

用於精確目標偵測的多網格冗餘邊界框標註

一、前言
目前領先的目標偵測器是基於深度CNN的主幹分類器網路重新調整用途的兩級或單級網路。 YOLOv3就是這樣一種眾所周知的最先進的單級檢測器,它接收輸入圖像並將其劃分為大小相等的網格矩陣。具有目標中心的網格單元負責偵測特定目標。
今天分享的,就是提出了一種新的數學方法,該方法為每個目標分配多個網格,以實現精確的tight-fit邊界框預測。研究者也提出了一種有效的離線複製貼上資料增強來進行目標偵測。新提出的方法顯著優於一些目前最先進的目標偵測器,並有望獲得更好的效能。
二、背景
目標偵測網路旨在使用精確匹配邊界框在影像上定位物件並準確標記它們。最近,有兩種不同的方法可以實現這一目標。第一種方法是效能方面,最主要的方法是兩階段目標檢測,最好的代表是區域卷積神經網路(RCNN)及其衍生物[Faster R-CNN: Towards real-time object detection with region proposal networks]、[Fast R-CNN]。相比之下,第二組目標檢測實現的因其出色的檢測速度和輕量級而被人們所知,被稱為單階段網絡,代表性示例為[You only look once: Unified, real-time object detection]、[SSD: Single shot multibox detector]、[Focal loss for dense object detection]。兩階段網絡依賴於一個潛在的區域建議網絡,該網絡生成了可能包含感興趣對象的圖像的候選區域。此網路產生的候選區域可以包含物件感興趣的區域,在單階段目標偵測中,偵測是在一個完整的前向傳遞中同時處理分類和定位。因此,通常情況下,單階段網路更輕、更快且易於實現。

今天的研究依然是堅持YOLO的方法,特別是YOLOv3,並提出了一種簡單的hack,可以同時使用多個網絡單元元素預測目標座標、類別和目標置信度。每個物件的多網路單元元素背後的基本原理是透過強制多個單元元素在同一物件上工作來增加預測緊密擬合邊界框的可能性。

多重網格指派的一些優點包括:
目標偵測器提供它正在偵測的物件的多視角圖,而不僅僅依靠一個網格單元來預測物件的類別和座標。
(b ) 較少隨機且不確定的邊界框預測,這意味著高精度和召回率,因為附近的網路單元被訓練來預測相同的目標類別和座標;
(c) 減少具有感興趣物件的網格單元與沒有感興趣物件的網格之間的不平衡。
此外,由於多網格分配是對現有參數的數學利用,並且不需要額外的關鍵點池化層和後處理來將關鍵點重新組合到其對應的目標,如CenterNet和CornerNet,可以說它是一個更實現無錨或基於關鍵點的目標偵測器試圖實現的自然方式。除了多網格冗餘註釋,研究者還引入了一種新的基於離線複製貼上的資料增強技術,用於準確的目標檢測。
三、MULTI-GRID ASSIGNMENT

#上圖包含三個目標,分別是狗狗、腳踏車和汽車。為簡潔起見,我們將解釋我們在一個物件上的多網格分配。上圖顯示了三個物件的邊界框,其中包含更多關於狗的邊界框的細節。下圖顯示了上圖的縮小區域,重點是狗的邊界框中心。包含狗邊界框中心的網格單元的左上角座標以數字0標記,而包含中心的網格周圍的其他八個網格單元的標籤從1到8。

到目前為止,我已經解釋了包含目標邊界框中心的網格如何註釋目標的基本事實。這種對每個物件僅一個網格單元的依賴來完成預測類別的困難工作和精確的tight-fit邊界框引發了許多問題,例如:
(a)正負網格之間的巨大不平衡,即有和沒有物件中心的網格座標
(b)緩慢的邊界框收斂到GT
(c)缺乏要預測的物件的多視角(角度)視圖。
所以這裡要問的一個自然問題是,「顯然,大多數物件包含一個以上網格單元的區域,因此是否有一種簡單的數學方法來分配更多這些網格單元來嘗試預測物件的類別和座標連同中心網格單元?這樣做的一些優點是(a)減少不平衡,(b)更快的訓練以收斂到邊界框,因為現在多個網格單元同時針對同一個對象,(c)增加預測tight-fit邊界框的機會(d) 為YOLOv3等基於網格的偵測器提供多視角視圖,而不是物件的單點視圖。新提出的多重網格分配試圖回答上述問題。
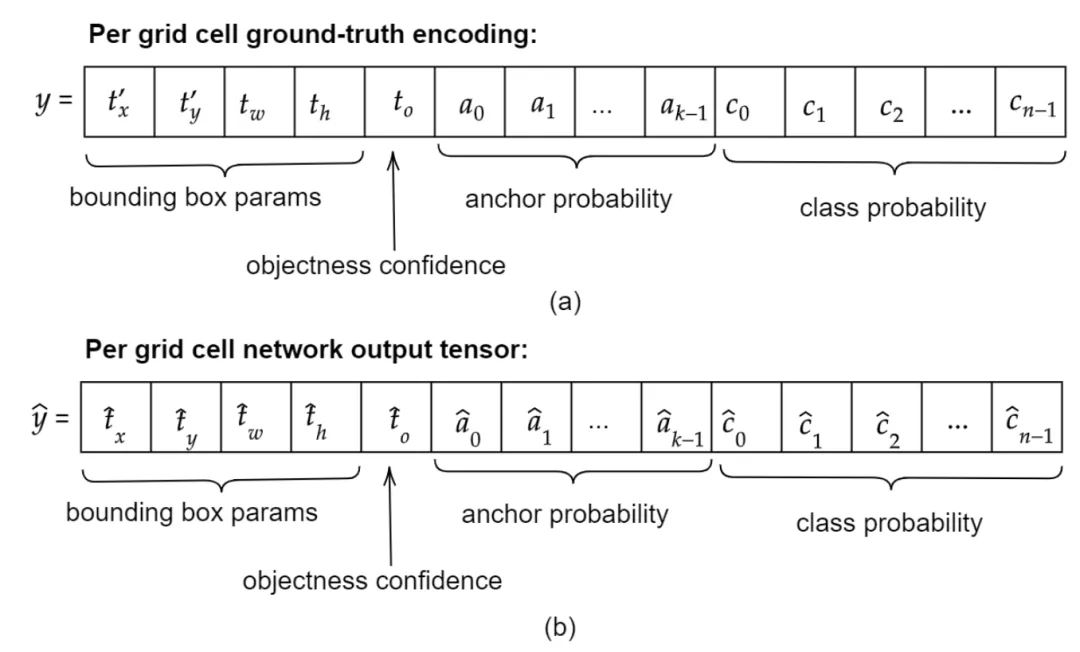
Ground-truth encoding
四、訓練
A. The Detection Network: MultiGridDet
MultiGridDet是一個目標檢測網絡,透過從YOLOv3中刪除六個darknet卷積塊來使其更輕、更快。一個卷積塊有一個Conv2D Batch Normalization LeakyRelu。移除的區塊不是來自分類主幹,即Darknet53。相反,將它們從三個多尺度檢測輸出網路或頭中刪除,每個輸出網路兩個。儘管通常深度網路表現良好,但太深的網路也往往會快速過度擬合或大幅降低網路速度。
B. The Loss function
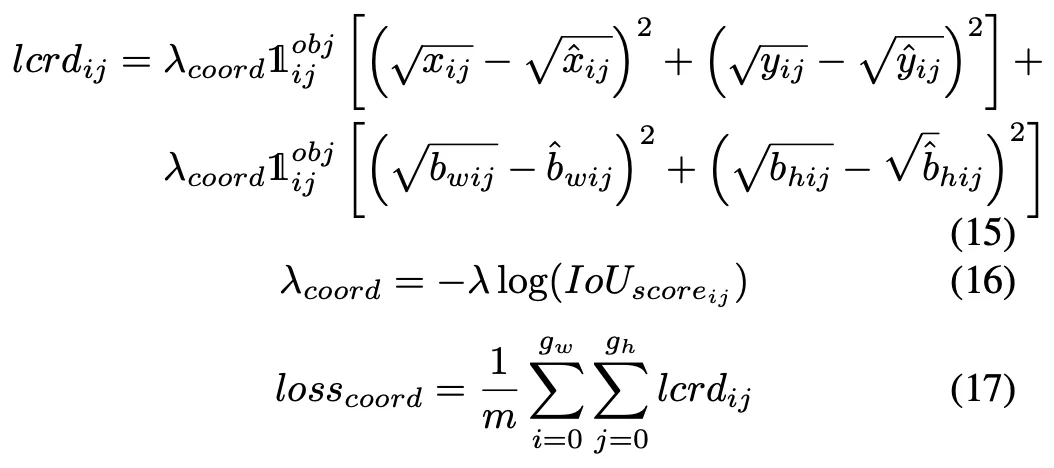
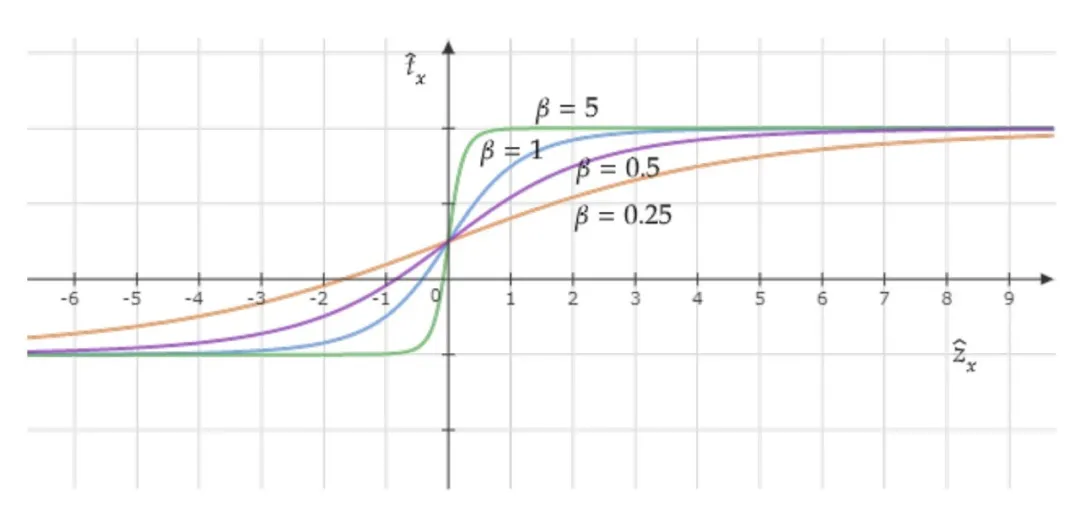
#Coordinate activation function plot with different β values
C. Data Augmentation
離線複製貼上人工訓練圖像合成工作如下:首先,使用簡單的圖像搜索腳本,使用地標、雨、森林等關鍵字從Google圖像下載數千張背景無物件圖像,即沒有我們感興趣的物件的圖像。然後,我們從整個訓練資料集的隨機q個影像中迭代地選擇p個物件及其邊界框。然後,我們產生使用它們的索引作為ID選擇的p個邊界框的所有可能組合。從組合集合中,我們選擇滿足以下兩個條件的邊界框子集:
- if arranged in some random order side by side, they must fit within a given target background image area
- and should efficiently utilize the background image space in its entirety or at least most part of it without the objects overlap.
#五、實驗及視覺化
Pascal VOC 2007上的效能比較




以上是用於精確目標偵測的多網格冗餘邊界框標註的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 用於精確目標偵測的多網格冗餘邊界框標註
Jun 01, 2024 pm 09:46 PM
用於精確目標偵測的多網格冗餘邊界框標註
Jun 01, 2024 pm 09:46 PM
一、前言目前領先的目標偵測器是基於深度CNN的主幹分類器網路重新調整用途的兩級或單級網路。 YOLOv3就是這樣一種眾所周知的最先進的單級檢測器,它接收輸入圖像並將其劃分為大小相等的網格矩陣。具有目標中心的網格單元負責偵測特定目標。今天分享的,就是提出了一種新的數學方法,該方法為每個目標分配多個網格,以實現精確的tight-fit邊界框預測。研究者也提出了一種有效的離線複製貼上資料增強來進行目標偵測。新提出的方法顯著優於一些目前最先進的目標偵測器,並有望獲得更好的效能。二、背景目標偵測網路旨在使用
 目標偵測新SOTA:YOLOv9問世,新架構讓傳統卷積重煥生機
Feb 23, 2024 pm 12:49 PM
目標偵測新SOTA:YOLOv9問世,新架構讓傳統卷積重煥生機
Feb 23, 2024 pm 12:49 PM
在目标检测领域,YOLOv9在实现过程中不断进步,通过采用新架构和方法,有效提高了传统卷积的参数利用率,这使得其性能远超前代产品。继2023年1月YOLOv8正式发布一年多以后,YOLOv9终于来了!自2015年JosephRedmon和AliFarhadi等人提出了第一代YOLO模型以来,目标检测领域的研究者们对其进行了多次更新和迭代。YOLO是一种基于图像全局信息的预测系统,其模型性能不断得到增强。通过不断改进算法和技术,研究人员取得了显著的成果,使得YOLO在目标检测任务中表现出越来越强大
 蘋果手機中設定相機網格的操作步驟
Mar 26, 2024 pm 07:21 PM
蘋果手機中設定相機網格的操作步驟
Mar 26, 2024 pm 07:21 PM
1.開啟蘋果手機的桌面,找到並點選進入【設定】,2、在設定的頁面點選進入【相機】。 3.點選打開【網格】右側的開關即可。
 如何利用C++進行高效能的影像追蹤與目標偵測?
Aug 26, 2023 pm 03:25 PM
如何利用C++進行高效能的影像追蹤與目標偵測?
Aug 26, 2023 pm 03:25 PM
如何利用C++進行高效能的影像追蹤與目標偵測?摘要:隨著人工智慧和電腦視覺技術的快速發展,影像追蹤和目標偵測成為了重要的研究領域。本文將透過使用C++語言和一些開源函式庫,介紹如何實現高效能的影像追蹤和目標偵測,並提供程式碼範例。引言:影像追蹤和目標偵測是電腦視覺領域中的兩個重要任務。它們在許多領域中都有廣泛的應用,如視訊監控、自動駕駛、智慧交通系統等。為了
 多個SOTA ! OV-Uni3DETR:提高3D檢測在類別、場景和模態之間的普遍性(清華&港大)
Apr 11, 2024 pm 07:46 PM
多個SOTA ! OV-Uni3DETR:提高3D檢測在類別、場景和模態之間的普遍性(清華&港大)
Apr 11, 2024 pm 07:46 PM
這篇論文討論了3D目標偵測的領域,特別是針對Open-Vocabulary的3D目標偵測。在傳統的3D目標偵測任務中,系統需要在預測真實場景中物件的定位3D邊界框和語意類別標籤,這通常依賴點雲或RGB影像。儘管2D目標檢測技術因其普遍性和速度展現出色,但相關研究表明,3D通用檢測的發展相比之下顯得滯後。目前,大多數3D目標偵測方法仍依賴完全監督學習,並受到特定輸入模式下完全標註資料的限制,只能識別經過訓練過程中出現的類別,無論是在室內或室外場景。這篇論文指出,3D通用目標偵測面臨的挑戰主要
 CSS佈局技巧:實現圓形網格圖示佈局的最佳實踐
Oct 20, 2023 am 10:46 AM
CSS佈局技巧:實現圓形網格圖示佈局的最佳實踐
Oct 20, 2023 am 10:46 AM
CSS佈局技巧:實現圓形網格圖示佈局的最佳實踐在現代網頁設計中,網格佈局是一種常見且強大的佈局技術。而圓形網格圖示佈局則是更獨特有趣的設計選擇。本文將介紹一些最佳實踐和具體程式碼範例,幫助你實現圓形網格圖示佈局。 HTML結構首先,我們需要設定一個容器元素,在這個容器裡放置圖示。我們可以使用一個無序列表(<ul>)作為容器,列表項目(<l
 Python中的電腦視覺實例:目標偵測
Jun 10, 2023 am 11:36 AM
Python中的電腦視覺實例:目標偵測
Jun 10, 2023 am 11:36 AM
隨著人工智慧的發展,電腦視覺技術已經成為了人們關注的焦點之一。 Python作為一種高效且易學的程式語言,在電腦視覺領域的應用得到了廣泛的認可和推廣。本文將重點放在Python中的電腦視覺實例:目標偵測。什麼是目標檢測?目標偵測是電腦視覺領域中的關鍵技術,其目的是在一張圖片或影片中識別出特定目標的位置和大小。相較於影像分類,目標偵測不僅需要辨識出圖
 最新的目標偵測的深度架構 參數少一半、速度快3倍+
Apr 09, 2023 am 11:41 AM
最新的目標偵測的深度架構 參數少一半、速度快3倍+
Apr 09, 2023 am 11:41 AM
簡要介紹研究作者提出了 Matrix Net (xNet),一種用於目標檢測的新深度架構。 xNets將具有不同大小尺寸和縱橫比的目標映射到網路層中,其中目標在層內的大小和縱橫比幾乎是均勻的。因此,xNets提供了一種尺寸和縱橫比感知結構。研究者利用xNets增強基於關鍵點的目標偵測。新的架構實現了比任何其他單鏡頭偵測器的時效性高,具有47.8的mAP在MS COCO資料集,同時使用了一半的參數而且相比於第二好框架,其在訓練上快了3倍。簡單結果展示上圖所示,xNet的參數及效率要遠遠超過其它模型
