
上次介紹了怎麼利用NodeJS PhantomJS進行截圖,但由於對每次截圖操作,都啟用了一個PhantomJS進程,所以並發量上去後,效率堪憂,所以我們重寫了所有代碼,並將其獨立成為一個模組,方便調用。
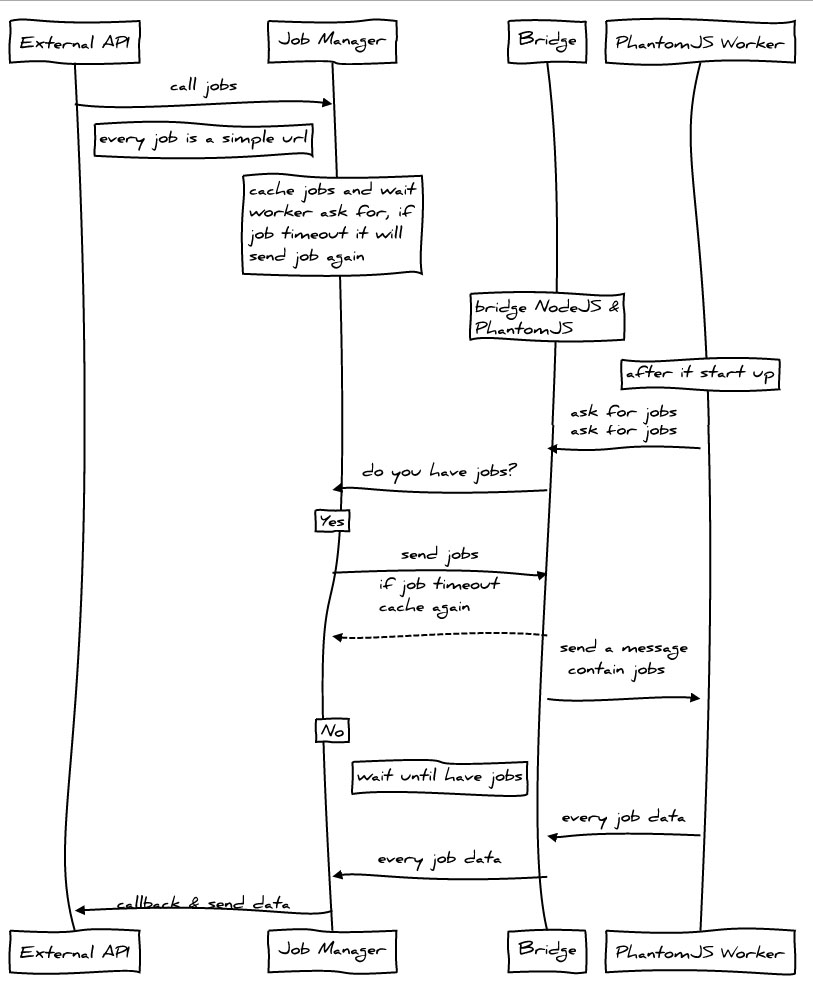
如何改進? 控制線程數,以及單線程處理url數量。使用Standard Output & WebSocket 進行通訊。新增快取機制,目前使用Javascript Object。對外提供簡易的介面。
設計圖
依賴 & 安裝
由於PhantomJS 1.9.0 才開始支援Websocket,所以我們先要確定在PATH中的PhantomJS是為1.9.0以上版本。在命令列鍵入:
$ phantomjs -v
如果能回傳版本號1.9.x,則可以繼續操作。如果版本過低,或發生錯誤,請到PhantomJS官網下載最新版本。
如果你已經安裝了Git,或是擁有Git Shell,那麼在命令列鍵入:
$ npm install url-extract
進行安裝。
一個簡單的例子
例如我們要截取百度首頁,那麼可以這樣:
下面是列印:

其中,image屬性就是截圖相對於工作路徑的位址。我們可以使用Job的getData介面來得到更清楚的數據,例如:
程式碼如下:
module.exports = (function () { "use strict" var urlExtract = require('url-extract'); urlExtract.snapshot('http://www.baidu.com', function (job) { console.log ('This is a snapshot example.'); console.log(job.getData()); process.exit(); }); })(); 
image表示截圖相對於工作路徑的位址,status表示狀態是否正常,true代表正常,false代表截圖失敗。
更多範例請見:
https://github.com/miniflycn/url-extract/tree/master/examples主要API
.snapshot
複製程式碼 程式碼如下: url {String} 要截取的位址urls {Array} 要截取的位址位址數組callback {Function} 回呼函數option {Object} 可選參數┝ id {String} 自訂url的id,如果第一個參數是urls,此參數無效┝ image {String} 自訂截圖的儲存位址,如果第一個參數是urls,此參數無效┝ groupId {String} 定義一組url的groupId,用於返回時候辨認是哪一組url ┝ ignoreCache {Boolean} 是否忽略快取┗ callback {Function} 回呼函數.extract
URL 情報を取得し、スナップショットを取得します
.extract(url, [callback]).extract(urls, [callback]).extract(url, [option]).extract( urls, [オプション])url {String} 傍受されるアドレス
urls {Array} インターセプトするアドレスの配列
callback {Function} コールバック関数
オプション {Object} オプションのパラメータ
┝ id {String} 最初のパラメータが url の場合、このパラメータは無効です。
┝ image {String} 最初のパラメータが url の場合、このパラメータは無効です。
┝ groupId {String} は、URL のグループの groupId を定義します。
を返すときに、それが URL のどのグループであるかを識別するために使用されます。┝ignoreCache {Boolean} キャッシュを無視するかどうか
┗ コールバック {関数} コールバック関数
ジョブ (クラス)
各 URL はジョブ オブジェクトに対応し、ジョブ オブジェクトには URL の関連情報が格納されます。
フィールド
url {String} リンク アドレス content {Boolean} ページのタイトルと説明情報をクロールするかどうか id {String} ジョブの idgroupId {String} 一連のジョブのグループ ID キャッシュ {Boolean} キャッシュ コールバックを有効にするかどうか {Function}コールバック関数 image {String} 画像アドレスのステータス {Boolean} ジョブが現在正常かどうかプロトタイプ
getData() はジョブ関連データを取得しますグローバル構成
url-extract のルート ディレクトリにある設定ファイルはグローバルに設定できます:
module.exports = { wsPort: 3001, maxJob: 100, maxQueueJob: 400, cache: 'object', maxCache: 10000, workerNum: 0};登入後複製wsPort {Number} WebSocket が占有するポート アドレス maxJob {Number} 各 PhantomJS スレッドが持つことができる同時ワーカーの数 maxQueueJob {Number} 待機中のジョブの最大数。0 は制限がないことを意味します。この数を超えると、任意のジョブが実行されます。直接失敗に戻ります (つまり、status = false) キャッシュ {String} キャッシュの実装、現在はオブジェクトのみが実装されています maxCache {Number} キャッシュ リンクの最大数 workNum {Number} PhantomJS スレッド番号、0 は CPU の数と同じを意味します簡単なサービス例
https://github.com/miniflycn/url-extract-server-example
connect と url-extract をインストールする必要があることに注意してください:
$ npm install
ネットワーク ディスク ファイルをダウンロードした場合は、connect をインストールしてください:
$ npm install connect
次に、次のように入力します:
$ ノード bin/サーバー
開く:
効果を確認します。
;






















