

Impala与Hive的比较

1. Impala架构 Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Eng
1. Impala架构
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。其架构如图 1所示,Impala主要由Impalad, State Store和CLI组成。

图 1
Impalad: 与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
Impala State Store: 跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
CLI: 提供给用户查询使用的命令行工具(Impala Shell使用python实现),同时Impala还提供了Hue,JDBC, ODBC使用接口。
2. 与Hive的关系
Impala与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关系如图 2所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。

图 2
3. Impala的查询处理过程
Impalad分为Java前端与C++处理后端,接受客户端连接的Impalad即作为这次查询的Coordinator,Coordinator通过JNI调用Java前端对用户的查询SQL进行分析生成执行计划树,不同的操作对应不用的PlanNode, 如:SelectNode, ScanNode, SortNode, AggregationNode, HashJoinNode等等。
执行计划树的每个原子操作由一个PlanFragment表示,通常一条查询语句由多个Plan Fragment组成, Plan Fragment 0表示执行树的根,汇聚结果返回给用户,执行树的叶子结点一般是Scan操作,分布式并行执行。
Java前端产生的执行计划树以Thrift数据格式返回给Impala C++后端(Coordinator)(执行计划分为多个阶段,每一个阶段叫做一个PlanFragment,每一个PlanFragment在执行时可以由多个Impalad实例并行执行(有些PlanFragment只能由一个Impalad实例执行,如聚合操作),整个执行计划为一执行计划树),由Coordinator根据执行计划,数据存储信息(Impala通过libhdfs与HDFS进行交互。通过hdfsGetHosts方法获得文件数据块所在节点的位置信息),通过调度器(现在只有simple-scheduler, 使用round-robin算法)Coordinator::Exec对生成的执行计划树分配给相应的后端执行器Impalad执行(查询会使用LLVM进行代码生成,编译,执行。对于使用LLVM如何提高性能这里有说明),通过调用GetNext()方法获取计算结果,如果是insert语句,则将计算结果通过libhdfs写回HDFS当所有输入数据被消耗光,执行结束,之后注销此次查询服务。
Impala的查询处理流程大概如图3所示:

图 3
下面以一个SQL查询语句为例分析Impala的查询处理流程。如select sum(id), count(id), avg(id) from customer_small group by id; 以此语句生成的计划为:
PLAN FRAGMENT 0
PARTITION: UNPARTITIONED4:EXCHANGE
tuple ids: 1PLAN FRAGMENT 1
PARTITION: HASH_PARTITIONED:STREAM DATA SINK
EXCHANGE ID: 4
UNPARTITIONED3:AGGREGATE
| output: SUM(), SUM( )
| group by:
| tuple ids: 1
|
2:EXCHANGE
tuple ids: 1PLAN FRAGMENT 2
PARTITION: RANDOMSTREAM DATA SINK
EXCHANGE ID: 2
HASH_PARTITIONED:1:AGGREGATE
| output: SUM(id), COUNT(id)
| group by: id
| tuple ids: 1
|
0:SCAN HDFS
table=default.customer_small #partitions=1 size=193B
tuple ids: 0
执行行计划树如图 4所示, 绿色的部分为可以分布式并行执行:

图 4
4. Impala相对于Hive所使用的优化技术
1、没有使用MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
3、充分利用可用的硬件指令(SSE4.2)。
4、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
5、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
6、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
5. Impala与Hive的异同
数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:两者使用相同的元数据。
SQL解释处理:比较相似都是通过词法分析生成执行计划。
执行计划:
Hive: 依赖于MapReduce执行框架,执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
数据流:
Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)。
调度:
Hive: 任务调度依赖于Hadoop的调度策略。
Impala: 调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器目前还比较简单,在SimpleScheduler::GetBackend中可以看到,现在还没有考虑负载,网络IO状况等因素进行调度。但目前Impala已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度吧。
容错:
Hive: 依赖于Hadoop的容错能力。
Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败,再查一次就好了,再查一次的成本很低)。但从整体来看,Impala是能很好的容错,所有的Impalad是对等的结构,用户可以向任何一个Impalad提交查询,如果一个Impalad失效,其上正在运行的所有Query都将失败,但用户可以重新提交查询由其它Impalad代替执行,不会影响服务。对于State Store目前只有一个,但当State Store失效,也不会影响服务,每个Impalad都缓存了State Store的信息,只是不能再更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致本次Query失败。
适用面:
Hive: 复杂的批处理查询任务,数据转换任务。
Impala:实时数据分析,因为不支持UDF,能处理的问题域有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析。
6. Impala的优缺点
优点:
- 支持SQL查询,快速查询大数据。
- 可以对已有数据进行查询,减少数据的加载,转换。
- 多种存储格式可以选择(Parquet, Text, Avro, RCFile, SequeenceFile)。
- 可以与Hive配合使用。
缺点:
- 不支持用户定义函数UDF。
- 不支持text域的全文搜索。
- 不支持Transforms。
- 不支持查询期的容错。
- 对内存要求高。
原文地址:Impala与Hive的比较, 感谢原作者分享。

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 小米14 Pro怎麼開啟nfc功能?
Mar 19, 2024 pm 02:28 PM
小米14 Pro怎麼開啟nfc功能?
Mar 19, 2024 pm 02:28 PM
現今手機的效能和功能越來越強大,幾乎所有手機都配備了便利的NFC功能,方便用戶進行行動支付和身分認證。然而,有些小米14Pro的用戶可能不清楚如何啟用NFC功能。接下來,讓我詳細向大家介紹一下。小米14Pro怎麼開啟nfc功能?步驟一:打開手機的設定選單。步驟二:找到並點選「連接和分享」或「無線和網路」選項。步驟三:在連接和共享或無線和網路選單中,找到並點擊「NFC和付款」。步驟四:找到並點選「NFC開關」。一般情況下,預設是關閉的狀態。步驟五:在NFC開關頁面上,點選開關按鈕,將其切換為開啟狀
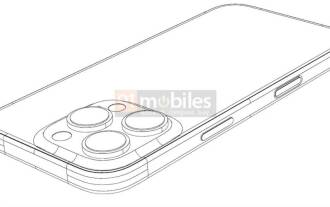 iPhone 16 Pro CAD 圖曝光 加入第二個新按鍵
Mar 09, 2024 pm 09:07 PM
iPhone 16 Pro CAD 圖曝光 加入第二個新按鍵
Mar 09, 2024 pm 09:07 PM
iPhone16Pro的CAD檔案已經曝光,設計與先前的傳聞一致。去年秋天,iPhone15Pro新增了Action按鈕,而今年秋天,Apple似乎計劃對這款硬體的尺寸進行微小的調整。加入Capture按鈕據傳言,iPhone16Pro可能會新增第二個新按鈕,這將是繼去年之後連續第二年增加新按鈕。傳聞指出新的Capture按鈕將被設定在iPhone16Pro的右下側,這項設計可望讓相機控制更加便捷,同時也能讓Action按鈕用於其他功能。這個按鈕將不再只是一個普通的快門按鈕。關於相機,從目前iP
 1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显著的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
 華為 Pocket2怎麼隔空刷抖音?
Mar 18, 2024 pm 03:00 PM
華為 Pocket2怎麼隔空刷抖音?
Mar 18, 2024 pm 03:00 PM
隔空滑動螢幕是華為的一項功能,在華為mate60系列中可以說是備受好評,這個功能是通過利用手機上的激光感應器和前置攝像頭的3D深感攝像頭,來完成一系列不需要觸碰螢幕的功能,比如說隔空刷抖音,但華為Pocket2該要怎麼隔空刷抖音呢?華為Pocket2怎麼隔空截圖? 1.開啟華為Pocket2的設定2、然後選擇【輔助功能】。 3.點選打開【智慧感知】。 4.打開【隔空滑動螢幕】、【隔空截圖】、【隔空按壓】開關就可以了。 5.使用的時候,需要再距離螢幕20~40CM處,張開手掌,待螢幕上出現手掌圖標,
 Spring Data JPA 的架構和工作原理是什麼?
Apr 17, 2024 pm 02:48 PM
Spring Data JPA 的架構和工作原理是什麼?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA基於JPA架構,透過映射、ORM和事務管理與資料庫互動。其儲存庫提供CRUD操作,派生查詢簡化了資料庫存取。此外,它使用延遲加載,僅在必要時檢索數據,從而提高了效能。
 WPS Word怎麼設定行距讓文件更工整
Mar 20, 2024 pm 04:30 PM
WPS Word怎麼設定行距讓文件更工整
Mar 20, 2024 pm 04:30 PM
WPS是我們常用的辦公室軟體,在進行長篇文章的編輯時,常常會因為字體太小而看不清楚,所以會對字體和整個文件進行調整。例如:把文件進行行距的調整,會讓整個文件變得非常清晰,我建議各位小夥伴們都要學會這個操作步驟,今天就分享給大家,具體的操作步驟如下,快來看一看!開啟要調整的WPS文字文件,在【開始】選單中找到段落設定工具欄,你會看到行距設定小圖示(如圖中紅色線圈所示)。 2.點選行距設定右下角的小倒三角形,會出現對應的行距數值,可以選擇1~3倍行距(如圖箭頭所示)。 3.或者點選滑鼠右鍵點擊段落,就會出
 TrendX 研究院:Merlin Chain 計畫分析及生態盤點
Mar 24, 2024 am 09:01 AM
TrendX 研究院:Merlin Chain 計畫分析及生態盤點
Mar 24, 2024 am 09:01 AM
根據3月2日數據統計,比特幣二層網路MerlinChain總TVL已達30億美元。其中比特幣生態資產佔比達90.83%,包括價值15.96億美元的BTC以及4.04億美元的BRC-20資產等。上一個月,MerlinChain在開啟質押活動14天內,其TVL總額就已經達到了19.7億美元,超過了去年11月份上線也是最近同樣引人注目的Blast。 2月26日,MerlinChain生態內的NFT總價值超過了4.2億美元,成為除以太坊以外NFT市值最高的公鏈項目。項目簡介MerlinChain是OKX支
 手撕Llama3第1層: 從零開始實現llama3
Jun 01, 2024 pm 05:45 PM
手撕Llama3第1層: 從零開始實現llama3
Jun 01, 2024 pm 05:45 PM
一、Llama3的架構在本系列文章中,我們從頭開始實作llama3。 Llama3的整體架構:圖片Llama3的模型參數:讓我們來看看這些參數在LlaMa3模型中的實際數值。圖片[1]上下文視窗(context-window)在實例化LlaMa類別時,變數max_seq_len定義了context-window。類別中還有其他參數,但這個參數與transformer模型的關係最為直接。這裡的max_seq_len是8K。圖片[2]字彙量(Vocabulary-size)和注意力層(AttentionL
