

HBase实战系列1—压缩与编码技术

1、hbase压缩与编码的配置 安装LZO 解决方案: 1)apt-get install liblzo2-dev 2)hadoop-gpl-compression-0.2.0-dev.jar 放入classpath 把libgpl下的共享库文件放入/opt/hbase/hbase/lib/native/Linux-amd64-64/ libgplcompression.a libgplcompression.la
1、hbase压缩与编码的配置
安装LZO
解决方案:
1)apt-get install liblzo2-dev
2)hadoop-gpl-compression-0.2.0-dev.jar 放入classpath
把libgpl下的共享库文件放入/opt/hbase/hbase/lib/native/Linux-amd64-64/
libgplcompression.a libgplcompression.la libgplcompression.so libgplcompression.so.0 libgplcompression.so.0.0.0
3)配置:
4)测试:
hbase org.apache.hadoop.hbase.util.CompressionTest hdfs:///user.dat lzo
创建表格时,针对ColumnFamily设置压缩和编码方式。
HColumnDescriptor.setCompressionType(Compression.Algorithm.NONE);
HColumnDescriptor.setDataBlockEncoding(DataBlockEncoding.NONE);
使用FAST_DIFF 与 LZO之后的压缩情况:
hbase@GS-WDE-SEV0151:/opt/hbase/hbase$ hadoop fs -dus /hbase-weibo/weibo_test
hdfs://hbase-hdfs.goso.cn:9000/hbase-weibo/weibo_test???? 1021877013
hbase@GS-WDE-SEV0151:/opt/hbase/hbase$ hadoop fs -dus /hbase-weibo/weibo_lzo
hdfs://hbase-hdfs.goso.cn:9000/hbase-weibo/weibo_lzo???? 1179175365
hbase@GS-WDE-SEV0151:/opt/hbase/ops$ hadoop fs -dus /hbase-weibo/weibo_diff
hdfs://hbase-hdfs.goso.cn:9000/hbase-weibo/weibo_diff???? 2754679243
hbase@GS-WDE-SEV0151:/opt/hbase/hbase$ hadoop fs -dus /hbase-weibo/weibo-new
hdfs://hbase-hdfs.goso.cn:9000/hbase-weibo/weibo-new???? 5270708315
忽略数据中出现的Delete的数据、多个版本、以及超时的数据,压缩比达到1:5。
单独使用LZO的配置的压缩可接近也接近5:1的压缩比。
单独使用FAST_DIFF编码可以接近5:2的压缩比。
HBase操作过程:
Finish DataBlock–>Encoding DataBlock(FAST_DIFF\PREFIX\PREFIX_TRIE\DIFF)—>Compression DataBlock(LZO\GZ) —>Flush到磁盘。
如果Encoding和Compression的方式都设置NONE,中间的过程即可忽略。
2、相关测试
weibo-new使用的NONE、NONE
weibo_test使用的LZO、FAST_DIFF
weibo_diff使用了FAST_DIFF
weibo_lzo使用了LZO压缩
1、测试 扫描的效率:
| 个数 | 耗时 | |
| weibo_test | 2314054 | ??3m49.661s |
| weibo-new | 2314054 | ??1m55.349s |
| weibo_lzo | 2314054 | ? 3m24.378s |
| weibo_diff | 2314054 | ?4m41.792s |
结果分析:
使用LZO压缩或者FAST_DIFF的编码,扫描时造成大概一倍的开销
这个原因在于:在当前存储容量下,网络IO不是瓶颈,使用基本配置weibo-new吞吐量达到了45.68MB/s,而使用LZO压缩,显然经过一次或者两次解码之后,消耗了一些CPU时间片,从而耗时较长。
2、随机读的效率,采用单条随机的办法
首先scan出所有的Row,然后,使用shuf -n1000000 /tmp/row 随机取出1000000个row,然后按照单线程随机读的方式获取。
ps:每个Record有3个ColumnFamily,共有31个Column。
| 个数 | 耗时 | |
| weibo_test | 100,0000 | 122min12s, 平均7.3ms/Record |
| weibo-new | 100,0000 | 68min40s, 平均3.99ms/Record |
| weibo_lzo | 100,0000 | 83m26.539s, 平均5.00ms/Record |
| weibo_diff | 100,0000 | 58m5.915s, ?平均3.48ms/Record |

结果分析:
1)LZO解压缩的效率低于反解码的效率,在不以存储代价为第一考虑的情况下,优先选择FAST_DIFF编码方式。
2)LZO随机读会引起 hbase内部更多的读开销。下图在读取同样数据过程中,通过对于RegionServer上scanner采集到的读取个数,lzo明显代价较大。
3)在数据量不超过1T,并且HBase集群内存可以完全cover住整个Cache的情况下,可以不做压缩或者编码的设置,一般带有ROWCOL的bloomfilter基本就可以达到系统最佳的状态。如果数据远远大于Cache总量的10倍以上,优先使用编码方案(FAST_DIFF或者0.96引入的PREFIX_TRIE)
3、随机写的效率,采用批量写。批量个数为100
| 个数 | 耗时 | |
| weibo_test | 8640447 | 571670ms, 66μs/Put, 6.61ms/batch |
| weibo-new | 8640447 | 329694ms,38.12μs/Put,? 3.81ms/batch |
| weibo_lzo | 8640447 | 295770ms, 34.23μs/Put, 3.42ms/batch |
| weibo_diff | 8640447 | 250399ms, 28.97μs/Put,2.90ms/batch |
lz vs diff 写操作的集群吞吐图(两者开始执行的时间起点不同, 绿线代表weibo_diff、红线是weibo_lzo)
?

结论分析:
1)批量写操作,使用FAST_DIFF编码的开销最小,性能比不做任何配置(weibo-new)有24%提升。
2)使用diff,lzo双重配置,批量写操作有较大开销,并且压缩没有比单独使用LZO压缩有明显提升,所以不建议同时使用。
3、总体结论分析
1)在column较多、并且value较短的情况下,使用FAST_DIFF可以获得较好的压缩空间以及较优的读写延迟。推荐使用。
2)在对于存储空间比较紧缺的应用,单独使用LZO压缩,可以在牺牲一些随机读的前提下获得较高的空间压缩率(5:1)。
备注:本系列文章属于Binos_ICT在Binospace个人技术博客原创,原文链接为http://www.binospace.com/index.php/hbase-combat-series-1-compression-and-coding-techniques/?,未经允许,不得在网上转载。
From Binospace, post HBase实战系列1—压缩与编码技术
文章的脚注信息由WordPress的wp-posturl插件自动生成
Copyright © 2008
This feed is for personal, non-commercial use only.
The use of this feed on other websites breaches copyright. If this content is not in your news reader, it makes the page you are viewing an infringement of the copyright. (Digital Fingerprint:
)

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3的论文终于来了!这个模型于两周前发布,采用了与Sora相同的DiT(DiffusionTransformer)架构,一经发布就引起了不小的轰动。与之前版本相比,StableDiffusion3生成的图质量有了显著提升,现在支持多主题提示,并且文字书写效果也得到了改善,不再出现乱码情况。StabilityAI指出,StableDiffusion3是一个系列模型,其参数量从800M到8B不等。这一参数范围意味着该模型可以在许多便携设备上直接运行,从而显著降低了使用AI
 DualBEV:大幅超越BEVFormer、BEVDet4D,開卷!
Mar 21, 2024 pm 05:21 PM
DualBEV:大幅超越BEVFormer、BEVDet4D,開卷!
Mar 21, 2024 pm 05:21 PM
這篇論文探討了在自動駕駛中,從不同視角(如透視圖和鳥瞰圖)準確檢測物體的問題,特別是如何有效地從透視圖(PV)到鳥瞰圖(BEV)空間轉換特徵,這一轉換是透過視覺轉換(VT)模組實施的。現有的方法大致分為兩種策略:2D到3D和3D到2D轉換。 2D到3D的方法透過預測深度機率來提升密集的2D特徵,但深度預測的固有不確定性,尤其是在遠處區域,可能會引入不準確性。而3D到2D的方法通常使用3D查詢來採樣2D特徵,並透過Transformer學習3D和2D特徵之間對應關係的注意力權重,這增加了計算和部署的
 自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
軌跡預測在自動駕駛中承擔著重要的角色,自動駕駛軌跡預測是指透過分析車輛行駛過程中的各種數據,預測車輛未來的行駛軌跡。作為自動駕駛的核心模組,軌跡預測的品質對於下游的規劃控制至關重要。軌跡預測任務技術堆疊豐富,需熟悉自動駕駛動/靜態感知、高精地圖、車道線、神經網路架構(CNN&GNN&Transformer)技能等,入門難度很高!許多粉絲期望能夠盡快上手軌跡預測,少踩坑,今天就為大家盤點下軌跡預測常見的一些問題和入門學習方法!入門相關知識1.預習的論文有沒有切入順序? A:先看survey,p
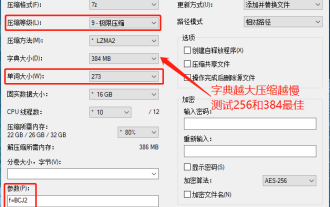 7-zip最大壓縮率設定,7zip如何壓縮到最小
Jun 18, 2024 pm 06:12 PM
7-zip最大壓縮率設定,7zip如何壓縮到最小
Jun 18, 2024 pm 06:12 PM
發現某下載網站下載的壓縮包,解壓縮後再打包會比原來的壓縮包大一些,小的幾十Kb的差別,大的幾十Mb的差別,如果上傳到雲盤或付費空間,文件少無所謂,文件多的話,大大的增加儲存成本。特意研究了下,有需要的可以藉鏡。壓縮等級:9-極限壓縮字典大小:256或384,字典越壓縮越慢,256MB之前壓縮率差異較大,384MB後壓縮率無差別單字大小:最大273參數:f=BCJ2,測試加參數壓縮率會高一些
 小米 15 系列全代號曝光:Dada、Haotian、Xuanyuan
Aug 22, 2024 pm 06:47 PM
小米 15 系列全代號曝光:Dada、Haotian、Xuanyuan
Aug 22, 2024 pm 06:47 PM
小米15系列預計10月正式發布,其全系列代號已在外媒MiCode程式碼庫曝光。其中,旗艦級小米15Ultra代號為"Xuanyuan"(意為"軒轅"),此名源自中國神話中的黃帝,象徵尊貴。小米15的代號為"Dada",而小米15Pro則以"Haotian"(意為"昊天")為名。小米15SPro內部代號為"dijun",暗指《山海經》創世神帝俊。小米15Ultra系列涵蓋
 華為 Mate 60 系列最佳入手時機,新增 AI 消除 + 影像升級,更可享秋日禮遇活動
Aug 29, 2024 pm 03:33 PM
華為 Mate 60 系列最佳入手時機,新增 AI 消除 + 影像升級,更可享秋日禮遇活動
Aug 29, 2024 pm 03:33 PM
自去年华为Mate60系列开售以来,我个人就一直将Mate60Pro作为主力机使用。在将近一年的时间里,华为Mate60Pro经过多次OTA升级,综合体验有了显著提升,给人一种常用常新的感觉。比如近期,华为Mate60系列就再度迎来了影像功能的重磅升级。首先是新增AI消除功能,可以智能消除路人、杂物并对空白部分进行自动补充;其次是主摄色准、长焦清晰度均有明显升级。考虑到现在是开学季,华为Mate60系列还推出了秋日礼遇活动:购机可享至高800元优惠,入手价低至4999元。常用常新的产品力加上超值
 PHP實戰:快速實作斐波那契數列的程式碼範例
Mar 20, 2024 pm 02:24 PM
PHP實戰:快速實作斐波那契數列的程式碼範例
Mar 20, 2024 pm 02:24 PM
PHP實戰:快速實現斐波那契數列的程式碼範例斐波那契數列是數學中一個非常有趣且常見的數列,其定義如下:第一個和第二個數為0和1,從第三個數開始,每個數都是前兩個數的和。斐波那契數列的前幾個數字依序為0,1,1.2,3,5,8,13,21,...依此類推。在PHP中,我們可以透過遞歸和迭代兩種方式來實現斐波那契數列的生成。下面我們分別來展示這兩
 綜述!深度模型融合(LLM/基礎模型/聯邦學習/微調等)
Apr 18, 2024 pm 09:43 PM
綜述!深度模型融合(LLM/基礎模型/聯邦學習/微調等)
Apr 18, 2024 pm 09:43 PM
23年9月國防科大、京東和北理工的論文「DeepModelFusion:ASurvey」。深度模型整合/合併是一種新興技術,它將多個深度學習模型的參數或預測合併為一個模型。它結合了不同模型的能力來彌補單一模型的偏差和錯誤,以獲得更好的性能。而大規模深度學習模型(例如LLM和基礎模型)上的深度模型整合面臨一些挑戰,包括高運算成本、高維度參數空間、不同異質模型之間的干擾等。本文將現有的深度模型融合方法分為四類:(1)“模式連接”,透過一條損失減少的路徑將權重空間中的解連接起來,以獲得更好的模型融合初
