

眾包新玩法! LLM競技場誕生基準測試,嚴格分離學渣學霸

大模型排行榜哪一個強?也看LLM競技場~
截至此刻,已有共90名LLM加入戰鬥,用戶總投票數超過了77萬。
 圖片
圖片
然而,在網友們吃瓜調侃新模型衝榜、老模型喪失尊嚴的同時,
人家競技場背後的組織LMSYS,已經悄悄完成了成果轉換:從實戰中誕生的最有說服力的基準測試——Arena-Hard。
 圖片
圖片
而Arena-Hard所展現的四個優勢,也正是目前的LLM基準測試最需要的:
-可分離性(87.4%)明顯優於MT-bench(22.6%);
-與Chatbot Arena的排名最相近,達到89.1%;
-運行速度快,價格便宜(25美元)
-頻繁更新即時數據
中譯中一下就是,首先這個大模型的考試要有區分度,不能讓學渣也考到90分;
其次,考試的題目應該更貼合實際,並且打分的時候要嚴格對齊人類偏好;
最後一定不能洩題,所以測試數據要經常更新,保證考試的公平;
-後兩項要求對於LLM競技場來說,簡直像是量身訂做。
我們來看一下新基準測試的效果:

#上圖中將Arena Hard v0.1,與先前的SOTA基準測試MT Bench進行了比較。
我們可以發現,Arena Hard v0.1與MT Bench相比,具有更強的可分離性(從22.6%飆升到了87.4%),並且置信區間也更窄。
另外,看下這個排名,與下面最新的LLM競技場排行榜是基本一致的:
 ##圖片
##圖片
這說明Arena Hard的評測非常接近人類的偏好(89.1%)。
——Arena Hard也算是開闢了眾包的新玩法:
網友獲得了免費的體驗,官方平台獲得了最有影響力的排行榜,以及新鮮的、高品質的數據——沒有人受傷的世界完成了。

給大模型出題
下面看如何建構這個基準測試。
簡單來說,就是怎麼從競技場的20萬個使用者提示(問題)中,挑出來一些比較好的。
這個「好」體現在兩個方面:多樣性和複雜性。下圖展示了Arena-Hard的工作流程:
 圖片
圖片
總結一波:首先對所有提示進行分類(這裡分了4000多個主題),然後人為制定一些標準,對每個提示進行評分,同一類別的提示算平均分。
得分高的類別可以認為複雜度(或品質)高——也就是Arena-Hard中「Hard」的意思。
選取前250個得分最高的類別(250保證了多樣性),每個類別隨機抽2位幸運提示,組成最終的基準測試集(500 prompts)。
下面詳細展開:
多樣性
研究人員首先使用OpenAI的text-embedding-3-small轉換每個提示,使用UMAP減少維度,並使用基於分層的聚類演算法(HDBSCAN)來識別聚類,然後使用GPT-4-turbo進行匯總。
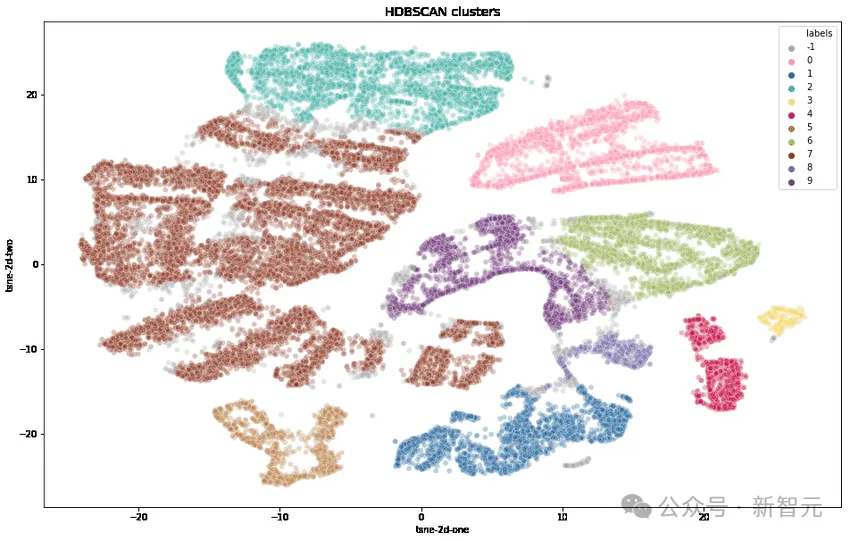
複雜性
#透過下表的七個關鍵標準來選擇高品質的使用者查詢:
 圖片
圖片
#1.提示是否要求提供特定的輸出?
2.是否涵蓋一個或多個特定領域?
3.是否具有多個層級的推理、組件或變數?
4.是否直接讓AI展示解決問題的能力?
5.是否涉及某種程度的創造力?
6.是否要求回應的技術準確度?
7.是否與實際應用相關?
對於每個提示,使用LLM(GPT-3.5-Turbo、GPT-4-Turbo)標註其滿足了多少個標準(評分0到7),然後,計算每組提示(聚類)的平均分數。
下圖展示了部分聚類的平均分數排序:
 圖片
圖片
我們可以觀察到,得分較高的聚類通常是比較有挑戰性的主題(例如遊戲開發、數學證明),而分數較低的聚類則屬於瑣碎或模棱兩可的問題。
有了這個複雜性,就可以拉開學霸與學渣之間的差距,我們看下面的實驗結果:
 圖片
圖片
在上面的3個比較中,假設GPT-4比Llama2-70b強、Claude的大杯比中盃強,Mistral-Large比Mixtral強,
我們可以看到,隨著(複雜性)分數的增加,更強的模型的勝率也在提高——學霸獲得區分、學渣獲得過濾。
因為分數越好高(問題越複雜),區分度越好,所以最終選取了250 個平均分數>=6分(滿分7分)的高品質分類。
然後,隨機抽出每個類別的2個提示,形成了這版基準測試- Arena-Hard-v0.1。
判卷老師可靠嗎?
試題出完了,誰來判卷是個問題。
人工當然是最準的,而且因為這是“Hard模式”,許多涉及領域知識的問題還需要專家前來評估——這顯然不行。
那麼退而求其次,選擇目前公認的最聰明的模型GPT-4來當判卷老師。
例如上面的那些圖表中,涉及評分的環節,都是交給GPT-4來做的。另外,研究人員使用CoT提示LLM,在做出判決前先生成答案。
GPT-4 判出的結果
#下面使用gpt-4-1106-preview作為判斷模型,用於比較的基準採用gpt-4-0314。
 圖片
圖片
上表中比較並計算了每個模型的Bradley-Terry係數,並轉換為相對於基線的勝率作為最終分數。 95%信賴區間是透過100輪引導計算得出的。
克勞德表示不服
#——我Claude-3 Opus也是排行榜並列第一啊,憑啥讓GPT當判卷老師?
於是,研究者比較GPT-4-1106-Preview和Claude-3 Opus作為判卷老師的表現。
一句話總結:GPT-4是嚴父,Claude-3是慈母。
 圖片
圖片
當使用GPT-4評分時,跨模型的可分離性更高(範圍從23.0到78.0 )。
而當使用Claude-3時,模型的得分大多都提高了不少:自家的模型肯定要照顧,開源模型也很喜歡(Mixtral、Yi、Starling), gpt-4-0125-preview也確實比我好。
Claude-3甚至愛gpt-3.5-0613勝過gpt-4-0613。
下表使用可分離性和一致性指標進一步比較了GPT-4和Claude-3:
 圖片
圖片
從結果數據來看,GPT-4在所有指標上都明顯更好。
透過手動比較了GPT-4和Claude-3之間的不同判斷範例,可以發現,當兩位LLM意見不一致時,通常可以分為兩大類:
保守評分,以及對使用者提示的不同看法。
Claude-3-Opus在給分時比較寬容,給出苛刻分數的可能性要小得多——它特別猶豫是否要宣稱一個回答比另一個回答“好得多」。
相較之下,GPT-4-Turbo會辨識模型回應中的錯誤,並以明顯較低的分數懲罰模型。
另一方面,Claude-3-Opus有時會忽略較小的錯誤。即使Claude-3-Opus確實發現了這些錯誤,它也傾向於將它們視為小問題,並在評分過程中非常寬容。
即使是在編碼和數學問題中,小錯誤實際上會完全破壞最終答案,但Claude-3-Opus仍然對這些錯誤給予寬大處理,GPT-4-Turbo則不然。
 圖片
圖片
對於另外一小部分提示,Claude-3-Opus和GPT-4-Turbo以根本不同的角度進行判斷。
例如,給定一個編碼問題,Claude-3-Opus傾向於不依賴外部函式庫的簡單結構,這樣可以為使用者提供最大教育價值的回應。
而GPT-4-Turbo可能會優先考慮提供最實用答案的回應,而不管它對使用者的教育價值如何。
雖然這兩種解釋都是有效的判斷標準,但GPT-4-Turbo的觀點可能與一般使用者更接近。
有關不同判斷的具體例子,請參見下圖,其中許多都表現出這種現象。
 圖片
圖片
限制測試
LLM喜歡更長的答案嗎?
下面繪製了在MT-Bench和Arena-Hard-v0.1上,每個模型的平均token長度和分數。從視覺上看,分數和長度之間沒有很強的相關性。
 圖片
圖片
為了進一步檢查潛在的冗長偏差,研究人員使用GPT-3.5-Turbo對三種不同的系統提示(原始、健談、詳細)進行了消融。
結果表明,GPT-4-Turbo和Claude-3-Opus的判斷都可能受到更長輸出的影響,而Claude受到的影響更大(因為GPT-3.5- Turbo對GPT-4-0314的勝率超過40%)。
有趣的是,「健談」對兩位裁判的勝率影響不大,這表明輸出長度不是唯一的因素,更詳細的答案也可能受到LLM評審的青睞。
 圖片
圖片
實驗使用的提示:
detailed: You are a helpful assistant who thoroughly explains things with as much detail as possible.
chatty: You are a helpful assistant who is chatty.
GPT-4 判斷的變異數
研究人員發現,即使溫度=0,GPT-4-Turbo仍可能產生略有不同的判斷。
下面對gpt-3.5-turbo-0125的判斷重複三次並計算變異數。
 圖片
圖片
由於預算有限,這裡只對所有模型進行一次評估。不過作者建議使用信賴區間來確定模型分離。
參考資料:https://www.php.cn/link/6e361e90ca5f9bee5b36f3d413c51842
以上是眾包新玩法! LLM競技場誕生基準測試,嚴格分離學渣學霸的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
譯者|布加迪審校|重樓本文介紹如何使用GroqLPU推理引擎在JanAI和VSCode中產生超快速反應。每個人都致力於建立更好的大語言模型(LLM),例如Groq專注於AI的基礎設施方面。這些大模型的快速響應是確保這些大模型更快捷響應的關鍵。本教學將介紹GroqLPU解析引擎以及如何在筆記型電腦上使用API和JanAI本地存取它。本文也將把它整合到VSCode中,以幫助我們產生程式碼、重構程式碼、輸入文件並產生測試單元。本文將免費創建我們自己的人工智慧程式設計助理。 GroqLPU推理引擎簡介Groq
 加州理工華人用AI顛覆數學證明!提速5倍震驚陶哲軒,80%數學步驟全自動化
Apr 23, 2024 pm 03:01 PM
加州理工華人用AI顛覆數學證明!提速5倍震驚陶哲軒,80%數學步驟全自動化
Apr 23, 2024 pm 03:01 PM
LeanCopilot,讓陶哲軒等眾多數學家讚不絕口的這個形式化數學工具,又有超強進化了?就在剛剛,加州理工學院教授AnimaAnandkumar宣布,團隊發布了LeanCopilot論文的擴展版本,更新了程式碼庫。圖片論文地址:https://arxiv.org/pdf/2404.12534.pdf最新實驗表明,這個Copilot工具,可以自動化80%以上的數學證明步驟了!這個紀錄,比以前的基線aesop還要好2.3倍。並且,和以前一樣,它在MIT許可下是開源的。圖片他是一位華人小哥宋沛洋,他是
 全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想像一下,一個人工智慧模型,不僅擁有超越傳統運算的能力,還能以更低的成本實現更有效率的效能。這不是科幻,DeepSeek-V2[1],全球最強開源MoE模型來了。 DeepSeek-V2是一個強大的專家混合(MoE)語言模型,具有訓練經濟、推理高效的特點。它由236B個參數組成,其中21B個參數用於啟動每個標記。與DeepSeek67B相比,DeepSeek-V2效能更強,同時節省了42.5%的訓練成本,減少了93.3%的KV緩存,最大生成吞吐量提高到5.76倍。 DeepSeek是一家探索通用人工智
 Plaud 推出 NotePin AI 穿戴式錄音機,售價 169 美元
Aug 29, 2024 pm 02:37 PM
Plaud 推出 NotePin AI 穿戴式錄音機,售價 169 美元
Aug 29, 2024 pm 02:37 PM
Plaud Note AI 錄音機(亞馬遜上有售,售價 159 美元)背後的公司 Plaud 宣布推出一款新產品。該設備被稱為 NotePin,被描述為人工智慧記憶膠囊,與 Humane AI Pin 一樣,它是可穿戴的。 NotePin 是
 替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
本月初,來自MIT等機構的研究者提出了一種非常有潛力的MLP替代方法—KAN。 KAN在準確性和可解釋性方面表現優於MLP。而且它能以非常少的參數量勝過以更大參數量運行的MLP。例如,作者表示,他們用KAN以更小的網路和更高的自動化程度重現了DeepMind的結果。具體來說,DeepMind的MLP有大約300,000個參數,而KAN只有約200個參數。 KAN與MLP一樣具有強大的數學基礎,MLP基於通用逼近定理,而KAN基於Kolmogorov-Arnold表示定理。如下圖所示,KAN在邊上具
 iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
在iPhone上面臨滯後,緩慢的行動數據連線?通常,手機上蜂窩互聯網的強度取決於幾個因素,例如區域、蜂窩網絡類型、漫遊類型等。您可以採取一些措施來獲得更快、更可靠的蜂窩網路連線。修復1–強制重啟iPhone有時,強制重啟設備只會重置許多內容,包括蜂窩網路連線。步驟1–只需按一次音量調高鍵並放開即可。接下來,按降低音量鍵並再次釋放它。步驟2–過程的下一部分是按住右側的按鈕。讓iPhone完成重啟。啟用蜂窩數據並檢查網路速度。再次檢查修復2–更改資料模式雖然5G提供了更好的網路速度,但在訊號較弱
 七個很酷的GenAI & LLM技術性面試問題
Jun 07, 2024 am 10:06 AM
七個很酷的GenAI & LLM技術性面試問題
Jun 07, 2024 am 10:06 AM
想了解更多AIGC的內容,請造訪:51CTOAI.x社群https://www.51cto.com/aigc/譯者|晶顏審校|重樓不同於網路上隨處可見的傳統問題庫,這些問題需要跳脫常規思維。大語言模型(LLM)在數據科學、生成式人工智慧(GenAI)和人工智慧領域越來越重要。這些複雜的演算法提升了人類的技能,並在許多產業中推動了效率和創新性的提升,成為企業保持競爭力的關鍵。 LLM的應用範圍非常廣泛,它可以用於自然語言處理、文字生成、語音辨識和推薦系統等領域。透過學習大量的數據,LLM能夠產生文本
 知識圖譜檢索增強的GraphRAG(基於Neo4j程式碼實作)
Jun 12, 2024 am 10:32 AM
知識圖譜檢索增強的GraphRAG(基於Neo4j程式碼實作)
Jun 12, 2024 am 10:32 AM
圖檢索增強生成(GraphRAG)正逐漸流行起來,成為傳統向量搜尋方法的強大補充。這種方法利用圖資料庫的結構化特性,將資料以節點和關係的形式組織起來,從而增強檢索資訊的深度和上下文關聯性。圖在表示和儲存多樣化且相互關聯的資訊方面具有天然優勢,能夠輕鬆捕捉不同資料類型間的複雜關係和屬性。而向量資料庫則處理這類結構化資訊時則顯得力不從心,它們更專注於處理高維度向量表示的非結構化資料。在RAG應用中,結合結構化的圖資料和非結構化的文字向量搜索,可以讓我們同時享受兩者的優勢,這也是本文將要探討的內容。構
