

数据驱动销售个性化推荐引擎

这是之前发布于《程序员》杂志2011年08期的一篇文章,这里再在Blog上发布一下。 在当前这个信息量飞速增长的时代,一个企业,尤其是电子商务企业的成功已经越来越多地与其海量数据处理能力相关联。高效、迅速地从海量数据中挖掘出潜在价值并转化为决策依据的
这是之前发布于《程序员》杂志2011年08期的一篇文章,这里再在Blog上发布一下。
在当前这个信息量飞速增长的时代,一个企业,尤其是电子商务企业的成功已经越来越多地与其海量数据处理能力相关联。高效、迅速地从海量数据中挖掘出潜在价值并转化为决策依据的能力,将成为企业的核心竞争力。
数据的重要性毋庸置疑,但随着数据的产生速度越来越快,数据量越来越大,数据处理技术的挑战自然也越来越大。如何从海量数据中挖掘出价值所在,分析出深层含义,进而转化为可操作的信息,已经成为各互联网企业尤其是电子商务公司不得不研究的课题。本文将介绍国内箱包行业电子商务领军者麦包包如何利用海量数据的分析处理(个性化推荐引擎)来协助用户更好地完成购买体验。

- 图1 数据层基础架构

数据层基础架构
如图1所示,麦包包的数据层基础架构与其他很多互联网公司相比,可能会有一点儿差异,那就是有一个用于实时分析处理的在线分析数据层,用来处理一些对实时性要求较高的分析任务。
总的来说,麦包包的数据层分为下面三个部分。
- 在线交易数据层
用于存放网站对外访问数据,如交易相关、产品相关、用户相关等数据。
- 离线分析数据层
用于分析各种报表、数据挖掘,如购买行为、销售分析、浏览跟踪等。
- 在线分析数据层
用于处理一些对实时性要求较高的分析,如在线交易分析、用户浏览推荐等。在线交易数据层和离线分析数据层对于大家来说都已经比较熟悉了,二者的数据特点和访问特点都很清晰明确,架构方向也相对明确。只有在线分析系统比较特别,既有高并发的用户访问,同时又兼具了分析型复杂查询及海量的基础数据,构建起来相对要复杂一些。所以下面简单介绍一下麦包包如何构建在线分析系统的应用之一——“个性化推荐引擎”。
个性化推荐引擎
我们首先分析一下这个推荐引擎的需求。
- 关联个性化
根据用户的喜好倾向以及访问历史记录,不同用户浏览同一个产品时,将给出不同的关联推荐结果。
- 页面个性化
不同用户访问同一个页面,我们将会根据用户的以往购买历史及浏览行为而展示个性化的内容。
- 搜索个性化
随着用户的多次搜索及结果点击行为,我们会对搜索结果进行过滤重组,尽可能展示更符合用户需求的搜索结果。也就是说,在完全相同的基础数据中,不同用户在同一时间搜索同一个关键词,可能会给出不一样的结果;或者同一个用户重复多次搜索同一个关键词,也可能会有不一样的结果。
我们再来看一看推荐引擎的数据特点。
- 海量
超过500万会员,5位数的SKU,7位数的访问量。将这些数据与会员及SKU的各类属性相互关联,数据量之庞大可想而知。
- 多维度
从性能优化角度来说,数据量大并不可怕,只要访问方式简单,很容易通过索引等手段进行优化。可偏偏不幸的是,由于将用户和产品进行多维度关联,既需要根据用户去分析,又需要根据产品去关联,再辅以运行时的各类属性;既可能各个维度同时存在,也可能只有任何一个维度;多维度就多维度吧,可还有很多访问是分析型,比较难以优化扩展。
- 访问高并发
当然,数据量大也并不一定就可怕,如果并发访问较小,响应时间要求不是太高,那也容易解决,可以用Hadoop之类的分布式系统来分析计算。可恰恰不巧的就是这个系统面对的是网站上的访问客户,对并发及响应时间的要求和OLTP系统一样。
需求已经确定,数据特点也已了解,下一步就是根据数据的特点,设计一个切实可行的架构来实现这些应用需求了。
在如此海量数据中进行高并发的复杂分析查询,还要能够快速响应,看上去就像是一个不可能的任务。但仔细分析之后,我们不难发现,推荐引擎结果主要由以下几个因素决定。
- 用户固定属性:年龄、性别、职业类型、地域、价格承受范围、色彩喜好、品牌喜好等。
- 产品固定属性:品牌、类别、材质、价格、色系等。
- 用户以往行为:浏览历史、购买历史等。
- 用户当前行为:当前点击、浏览等。
以上四个因素实际上对应了四种数据,在分析每一种数据的特点之后,可以发现前面三个因素所对应的数据都是相对静态的,只有用户当前行为才是一个在不断变化的动态数据。也就是说,在海量数据中,只有少部分数据是动态的,其他大部分都是静态。
当然,用户属性中的各种喜好,也需要我们通过用户以往的历史购买以及浏览行为进行各种分析挖掘才能获得,但这都是由历史积淀数据分析得来,而不是由当前的运行时动态数据决定。价格承受范围以及地域特性也同样如此。
数据的这一特性对我们的架构设计起到了一个非常关键的作用,因为我们可以使用完全不同的方式来将静态数据和动态数据分开处理,再合并分析。静态数据的变化较小,实时性要求较低,我们将进行离线分析;动态数据相对较少,但实时性要求较高,我们在线实时处理。动、静数据在线合并分析。这样一来,我们就可以很轻松地绕过海量数据的高并发在线分析的问题,将这一动作交由离线分析系统定时作业批量完成,既不会有高并发问题,又不存在响应时间的压力。至于在线实时数据的处理,由于数据量的大幅缩减,以及访问方式的简化,比在线交易的OLTP系统复杂度高不了太多,自然也就容易优化了。
- 图2 推荐引擎基本架构

架构设计
简单来说,推荐引擎系统本身的基础架构就如图2所展现的一样,一部分数据进行离线计算,另一部分数据在线计算合并,最终通过推荐引擎API将数据处理后返回给前端应用。
看上去简单,但有几个问题并没有展现出来,那就是离线计算和在线计算这两部分具体是如何构建的?数据如何进入离线计算系统?又如何将离线运算结果回送至在线计算系统中?最终数据又如何交由前端应用使用?让我们再来看看图3。
离线分析层完全可以通过成熟的产品来构建,如Greenplum、Hadoop等,目前我们已经使用了Greeplum,后续很快还会引入Hadoop,通过HBase + Hive来对处理我们的用户与各SKU的关系数据,帮助进一步完善我们的协同过滤算法,进而优化推荐引擎。在线合并分析层我们选择MySQL数据库。可能有些人会问,为什么不使用当前如此流行的NoSQL产品呢?主要原因有以下两点。
- MySQL更便于维护与备份等运维需求。
- NoSQL不满足我们的一些分析型查询需求。
NoSQL产品虽然流行,但每种产品都还只适于某些特定的应用场景,很多听上去完美的理论目前暂时还仅仅只是听上去完美,实际用起来仍然存在各种各样的问题。所以我们选择了更适合于我们的MySQL作为在线合并分析层的数据库。
 图3 推荐引擎整体架构
图3 推荐引擎整体架构
整个架构的数据流,如图3所示。
- 前端应用产生用户的浏览日志、购买日志、搜索日志以及用户及产品属性数据进入。
- 通过文件日志收集程序以及基于MySQL开放复制协议所定制的数据同步工具(注:在我的个人网站上有介绍:http://isky000.com/database/mysql-replication-extend)将数据同步至离线分析系统中。
- 通过离线任务的统计分析,得出会员的各种喜好属性,并将之与产品属性进行关联分析,得出一个用户产品倾向性关联结果,然后再通过应用程序定期从离线分析系统将上述分析结果写入在线合并分析数据库中。
- 推荐引擎根据前端应用(如Search)传入的用户当前运行时操作属性,与在线合并分析数据库中属性进行合并(Merge),再过滤(Filter)。
- 前端应用从推荐引擎处获取Merge与Filter之后的数据,再在前端页面上完成展现。
以上就是整个推荐引擎的数据流架构方案,乍一看也没有太多特别的内容,但在实际实施过程中,会遇到以下几个难点。
- 各种日志传输到离线分析系统,如何做到尽可能实时并不影响在线系统。
这个难点,我们首先在每一个页面部署监测点,通过请求一个gif图片来获得用户的各种浏览信息,并存入到MySQL数据库,交易相关的数据自然也会有在数据库中进行存储。然后使用通过扩展MySQL复制协议而实现的日志解析合并程序,实时解析 MySQL日志,再将其以我们需要的格式传输至离线分析系统中进行分析运算。
- 如何将用户的运行时操作属性与我们的离线分析结果进行Merge及Filte。
这个难点,实际上在6月刊的《程序员》杂志对麦包包首席架构师盛国军的采访稿中,已经有了相应的介绍。我们主要使用了基于用户(User)、商品(Item)、话题(Topic)以及曝光(Exposure)这四种协同过滤技术,来实现推荐算法。
总的来说,数据量的增长,以及分析需求的越来越复杂,将会对互联网公司的数据处理能力提出越来越高的要求、越来越大的挑战。但每一个场景都有其特性,充分分析其数据特性,将合适的软件用在合适的场景下,才能更好地解决实际问题。
原文地址:数据驱动销售——个性化推荐引擎, 感谢原作者分享。

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何在iPhone中使Google地圖成為預設地圖
Apr 17, 2024 pm 07:34 PM
如何在iPhone中使Google地圖成為預設地圖
Apr 17, 2024 pm 07:34 PM
iPhone上的預設地圖是Apple專有的地理位置供應商「地圖」。儘管地圖越來越好,但它在美國以外的地區運作不佳。與谷歌地圖相比,它沒有什麼可提供的。在本文中,我們討論了使用Google地圖成為iPhone上的預設地圖的可行性步驟。如何在iPhone中使Google地圖成為預設地圖將Google地圖設定為手機上的預設地圖應用程式比您想像的要容易。請依照以下步驟操作–先決條件步驟–您必須在手機上安裝Gmail。步驟1–開啟AppStore。步驟2–搜尋“Gmail”。步驟3–點選Gmail應用程式旁
 開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
0.這篇文章乾了啥?提出了DepthFM:一個多功能且快速的最先進的生成式單目深度估計模型。除了傳統的深度估計任務外,DepthFM還展示了在深度修復等下游任務中的最先進能力。 DepthFM效率高,可以在少數推理步驟內合成深度圖。以下一起來閱讀這項工作~1.論文資訊標題:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 小紅書怎麼發布作品 小紅書怎麼發布文章和圖片
Mar 22, 2024 pm 09:21 PM
小紅書怎麼發布作品 小紅書怎麼發布文章和圖片
Mar 22, 2024 pm 09:21 PM
小紅書你們可以查看到各種的內容,為你帶來多樣的幫助,讓你發現更美好的生活,你有什麼想要分享的話,也是可以在這裡發布的,讓大家都可以看一看,同時也能夠為自己帶來收益,非常的划算,有不懂怎麼在這裡發作品的,都可以查看教程,每天都可以使用這個軟體,發佈各種內容,幫助大家們更好的使用起來,有需要的都不要錯過了! 1、打開小紅書,點選下方加號圖示。 2、這裡有【影片】【圖片】【實況圖】選擇;選擇想要發佈的內容點選勾選。 3、在內容編輯頁選擇【下一步】。 4、輸入您想要發佈的文字內容點選【發布筆
 iPhone中缺少時鐘應用程式:如何修復
May 03, 2024 pm 09:19 PM
iPhone中缺少時鐘應用程式:如何修復
May 03, 2024 pm 09:19 PM
您的手機中缺少時鐘應用程式嗎?日期和時間仍將顯示在iPhone的狀態列上。但是,如果沒有時鐘應用程序,您將無法使用世界時鐘、碼錶、鬧鐘等多項功能。因此,修復時鐘應用程式的缺失應該是您的待辦事項清單的首位。這些解決方案可以幫助您解決此問題。修復1–放置時鐘應用程式如果您錯誤地從主畫面中刪除了時鐘應用程序,您可以將時鐘應用程式放回原位。步驟1–解鎖iPhone並開始向左側滑動,直到到達「應用程式庫」頁面。步驟2–接下來,在搜尋框中搜尋「時鐘」。步驟3–當您在搜尋結果中看到下方的「時鐘」時,請按住它並
 Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
谷歌力推的JAX在最近的基準測試中表現已經超過Pytorch和TensorFlow,7項指標排名第一。而且測試並不是JAX性能表現最好的TPU上完成的。雖然現在在開發者中,Pytorch依然比Tensorflow更受歡迎。但未來,也許有更多的大型模型會基於JAX平台進行訓練和運行。模型最近,Keras團隊為三個後端(TensorFlow、JAX、PyTorch)與原生PyTorch實作以及搭配TensorFlow的Keras2進行了基準測試。首先,他們為生成式和非生成式人工智慧任務選擇了一組主流
 如何發布小紅書影片作品?發影片要注意什麼?
Mar 23, 2024 pm 08:50 PM
如何發布小紅書影片作品?發影片要注意什麼?
Mar 23, 2024 pm 08:50 PM
隨著短影片平台的興起,小紅書成為了許多人分享生活、表達自我、獲取流量的平台。在這個平台上,發布影片作品是一種非常受歡迎的互動方式。那麼,如何發布小紅書影片作品呢?一、如何發布小紅書影片作品?首先,確保準備好一段適合分享的影片內容。你可以利用手機或其他攝影設備拍攝,需要注意畫質和聲音的清晰度。 2.剪輯影片:為了讓作品更具吸引力,可以剪輯影片。可使用專業的影片剪輯軟體,如抖音、快手等,加入濾鏡、音樂、字幕等元素。 3.選擇封面:封面是吸引用戶點擊的關鍵,選擇一張清晰、有趣的圖片作為封面,讓
 iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
在iPhone上面臨滯後,緩慢的行動數據連線?通常,手機上蜂窩互聯網的強度取決於幾個因素,例如區域、蜂窩網絡類型、漫遊類型等。您可以採取一些措施來獲得更快、更可靠的蜂窩網路連線。修復1–強制重啟iPhone有時,強制重啟設備只會重置許多內容,包括蜂窩網路連線。步驟1–只需按一次音量調高鍵並放開即可。接下來,按降低音量鍵並再次釋放它。步驟2–過程的下一部分是按住右側的按鈕。讓iPhone完成重啟。啟用蜂窩數據並檢查網路速度。再次檢查修復2–更改資料模式雖然5G提供了更好的網路速度,但在訊號較弱
 無法允許存取 iPhone 中的相機和麥克風
Apr 23, 2024 am 11:13 AM
無法允許存取 iPhone 中的相機和麥克風
Apr 23, 2024 am 11:13 AM
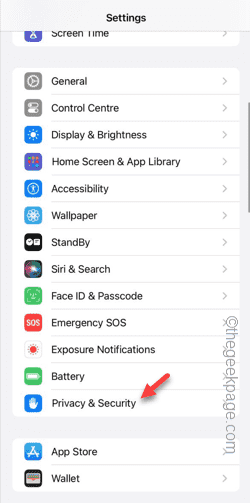
您在嘗試使用應用程式時是否收到“無法允許存取攝影機和麥克風”?通常,您可以在需要提供的基礎上向特定物件授予攝影機和麥克風權限。但是,如果您拒絕權限,攝影機和麥克風將無法運作,而是顯示此錯誤訊息。解決這個問題是非常基本的,你可以在一兩分鐘內完成。修復1–提供相機、麥克風權限您可以直接在設定中提供必要的攝影機和麥克風權限。步驟1–轉到“設定”選項卡。步驟2–打開「隱私與安全」面板。步驟3–在那裡打開“相機”權限。步驟4–在裡面,您將找到已要求手機相機權限的應用程式清單。步驟5–開啟指定應用的“相機”
