

sql distinct使用方法

本文章来给各位朋友介绍distinct用法及distinct在使用过程中一些常用见问题总结,有需要了解distinct用法的朋友可参考参考。
SQL SELECT DISTINCT 语句
在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。
关键词 DISTINCT 用于返回唯一不同的值。
语法:
SELECT DISTINCT 列名称 FROM 表名称
如需从 Company" 列中仅选取唯一不同的值,我们需要使用 SELECT DISTINCT 语句:
| 代码如下 | 复制代码 |
|
SELECT DISTINCT Company FROM Orders |
|
distinct 关键字失效的办法
用distinct关键字只能过滤查询字段中所有记录相同的(记录集相同),而如果要指定一个字段却没有效果,另外
distinct关键字会排序,效率很低。
distinct name from t1 能消除重复记录,但只能取一个字段,现在要同时取id,name这2个字段的值。
select distinct id,name from t1 可以取多个字段,但只能消除这2个字段值全部相同的记录
所以用distinct达不到想要的效果,用 可以解决这个问题。
例如要显示的字段为A、B、C三个,而A字段的内容不能重复可以用下面的语句:
| 代码如下 | 复制代码 |
| select A, min(B),min(C),count(*) from [table] where [条件] group by A having [条件] order by A desc |
|
为了显示标题头好看点可以把select A, min(B),min(C),count(*) 换称select A as A, min(B) as B,min(C) as
C,count(*) as 重复次数
显示出来的字段和排序字段都要包括在group by 中
但显示出来的字段包有min,max,count,avg,sum等聚合函数时可以不在group by 中
如上句的min(B),min(C),count(*)
一般条件写在where 后面
有聚合函数的条件写在having 后面
如果在上句中having加 count(*)>1 就可以查出记录A的重复次数大于1的记录
如果在上句中having加 count(*)>2 就可以查出记录A的重复次数大于2的记录
如果在上句中having加 count(*)>=1 就可以查出所有的记录,但重复的只显示一条,并且后面有显示重复的次数-
---这就是所需要的结果,而且语句可以通过hibernate
下面语句可以查询出那些数据是重复的:
select 字段1,字段2,count(*) from 表名 group by 字段1,字段2 having count(*) > 1
将上面的>号改为=号就可以查询出没有重复的数据了。
例如
| 代码如下 | 复制代码 |
|
select count(*) from (select gcmc,gkrq,count(*) from gczbxx_zhao t group by gcmc,gkrq having count(*)>=1 order by GKRQ) 推荐使用: select * from gczbxx_zhao where viewid in ( select max(viewid) from gczbxx_zhao group by gcmc ) order by gkrq desc |
|

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 MySQL中的distinct與group by如何使用
May 26, 2023 am 10:34 AM
MySQL中的distinct與group by如何使用
May 26, 2023 am 10:34 AM
先說大致的結論:在語意相同,有索引的情況下:groupby和distinct都能使用索引,效率相同。在語意相同,無索引的情況下:distinct效率高於groupby。原因是distinct和groupby都會進行分組操作,但groupby可能會進行排序,觸發filesort,導致sql執行效率低。基於這個結論,你可能會問:為什麼在語意相同,有索引的情況下,groupby和distinct效率相同?在什麼情況下,groupby會進行排序操作?帶著這兩個問題找出答案。接下來,我們先來看看dist
 mysql的DISTINCT怎麼使用
Jun 03, 2023 pm 05:56 PM
mysql的DISTINCT怎麼使用
Jun 03, 2023 pm 05:56 PM
mysql的DISTINCT的關鍵字有很多你想不到的用處1.在count不重複的記錄的時候能用到比如SELECTCOUNT(DISTINCTid)FROMtablename;就是計算talbebname表中id不同的記錄有多少條2,在需要返回記錄不同的id的具體值的時候可以用例如SELECTDISTINCTidFROMtablename;返回talbebname表中不同的id的具體的值3.上面的情況2對於需要返回mysql表中2列以上的結果時會有歧義比如SELECTDISTINCTid,type
 oracle的distinct用法是什麼
Jul 11, 2023 am 09:35 AM
oracle的distinct用法是什麼
Jul 11, 2023 am 09:35 AM
oracle的distinct用法是可以過濾結果集中的重複行,確保「SELECT」子句中傳回指定的一列或多列的值是唯一的。其語法為“SELECT DISTINCT 欄1,列2,列3... from 表名”,“distinct”會對傳回的結果集進行排序,可以和“order by”結合使用,提高效率。
 解析SQL中使用distinct關鍵字
Feb 18, 2024 pm 09:21 PM
解析SQL中使用distinct關鍵字
Feb 18, 2024 pm 09:21 PM
SQL中distinct用法詳解在SQL資料庫中,我們常常會遇到需要移除重複資料的情況。此時,我們可以使用distinct關鍵字,它能夠幫助我們去除重複數據,使得查詢結果更加清晰和準確。 distinct的基本使用方法非常簡單,只需要在select語句中使用distinct關鍵字即可。例如,以下是一個普通的select語句:SELECTcolumn_name
 如何透過MySQL對DISTINCT優化來提高效能
May 11, 2023 am 08:12 AM
如何透過MySQL對DISTINCT優化來提高效能
May 11, 2023 am 08:12 AM
MySQL是目前應用廣泛的關聯式資料庫之一。在大數據量儲存與查詢中,最佳化資料庫效能是至關重要的。其中,DISTINCT是常用的去重查詢運算子。本文將介紹如何透過MySQL對DISTINCT最佳化來提高資料庫查詢效能。一、DISTINCT的原理及缺點DISTINCT關鍵字用於從查詢結果中移除重複行。在大量資料的情況下,查詢中可能存在多個重複值,導致輸出資料冗餘,
 SQL中的distinct用法
Jan 26, 2024 pm 03:14 PM
SQL中的distinct用法
Jan 26, 2024 pm 03:14 PM
SQL中的DISTINCT是一個關鍵字,用於查詢不重複的結果集,可以用於SELECT語句、COUNT聚合函數等語句中,基本語法為“SELECT DISTINCT column1, column2”,其中DISTINCT關鍵字放在SELECT關鍵字之後,緊接在後的是要查詢的列名或表達式,中間用逗號分隔。
 SQL中distinct用法
Jan 25, 2024 am 11:52 AM
SQL中distinct用法
Jan 25, 2024 am 11:52 AM
SQL中DISTINCT關鍵字用於從查詢結果中去除重複的行,可以應用於SELECT語句中的一個或多個列,以返回唯一的值組合,使用方法為”SELECT DISTINCT column1, column2, ...“ ,DISTINCT關鍵字作用於所有指定的列,如果多列組合在一起產生了不同的結果,那麼這些行也將被視為不同,並且不會被去重。
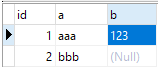 mysql踩坑之count distinct多列問題怎麼解決
Jun 03, 2023 am 10:49 AM
mysql踩坑之count distinct多列問題怎麼解決
Jun 03, 2023 am 10:49 AM
重複的測試資料庫如下所示:CREATETABLE`test_distinct`(`id`int(11)NOTNULLAUTO_INCREMENT,`a`varchar(50)CHARACTERSETutf8DEFAULTNULL,`b`varchar(50)CHARACTERSETutf8DEFAULTN InnoDBAUTO_INCREMENT=1DEFAULTCHARSET=latin1;表內測試資料如下,現在我們需要統計這三列去重後的列
