

常用的两种数据分区方法(以Teradata为例)

海量数据性能优化的一个基本的原则就是“分区”(也有叫“分片”的)。分区思想其实就是日常工作生活中的抽屉原理:我们把自己的物品按照某种逻辑归置到多个小抽
海量数据性能优化的一个基本的原则就是“分区”(也有叫“分片”的)。分区思想其实就是日常工作生活中的抽屉原理:我们把自己的物品按照某种逻辑归置到多个小抽屉中,一般会比混在一个大抽屉中好找;但是小抽屉太多了、或者逻辑混乱了,也可能效果适得其反。
Teradata的分区语法较为简洁,其中常用的是按时间分区,如下例只要添加到create table语句末尾就可以实现2013年全年一天一个分区了
更进一步,香港空间,其中如下面的语法元素:
my_field='A'
可以修改为类似于这样的形式:
SUBSTR(my_field,1,1) IN ('E','F','G')
在现实中,美国空间,因为访问数据从全表扫描变成了分区扫描的原因,香港服务器,某些步骤可以达成10-100倍的性能提升。对于复杂的耗时较长的大作业,也总是能够缩短一半以上的运行时间。非常有意思的现象是,即使是经验丰富的开发人员,对数据分区的掌握也不一定很好。数据分区理念是超越具体数据库的,无论是Teradata还是别的什么数据库,在我过去将近十年的职业生涯中,大多数性能问题都可以通过数据分区得以妥善解决。
本文出自 “iData” 博客,请务必保留此出处

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 解決win11系統保留分區無法更新的問題
Dec 26, 2023 pm 12:41 PM
解決win11系統保留分區無法更新的問題
Dec 26, 2023 pm 12:41 PM
在更新了win11後有些用戶遇到了無法更新系統保留的分區,導致沒法使用下載更多的新軟體,所以今天就給你們帶來了win11無法更新系統保留的分區解決方法,趕快來一起下載試試吧。 win11無法更新系統保留的分區怎麼辦:1、先右鍵下方的開始選單按鍵。 2、然後右鍵點選選單點擊運行。 3.在運行中輸入:diskmgmt.msc回車。 4.之後可以進入系統磁碟,查看EFI系通分割區,查看空間是否小於300M。 5.如果太小可以下載工具將系統預留分割區改成大於300MB建議450M即可。
 【Linux系統】fdisk相關分區指令。
Feb 19, 2024 pm 06:00 PM
【Linux系統】fdisk相關分區指令。
Feb 19, 2024 pm 06:00 PM
fdisk是常用的Linux命令列工具,用於建立、管理和修改磁碟分割區。以下是一些常用的fdisk指令:顯示磁碟分割資訊:fdisk-l此指令將顯示系統中所有磁碟的分割區資訊。選擇要操作的磁碟:fdisk/dev/sdX將/dev/sdX替換為要操作的實際磁碟裝置名稱,如/dev/sda。建立新分割區:n這將引導您建立一個新的分割區。依照指示輸入分割區類型、起始磁區、大小等資訊。刪除分割區:d這將引導您選擇要刪除的分割區。依照提示選擇要刪除的分割區編號。修改分割區類型:t這將引導您選擇要修改類型的分割區。按照提
 win10安裝後無法分割的解決方法
Jan 02, 2024 am 09:17 AM
win10安裝後無法分割的解決方法
Jan 02, 2024 am 09:17 AM
我們再重裝win10作業系統的時候,到了磁碟分割的步驟卻發現出現系統提示無法建立新的分割區也找不到現有分割區。對於這種情況小編覺得可以嘗試將整個硬碟重新進行格式化再次安裝系統進行分割區,或透過軟體重新進行系統安裝等等。具體內容就來看看小編是怎麼做的吧~希望可以幫助到你。安裝win10無法建立新的分割區怎麼辦方法一:格式化整個硬碟重新分割區或嘗試插拔U盤幾次並刷新,如果你的硬碟上沒有重要資料的話,到了分割區這一步時,將硬碟上的所有分割區都刪除了。重新格式化整個硬碟,然後重新分割區,再進行安裝就正常了。方法二:P
 詳解Linux Opt分區的設定方法
Mar 20, 2024 am 11:30 AM
詳解Linux Opt分區的設定方法
Mar 20, 2024 am 11:30 AM
LinuxOpt分區的設定方法及程式碼範例在Linux系統中,Opt分割區通常用於儲存可選軟體包和應用程式資料。合理設定Opt分割區可以有效管理系統資源,避免磁碟空間不足等問題。本文將詳細介紹如何設定LinuxOpt分區,並提供具體的程式碼範例。 1.確定分割空間大小首先,我們要確定Opt分割區所需的空間大小。一般建議將Opt分區的大小設定為系統總空間的5%-1
 如何在Windows 11中增加WinRE分割區大小
Feb 19, 2024 pm 06:06 PM
如何在Windows 11中增加WinRE分割區大小
Feb 19, 2024 pm 06:06 PM
在這篇文章中,我們將向您展示如何在Windows11/10中變更或增加WinRE分割區大小。微軟現在將在每月累積更新的同時更新Windows復原環境(WinRE),開始於Windows11版本22H2。然而,並非所有電腦都有足夠大的恢復分區以容納新的更新,這可能導致錯誤訊息出現。 Windows復原環境服務失敗如何在Windows11中增加WinRE分割區大小要在您的電腦上手動增加WinRE分割區大小,請執行下面提到的步驟。檢查並停用WinRE縮小作業系統分區建立新的復原分區確認分區並啟用WinRE
 win10分區整理的整數計算解決方法
Dec 30, 2023 pm 07:41 PM
win10分區整理的整數計算解決方法
Dec 30, 2023 pm 07:41 PM
在Windows分區時如果簡單地按照1GB=1024MB的方式輸入計算出來的值的話,最終總是只能得到類似259.5GB/59.99GB/60.01GB這樣結果,而不是整數,那麼win10分區整數是如何計算的呢?下面跟小編一起來看看吧。 win10分區整數計算的公式:1、公式為:(X-1)×4+1024×X=Y。 2.想要得到Windows的整數分割區必須知道一個公式,透過這個公式算出的值才能被Windows認成整數GB的值。 3.其中,X就是想要得到的整數分區的數值,單位是GB,Y是分割時應該輸入的數
 深度Linux硬碟分割區及安裝教學:一步步實現系統的高效部署
Feb 10, 2024 pm 07:06 PM
深度Linux硬碟分割區及安裝教學:一步步實現系統的高效部署
Feb 10, 2024 pm 07:06 PM
在進行深度Linux的安裝之前,我們需要對硬碟進行分區,硬碟分區是將一塊實體硬碟劃分為多個邏輯區域的過程,每個區域可以獨立使用和管理,正確的分區方式可以提高系統的效能和穩定性,因此這一步非常重要,本文將為您提供詳細的深度Linux硬碟分割區及安裝教學。準備工作1.確保您已經備份了重要的數據,因為分割過程會清除硬碟上的所有資料。 2.準備一個深度Linux的安裝媒介,例如USB或光碟。硬碟分區1.開機進入BIOS設置,將啟動媒介設定為首選啟動設備。 2.重啟計算機,從啟動媒介引導進入系統安裝介面。 3.選擇
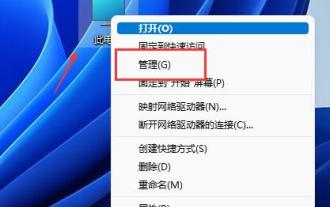 Win11怎麼分割區硬碟分割區? win11磁碟怎麼分割硬碟教學
Feb 19, 2024 pm 06:01 PM
Win11怎麼分割區硬碟分割區? win11磁碟怎麼分割硬碟教學
Feb 19, 2024 pm 06:01 PM
不少的用戶覺得系統預設的分區空間太小了,那麼Win11如何分區硬碟分區?使用者可以直接的點擊此電腦下的管理,然後點擊磁碟管理來進行操作設定就可以了。下面就讓本站來為用戶們來仔細的介紹一下win11磁碟怎麼分區硬碟教學吧。 win11磁碟怎麼分割硬碟教學1、先右鍵此電腦,開啟電腦管理。 3.然後查看右側磁碟狀況,是否有可用空間。 (如果有可用空間就跳到第6步)。 5、然後選擇需要騰出的空間量,點選壓縮。 7.再輸入想要的簡單磁碟大小,點選下一頁。 9.最後點擊完成就可以建立新的分區了。
