

從資料結構分析看:用for each...in 比 for...in 快一些_基礎知識

之前聽說火狐的JS引擎支援for each in的語法,例如下述的代碼:
var arr = [10,20,30,40,50];
for each(var k in arr)
console.log(k);
即可直接遍歷出arr數組的內容。
由於只有FireFox才支持,所以幾乎所有的JS程式碼都不用這個特徵。
不過在ActionScript裡天生就支援for each的語法,不論Array還是Vector,還是Dictionary,只要是可枚舉的物件都可以for in和for each in。
之前並沒有感覺有太大的差異,為了懶得敲一個each單詞,一直用熟悉的for in來遍歷。
不過今天仔細琢磨了會,從資料結構的角度分析了下,覺得for in和for each in效率上有著本質的區別,無論是JS還是AS。
原因很簡單:Array不是真正意義上的陣列!
何為真正意義的陣列?當然就是傳統語言裡type[]定義的資料類型,所有元素都是連續保存的。
「Array」雖然也是陣列的意思,但熟悉JS的都知道,它其實是個非線性的偽數組,下標可以是任意數字。寫入arr[1000000]並非真正申請容納一百萬個元素的空間,而是把1000000轉換成相應的哈希值,對應到很小一塊儲存空間裡,從而節省了大量內存。
例如有下列陣列:
];
arr[10] = 1000;
arr[20] = 2000;
arr[30] = 5000;
arr[40] = 8000; 9000;
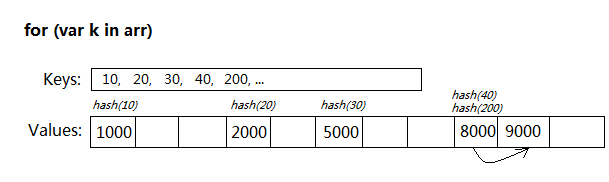
如果支援for each...in的語法,其內部的資料結構就決定了會快很多:
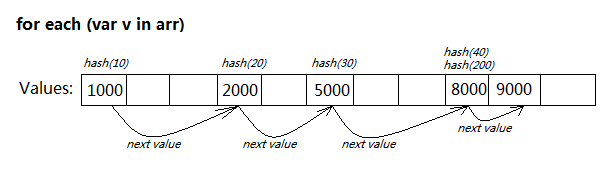
當for each...in遍歷時,只需從第一個節點往後迭代即可,無需任何Hash計算。
當然,對於AS3裡Vector這樣的線性陣列來說,兩者相差不大;同理,HTML5裡支援二進位的陣列ArrayBuffer也是如此。不過從理論上來看,即使arr是個連續的線性數組,for each in還是要快一點:
for...in遍歷時,每次訪問arr[k]都要進行下標越界檢查;而for each in則根據內部鍊錶,直接從底層反饋出迭代變量,節省了越界檢查的過程。

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 JavaScript引擎:比較實施
Apr 13, 2025 am 12:05 AM
JavaScript引擎:比較實施
Apr 13, 2025 am 12:05 AM
不同JavaScript引擎在解析和執行JavaScript代碼時,效果會有所不同,因為每個引擎的實現原理和優化策略各有差異。 1.詞法分析:將源碼轉換為詞法單元。 2.語法分析:生成抽象語法樹。 3.優化和編譯:通過JIT編譯器生成機器碼。 4.執行:運行機器碼。 V8引擎通過即時編譯和隱藏類優化,SpiderMonkey使用類型推斷系統,導致在相同代碼上的性能表現不同。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 JavaScript:探索網絡語言的多功能性
Apr 11, 2025 am 12:01 AM
JavaScript:探索網絡語言的多功能性
Apr 11, 2025 am 12:01 AM
JavaScript是現代Web開發的核心語言,因其多樣性和靈活性而廣泛應用。 1)前端開發:通過DOM操作和現代框架(如React、Vue.js、Angular)構建動態網頁和單頁面應用。 2)服務器端開發:Node.js利用非阻塞I/O模型處理高並發和實時應用。 3)移動和桌面應用開發:通過ReactNative和Electron實現跨平台開發,提高開發效率。
 如何使用Next.js(前端集成)構建多租戶SaaS應用程序
Apr 11, 2025 am 08:22 AM
如何使用Next.js(前端集成)構建多租戶SaaS應用程序
Apr 11, 2025 am 08:22 AM
本文展示了與許可證確保的後端的前端集成,並使用Next.js構建功能性Edtech SaaS應用程序。 前端獲取用戶權限以控制UI的可見性並確保API要求遵守角色庫
 使用Next.js(後端集成)構建多租戶SaaS應用程序
Apr 11, 2025 am 08:23 AM
使用Next.js(後端集成)構建多租戶SaaS應用程序
Apr 11, 2025 am 08:23 AM
我使用您的日常技術工具構建了功能性的多租戶SaaS應用程序(一個Edtech應用程序),您可以做同樣的事情。 首先,什麼是多租戶SaaS應用程序? 多租戶SaaS應用程序可讓您從唱歌中為多個客戶提供服務
 從C/C到JavaScript:所有工作方式
Apr 14, 2025 am 12:05 AM
從C/C到JavaScript:所有工作方式
Apr 14, 2025 am 12:05 AM
從C/C 轉向JavaScript需要適應動態類型、垃圾回收和異步編程等特點。 1)C/C 是靜態類型語言,需手動管理內存,而JavaScript是動態類型,垃圾回收自動處理。 2)C/C 需編譯成機器碼,JavaScript則為解釋型語言。 3)JavaScript引入閉包、原型鍊和Promise等概念,增強了靈活性和異步編程能力。
 JavaScript和Web:核心功能和用例
Apr 18, 2025 am 12:19 AM
JavaScript和Web:核心功能和用例
Apr 18, 2025 am 12:19 AM
JavaScript在Web開發中的主要用途包括客戶端交互、表單驗證和異步通信。 1)通過DOM操作實現動態內容更新和用戶交互;2)在用戶提交數據前進行客戶端驗證,提高用戶體驗;3)通過AJAX技術實現與服務器的無刷新通信。
 JavaScript在行動中:現實世界中的示例和項目
Apr 19, 2025 am 12:13 AM
JavaScript在行動中:現實世界中的示例和項目
Apr 19, 2025 am 12:13 AM
JavaScript在現實世界中的應用包括前端和後端開發。 1)通過構建TODO列表應用展示前端應用,涉及DOM操作和事件處理。 2)通過Node.js和Express構建RESTfulAPI展示後端應用。
