
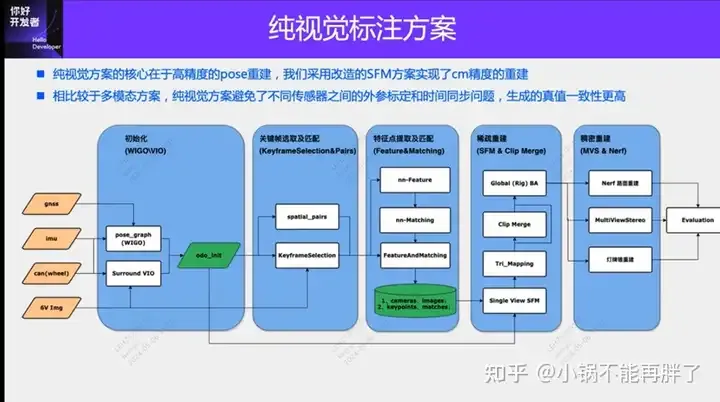
純視覺的標註方案,主要利用視覺加上一些GPS、IMU和輪速感測器的資料進行動態標註。當然面向量產場景的話,不一定要純視覺,有些量產的車輛裡面,會有像固態雷達(AT128)這樣的感測器。如果從量產的角度做資料閉環,把這些感測器都用上,可以有效解決動態物體的標註問題。但是我們的方案裡面,是沒有固態雷達的。所以,我們就介紹這個最通用的量產標註方案。
純視覺的標註方案的核心在於高精度的pose重建。我們採用Structure from Motion (SFM) 的pose重建方案,來確保重建精度。但是傳統的SFM,尤其是增量式的SFM,效率非常緩慢,計算複雜度昂貴,計算複雜度為O(n^4),n是影像的數量。這種重建的效率,對於大規模模型的資料標註,是沒有辦法接受的,我們對SFM的方案做了一些改進。
改進後的clip重建主要分為三個模組:1)利用多感測器的數據,GNSS、IMU和輪速計,建構pose_graph優化,得到初始的pose,這個演算法我們稱為Wheel-Imu-GNSS-Odometry (WIGO);2)影像進行特徵提取和匹配,並直接利用初始化的pose進行三角化,得到初始的3D點;3)最後進行一次全局的BA(Bundle Adjustment)。 我們的方案一方面避免了增量式SFM,另一方面不同的clip之間可以實現並行運算,從而大幅度的提升了pose重建的效率,比起現有的增量式的重建,可以實現10到20倍的效率提升。
在單次重建的過程中,我們的方案也做了一些最佳化。例如我們採用了Learning based features(Superpoint和Superglue),一個是特徵點,一個是匹配方式,來取代傳統的SIFT關鍵點。用學習NN-Features的優勢就在於,一方面可以根據數據驅動的方式去設計規則,滿足一些定制化的需求,提昇在一些弱紋理以及暗光照的情況下的魯棒性;另一方面可以提升關鍵點檢測和匹配的效率。我們做了一些比較的實驗,在夜晚場景下NN-features的成功率會比SFIT提升大概4倍,從20%提升至80%。
在得到單一Clip的重建結果之後,我們會進行多個clips的聚合。與現有的HDmap建圖結構匹配的方案不同,為了確保聚合的精度,我們採用特徵點層級的聚合,也就是透過特徵點的匹配進行clip之間的聚合約束。這個操作類似於SLAM中的回環檢測,首先採用GPS來確定一些候選的匹配幀;之後,利用特徵點以及描述進行圖像之間的匹配;最後,結合這些回環約束,構造全局的BA(Bundle Adjustment)並進行優化。目前我們這套方案的精確度,RTE指標遠超於現有的一些視覺SLAM或建圖方案。
實驗:採用colmap cuda版,使用180張圖,3848* 2168分辨率,手動設定內參,其餘使用預設設置,sparse重建耗時約15min,整個dense重建耗時極長(1- 2h)
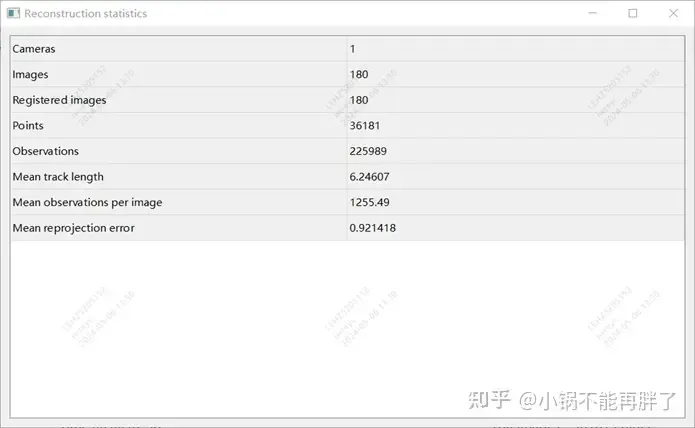
重建結果統計
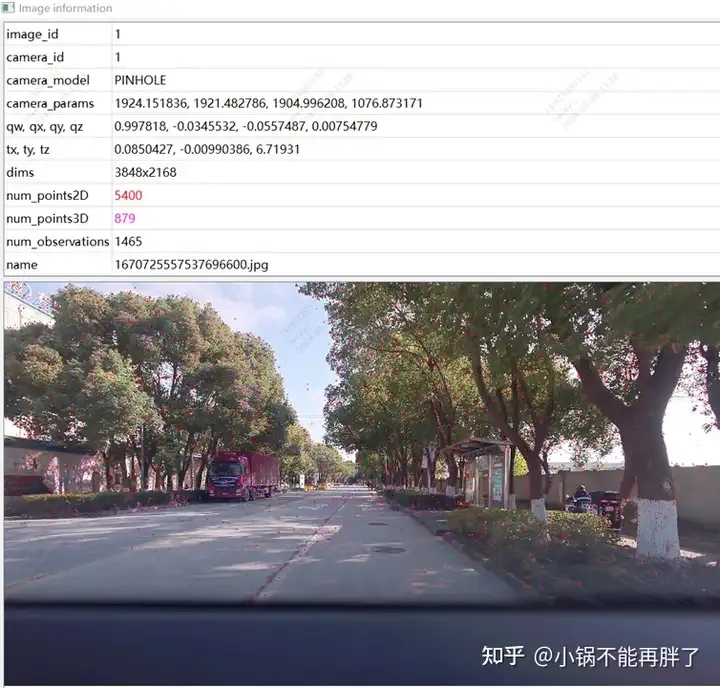
#特徵點示意圖

sparse重建效果

直行路段整體效果

地面錐桶效果

高處限速牌效果

#路口斑馬線效果
#容易不收斂,另外試了一組圖片就沒有收斂:靜止ego過濾,根據自車運動每50-100m形成一個clip;高動態場景動態點濾除、隧道場景位姿
利用周視和環視多攝影機:特徵點匹配圖優化、內外參優化項、利用現有的odom。
https://github.com/colmap/colmap/blob/main/pycolmap/custom_bundle_adjustment.py
pyceres.solve(solver_options, bundle_adjuster.problem, summary)
以上是自動駕駛第一性之純視覺靜態重建的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















