/dbs/slave $ ./mongod –master –port 10000 –dbpath ~/dbs/master $ ./mongod –slave --port10001 –dbpath ~/dbs/slave -- source localhost:10000
补充知识
所谓“面向集合”(Collenction-Orented),意思是数据被分组存储在数据集中,被称为一个集合(Collenction)。每个集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定义任何模式(schema)。
模式自由(schema-free),意味着对于存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。
存储在集合中的文档,被存储为键-值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各中复杂的文件类型。我们称这种存储形式为BSON(Binary Serialized dOcument Format)。
MongoDB把数据存储在文件中(默认路径为:/data/db),为提高效率使用内存映射文件进行管理。MongoDB的主要目标是在键/值存储方式(提供了高性能和高度伸缩性)以及传统的RDBMS系统(丰富的功能)架起一座桥梁,集两者的优势于一身。
根据官方网站的描述,Mongo适合用于以下场景:
- 网站数据:Mongo非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
- 缓存:由于性能很高,Mongo也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo搭建的持久化缓存层可以避免下层的数据源过载。
- 大尺寸,低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
- 高伸缩性的场景:Mongo非常适合由数十或数百台服务器组成的数据库。Mongo的路线图中已经包含对MapReduce引擎的内置支持。
- 用于对象及JSON数据的存储:Mongo的BSON数据格式非常适合文档化格式的存储及查询。
自然,MongoDB的使用也会有一些限制,例如它不适合:
- 高度事务性的系统:例如银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
- 传统的商业智能应用:针对特定问题的BI数据库会对产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
- 需要SQL的问题

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 清華光學 AI 登 Nature!物理神經網絡,反向傳播不需要了
Aug 10, 2024 pm 10:15 PM
清華光學 AI 登 Nature!物理神經網絡,反向傳播不需要了
Aug 10, 2024 pm 10:15 PM
用光訓練神經網絡,清華成果最新登上了Nature!無法應用反向傳播演算法怎麼辦?他們提出了一種全前向模式(FullyForwardMode,FFM)的訓練方法,在實體光學系統中直接執行訓練過程,克服了傳統基於數位電腦模擬的限制。簡單點說,以前需要對物理系統進行詳細建模,然後在電腦上模擬這些模型來訓練網路。而FFM方法省去了建模過程,讓系統直接使用實驗數據進行學習和最佳化。這也意味著,訓練不需要再從後向前檢查每一層(反向傳播),而是可以直接從前向後更新網路的參數。打個比方,就像拼圖一樣,反向傳播
 為什麼學線代時不知道:矩陣與圖竟然存在等價關係
Aug 19, 2024 pm 04:52 PM
為什麼學線代時不知道:矩陣與圖竟然存在等價關係
Aug 19, 2024 pm 04:52 PM
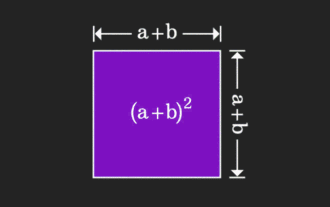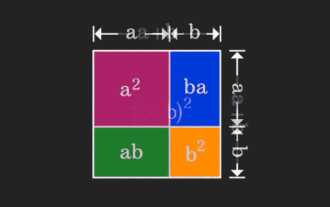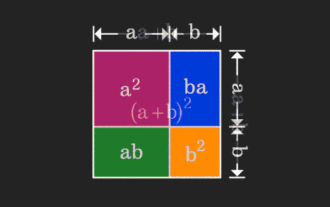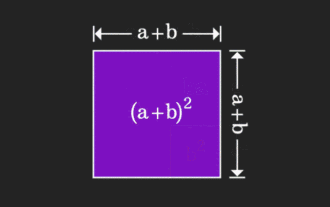
矩陣很難理解,但換個視角或許會不一樣。在學習數學時,我們常因所學知識的難度和抽象而受挫;但有些時候,只要換個角度,我們就能為問題的解答找到一個簡單又直觀的解法。舉個例子,小時候在學習和的平方(a+b)²公式時,我們可能不理解為什麼它等於a²+2ab+b²,只知道書上這麼寫,老師讓這麼記;直到某天我們看見了這張動圖:登時恍然大悟,原來我們可以從幾何角度來理解它!現在,這種恍然大悟之感又出現了:非負矩陣可以等價地轉換成對應的有向圖!如下圖所示,左邊的3×3矩陣其實可
 如何在Debian上配置MongoDB自動擴容
Apr 02, 2025 am 07:36 AM
如何在Debian上配置MongoDB自動擴容
Apr 02, 2025 am 07:36 AM
本文介紹如何在Debian系統上配置MongoDB實現自動擴容,主要步驟包括MongoDB副本集的設置和磁盤空間監控。一、MongoDB安裝首先,確保已在Debian系統上安裝MongoDB。使用以下命令安裝:sudoaptupdatesudoaptinstall-ymongodb-org二、配置MongoDB副本集MongoDB副本集確保高可用性和數據冗餘,是實現自動擴容的基礎。啟動MongoDB服務:sudosystemctlstartmongodsudosys
 MongoDB在Debian上的高可用性如何保障
Apr 02, 2025 am 07:21 AM
MongoDB在Debian上的高可用性如何保障
Apr 02, 2025 am 07:21 AM
本文介紹如何在Debian系統上構建高可用性的MongoDB數據庫。我們將探討多種方法,確保數據安全和服務持續運行。關鍵策略:副本集(ReplicaSet):利用副本集實現數據冗餘和自動故障轉移。當主節點出現故障時,副本集會自動選舉新的主節點,保證服務的持續可用性。數據備份與恢復:定期使用mongodump命令進行數據庫備份,並製定有效的恢復策略,以應對數據丟失風險。監控與報警:部署監控工具(如Prometheus、Grafana)實時監控MongoDB的運行狀態,並
 Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
直接通過 Navicat 查看 MongoDB 密碼是不可能的,因為它以哈希值形式存儲。取回丟失密碼的方法:1. 重置密碼;2. 檢查配置文件(可能包含哈希值);3. 檢查代碼(可能硬編碼密碼)。
 使用 Composer 解決推薦系統的困境:andres-montanez/recommendations-bundle 的實踐
Apr 18, 2025 am 11:48 AM
使用 Composer 解決推薦系統的困境:andres-montanez/recommendations-bundle 的實踐
Apr 18, 2025 am 11:48 AM
在開發一個電商網站時,我遇到了一個棘手的問題:如何為用戶提供個性化的商品推薦。最初,我嘗試了一些簡單的推薦算法,但效果並不理想,用戶的滿意度也因此受到影響。為了提升推薦系統的精度和效率,我決定採用更專業的解決方案。最終,我通過Composer安裝了andres-montanez/recommendations-bundle,這不僅解決了我的問題,還大大提升了推薦系統的性能。可以通過一下地址學習composer:學習地址
 CentOS MongoDB備份策略是什麼
Apr 14, 2025 pm 04:51 PM
CentOS MongoDB備份策略是什麼
Apr 14, 2025 pm 04:51 PM
CentOS系統下MongoDB高效備份策略詳解本文將詳細介紹在CentOS系統上實施MongoDB備份的多種策略,以確保數據安全和業務連續性。我們將涵蓋手動備份、定時備份、自動化腳本備份以及Docker容器環境下的備份方法,並提供備份文件管理的最佳實踐。手動備份:利用mongodump命令進行手動全量備份,例如:mongodump-hlocalhost:27017-u用戶名-p密碼-d數據庫名稱-o/備份目錄此命令會將指定數據庫的數據及元數據導出到指定的備份目錄。
 MongoDB 與關係數據庫:全面比較
Apr 08, 2025 pm 06:30 PM
MongoDB 與關係數據庫:全面比較
Apr 08, 2025 pm 06:30 PM
MongoDB與關係型數據庫:深度對比本文將深入探討NoSQL數據庫MongoDB與傳統關係型數據庫(如MySQL和SQLServer)的差異。關係型數據庫採用行和列的表格結構組織數據,而MongoDB則使用靈活的面向文檔模型,更適應現代應用的需求。主要區別數據結構:關係型數據庫使用預定義模式的表格存儲數據,表間關係通過主鍵和外鍵建立;MongoDB使用類似JSON的BSON文檔存儲在集合中,每個文檔結構可獨立變化,實現無模式設計。架構設計:關係型數據庫需要預先定義固定的模式;MongoDB支持
