

用Python编写一个简单的Lisp解释器的教程

本文有两个目的: 一是讲述实现计算机语言解释器的通用方法,另外一点,着重展示如何使用Python来实现Lisp方言Scheme的一个子集。我将我的解释器称之为Lispy (lis.py)。几年前,我介绍过如何使用Java编写一个Scheme解释器,同时我还使用Common Lisp语言编写过一个版本。这一次,我的目的是尽可能简单明了地演示一下Alan Kay所说的“软件的麦克斯韦方程组” (Maxwell's Equations of Software)。
Lispy支持的Scheme子集的语法和语义
大多数计算机语言都有许多语法规约 (例如关键字、中缀操作符、括号、操作符优先级、点标记、分号等等),但是,作为Lisp语言家族中的一员,Scheme所有的语法都是基于包含在括号中的、采用前缀表示的列表的。这种表示看起来似乎有些陌生,但是它具有简单一致的优点。 (一些人戏称”Lisp”是”Lots of Irritating Silly Parentheses“——“大量恼人、愚蠢的括号“——的缩写;我认为它是”Lisp Is Syntactically Pure“——“Lisp语法纯粹”的缩写。) 考虑下面这个例子:
/* Java */
if(x.val() > 0) {
z = f(a*x.val() + b);
}
/* Scheme */
(if (> (val x) 0)
(set! z (f (+ (* a (val x)) b))))
注意上面的惊叹号在Scheme中并不是一个特殊字符;它只是”set!“这个名字的一部分。(在Scheme中)只有括号是特殊字符。类似于(set! x y)这样以特殊关键字开头的列表在Scheme中被称为一个特殊形式 (special form);Scheme的优美之处就在于我们只需要六种特殊形式,以及另外的三种语法构造——变量、常量和过程调用。
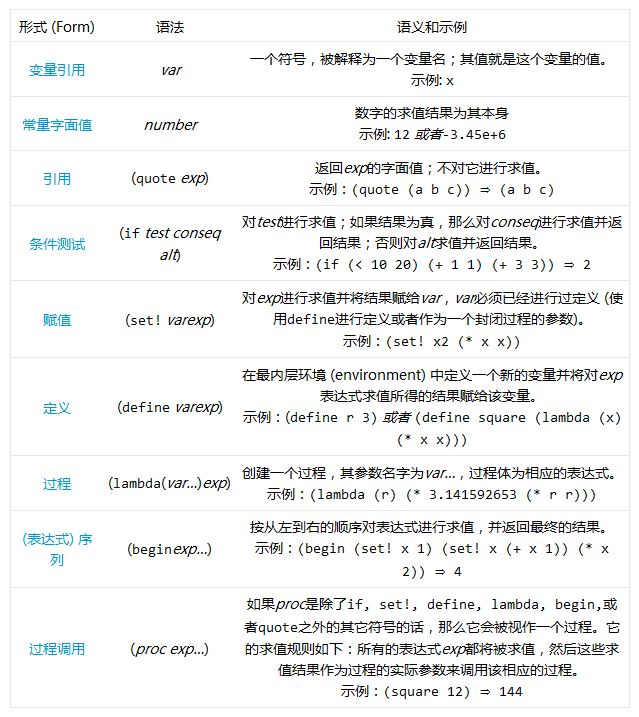
在该表中,var必须是一个符号——一个类似于x或者square这样的标识符——number必须是一个整型或者浮点型数字,其余用斜体标识的单词可以是任何表达式。exp…表示exp的0次或者多次重复。
更多关于Scheme的内容,可以参考一些优秀的书籍 (如Friedman和Fellesein, Dybvig,Queinnec, Harvey和Wright或者Sussman和Abelson)、视频 (Abelson和Sussman)、教程 (Dorai、PLT或者Neller)、或者参考手册。
语言解释器的职责
一个语言解释器包括两部分:
1、解析 (Parsing):解析部分接受一个使用字符序列表示的输入程序,根据语言的语法规则对输入程序进行验证,然后将程序翻译成一种中间表示。在一个简单的解释器中,中间表示是一种树结构,紧密地反映了源程序中语句或表达式的嵌套结构。在一种称为编译器的语言翻译器中,内部表示是一系列可以直接由计算机 (作者的原意是想说运行时系统——译者注) 执行的指令。正如Steve Yegge所说,“如果你不明白编译器的工作方式,那么你不会明白计算机的工作方式。”Yegge介绍了编译器可以解决的8种问题 (或者解释器,又或者采用Yegge的典型的反讽式的解决方案)。 Lispy的解析器由parse函数实现。
2、执行:程序的内部表示 (由解释器) 根据语言的语义规则进行进一步处理,进而执行源程序的实际运算。(Lispy的)执行部分由eval函数实现 (注意,该函数覆盖了Python内建的同名函数)。
下面的图片描述了解释器的解释流程,(图片后的) 交互会话展示了parse和eval函数对一个小程序的操作方式:

这里,我们采用了一种尽可能简单的内部表示,其中Scheme的列表、数字和符号分别使用Python的列表、数字和字符串来表示。
执行: eval
下面是eval函数的定义。对于上面表中列出的九种情况,每一种都有一至三行代码,eval函数的定义只需要这九种情况:
def eval(x, env=global_env): "Evaluate an expression in an environment." if isa(x, Symbol): # variable reference return env.find(x)[x] elif not isa(x, list): # constant literal return x elif x[0] == 'quote': # (quote exp) (_, exp) = x return exp elif x[0] == 'if': # (if test conseq alt) (_, test, conseq, alt) = x return eval((conseq if eval(test, env) else alt), env) elif x[0] == 'set!': # (set! var exp) (_, var, exp) = x env.find(var)[var] = eval(exp, env) elif x[0] == 'define': # (define var exp) (_, var, exp) = x env[var] = eval(exp, env) elif x[0] == 'lambda': # (lambda (var*) exp) (_, vars, exp) = x return lambda *args: eval(exp, Env(vars, args, env)) elif x[0] == 'begin': # (begin exp*) for exp in x[1:]: val = eval(exp, env) return val else: # (proc exp*) exps = [eval(exp, env) for exp in x] proc = exps.pop(0) return proc(*exps) isa = isinstance Symbol = str
eval函数的定义就是这么多…当然,除了environments。Environments (环境) 只是从符号到符号所代表的值的映射而已。一个新的符号/值绑定由一个define语句或者一个过程定义 (lambda表达式) 添加。
让我们通过一个例子来观察定义然后调用一个Scheme过程的时候所发生的事情 (lis.py>提示符表示我们正在与Lisp解释器进行交互,而不是Python):
lis.py> (define area (lambda (r) (* 3.141592653 (* r r)))) lis.py> (area 3) 28.274333877
当我们对(lambda (r) (* 3.141592653 (* r r)))进行求值时,我们在eval函数中执行elif x[0] == 'lambda'分支,将(_, vars, exp)三个变量分别赋值为列表x的对应元素 (如果x的长度不是3,就抛出一个错误)。然后,我们创建一个新的过程,当该过程被调用的时候,将会对表达式['*', 3.141592653 ['*', 'r', 'r']]进行求值,该求值过程的环境 (environment) 是通过将过程的形式参数 (该例中只有一个参数,r) 绑定为过程调用时所提供的实际参数,外加当前环境中所有不在参数列表 (例如,变量*) 的变量组成的。新创建的过程被赋值给global_env中的area变量。
那么,当我们对(area 3)求值的时候发生了什么呢?因为area并不是任何表示特殊形式的符号之一,它必定是一个过程调用 (eval函数的最后一个else:分支),因此整个表达式列表都将会被求值,每次求值其中的一个。对area进行求值将会获得我们刚刚创建的过程;对3进行求值所得的结果就是3。然后我们 (根据eval函数的最后一行) 使用参数列表[3]来调用这个新创建的过程。也就是说,对exp(也就是['*', 3.141592653 ['*', 'r', 'r']])进行求值,并且求值所在的环境中r的值是3,并且外部环境是全局环境,因此*是乘法过程。
现在,我们可以解释一下Env类的细节了:
class Env(dict):
"An environment: a dict of {'var':val} pairs, with an outer Env."
def __init__(self, parms=(), args=(), outer=None):
self.update(zip(parms,args))
self.outer = outer
def find(self, var):
"Find the innermost Env where var appears."
return self if var in self else self.outer.find(var)
注意Env是dict的一个子类,也就是说,通常的字典操作也适用于Env类。除此之外,该类还有两个方法,构造函数__init__和find函数,后者用来为一个变量查找正确的环境。理解这个类的关键 (以及我们需要一个类,而不是仅仅使用dict的根本原因) 在于外部环境 (outer environment) 这个概念。考虑下面这个程序:
(define make-account (lambda (balance) (lambda (amt) (begin (set! balance (+ balance amt)) balance)))) (define a1 (make-account 100.00)) (a1 -20.00)
每个矩形框都代表了一个环境,并且矩形框的颜色与环境中最新定义的变量的颜色相对应。在程序的最后两行我们定义了a1并且调用了(a1 -20.00);这表示创建一个开户金额为100美元的银行账户,然后是取款20美元。在对(a1 -20.00)求值的过程中,我们将会对黄色高亮表达式进行求值,该表达式中具有三个变量。amt可以在最内层 (绿色) 环境中直接找到。但是balance在该环境中没有定义:我们需要查看绿色环境的外层环境,也就是蓝色环境。最后,+代表的变量在这两个环境中都没有定义;我们需要进一步查看外层环境,也就是全局 (红色) 环境。先查找内层环境,然后依次查找外部的环境,我们把这一过程称之为词法定界 (lexical scoping)。Procedure.find负责根据词法定界规则查找正确的环境。
剩下的就是要定义全局环境。该环境需要包含+过程以及所有其它Scheme的内置过程。我们并不打算实现所有的内置过程,但是,通过导入Python的math模块,我们可以获得一部分这些过程,然后我们可以显式地添加20种常用的过程:
def add_globals(env):
"Add some Scheme standard procedures to an environment."
import math, operator as op
env.update(vars(math)) # sin, sqrt, ...
env.update(
{'+':op.add, '-':op.sub, '*':op.mul, '/':op.div, 'not':op.not_,
'>':op.gt, '<':op.lt, '>=':op.ge, '<=':op.le, '=':op.eq,
'equal?':op.eq, 'eq?':op.is_, 'length':len, 'cons':lambda x,y:[x]+y,
'car':lambda x:x[0],'cdr':lambda x:x[1:], 'append':op.add,
'list':lambda *x:list(x), 'list?': lambda x:isa(x,list),
'null?':lambda x:x==[], 'symbol?':lambda x: isa(x, Symbol)})
return env
global_env = add_globals(Env())
PS1: 对麦克斯韦方程组的一种评价是“一般地,宇宙间任何的电磁现象,皆可由此方程组解释”。Alan Kay所要表达的,大致就是Lisp语言使用自身定义自身 (Lisp was “defined in terms of Lisp”) 这种自底向上的设计对软件设计而言具有普遍的参考价值。——译者注
解析 (Parsing): read和parse
接下来是parse函数。解析通常分成两个部分:词法分析和语法分析。前者将输入字符串分解成一系列的词法单元 (token);后者将词法单元组织成一种中间表示。Lispy支持的词法单元包括括号、符号 (如set!或者x) 以及数字 (如2)。它的工作形式如下:
>>> program = "(set! x*2 (* x 2))"
>>> tokenize(program)
['(', 'set!', 'x*2', '(', '*', 'x', '2', ')', ')']
>>> parse(program)
['set!', 'x*2', ['*', 'x', 2]]
有许多工具可以进行词法分析 (例如Mike Lesk和Eric Schmidt的lex)。但是我们将会使用一个非常简单的工具:Python的str.split。我们只是在 (源程序中) 括号的两边添加空格,然后调用str.split来获得一个词法单元的列表。
接下来是语法分析。我们已经看到,Lisp的语法很简单。但是,一些Lisp解释器允许接受表示列表的任何字符串作为一个程序,从而使得语法分析的工作更加简单。换句话说,字符串(set! 1 2)可以被接受为是一个语法上有效的程序,只有当执行的时候解释器才会抱怨set!的第一个参数应该是一个符号,而不是数字。在Java或者Python中,与之等价的语句1 = 2将会在编译时被认定是错误。另一方面,Java和Python并不需要在编译时检测出表达式x/0是一个错误,因此,如你所见,一个错误应该何时被识别并没有严格的规定。Lispy使用read函数来实现parse函数,前者用以读取任何的表达式 (数字、符号或者嵌套列表)。
tokenize函数获取一系列词法单元,read通过在这些词法单元上调用read_from函数来进行工作。给定一个词法单元的列表,我们首先查看第一个词法单元;如果它是一个')',那么这是一个语法错误。如果它是一个'(‘,那么我们开始构建一个表达式列表,直到我们读取一个匹配的')'。所有其它的 (词法单元) 必须是符号或者数字,它们自身构成了一个完整的列表。剩下的需要注意的就是要了解'2‘代表一个整数,2.0代表一个浮点数,而x代表一个符号。我们将区分这些情况的工作交给Python去完成:对于每一个不是括号也不是引用 (quote) 的词法单元,我们首先尝试将它解释为一个int,然后尝试float,最后尝试将它解释为一个符号。根据这些规则,我们得到了如下程序:
def read(s):
"Read a Scheme expression from a string."
return read_from(tokenize(s))
parse = read
def tokenize(s):
"Convert a string into a list of tokens."
return s.replace('(',' ( ').replace(')',' ) ').split()
def read_from(tokens):
"Read an expression from a sequence of tokens."
if len(tokens) == 0:
raise SyntaxError('unexpected EOF while reading')
token = tokens.pop(0)
if '(' == token:
L = []
while tokens[0] != ')':
L.append(read_from(tokens))
tokens.pop(0) # pop off ')'
return L
elif ')' == token:
raise SyntaxError('unexpected )')
else:
return atom(token)
def atom(token):
"Numbers become numbers; every other token is a symbol."
try: return int(token)
except ValueError:
try: return float(token)
except ValueError:
return Symbol(token)
最后,我们将要添加一个函数to_string,用来将一个表达式重新转换成Lisp可读的字符串;以及一个函数repl,该函数表示read-eval-print-loop (读取-求值-打印循环),用以构成一个交互式的Lisp解释器:
def to_string(exp):
"Convert a Python object back into a Lisp-readable string."
return '('+' '.join(map(to_string, exp))+')' if isa(exp, list) else str(exp)
def repl(prompt='lis.py> '):
"A prompt-read-eval-print loop."
while True:
val = eval(parse(raw_input(prompt)))
if val is not None: print to_string(val)
下面是函数工作的一个例子:
>>> repl() lis.py> (define area (lambda (r) (* 3.141592653 (* r r)))) lis.py> (area 3) 28.274333877 lis.py> (define fact (lambda (n) (if (<= n 1) 1 (* n (fact (- n 1)))))) lis.py> (fact 10) 3628800 lis.py> (fact 100) 9332621544394415268169923885626670049071596826438162146859296389521759999322991 5608941463976156518286253697920827223758251185210916864000000000000000000000000 lis.py> (area (fact 10)) 4.1369087198e+13 lis.py> (define first car) lis.py> (define rest cdr) lis.py> (define count (lambda (item L) (if L (+ (equal? item (first L)) (count item (rest L))) 0))) lis.py> (count 0 (list 0 1 2 3 0 0)) 3 lis.py> (count (quote the) (quote (the more the merrier the bigger the better))) 4
Lispy有多小、多快、多完备、多优秀?
我们使用如下几个标准来评价Lispy:
*小巧:Lispy非常小巧:不包括注释和空白行,其源代码只有90行,并且体积小于4K。(比第一个版本的体积要小,第一个版本有96行——根据Eric Cooper的建议,我删除了Procedure的类定义,转而使用Python的lambda。) 我用Java编写的Scheme解释器Jscheme最小的版本,其源代码也有1664行、57K。Jscheme最初被称为SILK (Scheme in Fifty Kilobytes——50KB的Scheme解释器),但是只有计算字节码而不是源代码的时候,我才能保证 (其体积) 小于该最小值。Lispy做的要好得多;我认为它满足了Alan Kay在1972年的断言:他声称我们可以使用“一页代码”来定义“世界上最强大的语言”。
bash$ grep "^\s*[^#\s]" lis.py | wc 90 398 3423
*高效:Lispy计算(fact 100)只需要0.004秒。对我来说,这已经足够快了 (虽然相比起其它的计算方式来说要慢很多)。
*完备:相比起Scheme标准来说,Lispy不是非常完备。主要的缺陷有:
(1) 语法:缺少注释、引用 (quote) / 反引用 (quasiquote) 标记 (即'和`——译者注)、#字面值 (例如#\a——译者注)、衍生表达式类型 (例如从if衍生而来的cond,或者从lambda衍生而来的let),以及点列表 (dotted list)。
(2) 语义:缺少call/cc以及尾递归。
(3) 数据类型:缺少字符串、字符、布尔值、端口 (ports)、向量、精确/非精确数字。事实上,相比起Scheme的pairs和列表,Python的列表更加类似于Scheme的向量。
(4) 过程:缺少100多个基本过程:与缺失数据类型相关的所有过程,以及一些其它的过程 (如set-car!和set-cdr!,因为使用Python的列表,我们无法完整实现set-cdr!)。
(5) 错误恢复:Lispy没有尝试检测错误、合理地报告错误以及从错误中恢复。Lispy希望程序员是完美的。
*优秀:这一点需要读者自己确定。我觉得,相对于我解释Lisp解释器这一目标而言,它已经足够优秀。
真实的故事
了解解释器的工作方式会很有帮助,有一个故事可以支持这一观点。1984年的时候,我在撰写我的博士论文。当时还没有LaTeX和Microsoft Word——我们使用的是troff。遗憾的是,troff中没有针对符号标签的前向引用机制:我想要能够撰写“正如我们将要在@theoremx页面看到的”,随后在合适的位置撰写”@(set theoremx \n%)” (troff寄存器\n%保存了页号)。我的同伴,研究生Tony DeRose也有着同样的需求,我们一起实现了一个简单的Lisp程序,使用这个程序作为一个预处理器来解决我们的问题。然而,事实证明,当时我们用的Lisp善于读取Lisp表达式,但在采用一次一个字符的方式读取非Lisp表达式时效率过低,以至于我们的这个程序很难使用。
在这个问题上,Tony和我持有不同的观点。他认为 (实现) 表达式的解释器是困难的部分;他需要Lisp为他解决这一问题,但是他知道如何编写一个短小的C过程来处理非Lisp字符,并知道如何将其链接进Lisp程序。我不知道如何进行这种链接,但是我认为为这种简单的语言编写一个解释器 (其所具有的只是设置变量、获取变量值和字符串连接) 很容易,于是我使用C语言编写了一个解释器。因此,戏剧性的是,Tony编写了一个Lisp程序,因为他是一个C程序员;我编写了一个C程序,因为我是一个Lisp程序员。
最终,我们都完成了我们的论文。
整个解释器
重新总结一下,下面就是Lispy的所有代码 (也可以从lis.py下载):
# -*- coding: UTF-8 -*- # 源代码略。以下纯属娱乐。。。 # 你想看完整源代码?真的想看? # 真的想看你就说嘛,又不是我编写的代码,你想看我总不能不让你看,对吧? # 真的想看的话就参考上述下载地址喽。。。LOL

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
