

單次支援38萬字輸入!騰訊混元推出256k長文模型,透過騰訊雲端向企業和個人開發者開放

AI大模型技術正成為推動高品質生產力發展的關鍵力量,在與千行百業的融合中發揮著重要作用。騰訊混元大模型透過採用混合專家模型 (MoE) 結構,已將模型擴展至兆級參數規模,增加「腦」容量提升預測效能的同時,推動了推理成本下降。作為通用模型,騰訊混元在中文表現上處於業界領先水平,尤其在文字生成、數理邏輯和多輪對話中表現表現卓越。
近日,騰訊混元大模型正式對外發布256k長文模型,並透過騰訊雲向廣大企業和個人開發者開放,以支持更廣泛的創新和應用。騰訊混元256k模型版本具備處理超過#38萬字符的超長文字能力。在對話應用場景中,該模型能夠“記憶”更多的對話內容,有效避免
## “
忘記
”訊息等問題。此外,它還具備出色的上下文分析能力,能夠為對話參與者提供更精確和相關的回饋,從而輔助他們做出更明智的決策。
此外,在長文件的閱讀理解和大規模資料分析方面也展現出強大效能。它能夠為金融、醫療、教育、出行等行業的專業人士提供強有力的工作支持,顯著提高他們的工作效率。模型在推理性能上也進行了深入優化,確保了在騰訊雲等平台上的實際應用中,用戶能夠享受到更流暢和高效的使用體驗。 #減少“健忘”,讓大模型更聰明在大模型產品中,處理對話式需求是一項核心功能。但由於長文本處理能力的限制,傳統大模型在對話中容易
“迷失方向”或出現「記憶缺失」,隨著對話長度的增加,遺忘的資訊量也隨之增多。 騰訊混元256k#模型針對這項挑戰進行了專門最佳化。它採用了先進的「專家混合」(MoE##)架構,並融合了
RoPE-NTK和Flash Attention V2#等創新技術,既保持了對通用短文本(少於4,000字元)的高效處理能力,同時在長文本處理的深度和廣度上實現了突破。 目前,騰訊混元大模型已經具備256k的超長上下文理解能力,單次處理字元數超過38萬個,在經過嚴苛的
「
」任務測試後,模型在長文本處理上的準確率已達到
99.99%,在國際上也處於領先地位。
持續穩定迭代,大模型應用效率提升騰訊混元大模型在業界率先採用了混合專家模型(MoE)結構,並在此過程中累積了大量自研技術。在上一個版本32K中,該模型已顯著超越市面上的開源同類模型,並在多種應用場景中展現出優異性能。 經過全新迭代,騰訊混元256k
在通用領域的GSB評測中,相較於前一版本,勝出率50.72%。同時,騰訊混元
256k
例如,當一份央行發布的金融報告輸入騰訊混元256k模型時,模型能夠迅速提煉和總結報告的要點,在處理速度和準確性上均達到了令人滿意的水平。
####################################推理效能最佳化,帶來更強的大模型理解能力#########与此同时,腾讯混元256k在推理性能上进行了深入优化。在INT8精度模式下,与FP16精度相比,模型的QPM(每秒查询率)实现了23.9%的显著提升,而首字耗时仅增加了5.7%。这些改进显著增强了模型在实际应用中的响应速度和整体效率。
以《三国演义》的分析为例,腾讯混元256k能够迅速阅读并检索这部数十万字的古典小说,不仅能够准确识别出小说中的关键人物和事件情节,甚至对于天气、角色着装等细节描述也能提供精确的信息。

AI大模型作为新质生产力的关键组成部分,对推动产业升级和实现高质量发展具有至关重要的作用。腾讯混元256k模型的推出为整个行业注入了全新活力,并开拓了更广泛的应用前景。
目前,腾讯混元256k长文模型已经通过腾讯云向广大企业和个人开发者开放,用户可通过hunyuan-standard版本256k长文模型接入。这使得更多的开发者和用户能够便捷地接入并使用腾讯混元大模型的强大功能,进而为各行各业提供智能化的解决方案,推动更多创新应用场景的实现。
以上是單次支援38萬字輸入!騰訊混元推出256k長文模型,透過騰訊雲端向企業和個人開發者開放的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 騰訊混元大模型全面降價!混元-lite即日起免費
Jun 02, 2024 pm 08:07 PM
騰訊混元大模型全面降價!混元-lite即日起免費
Jun 02, 2024 pm 08:07 PM
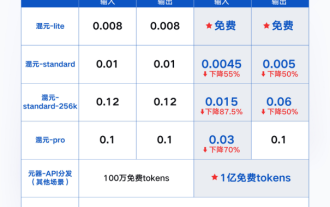
5月22日,騰訊雲公佈全新大模型升級方案。主力模型之一混元-lite模型,API輸入輸出總長度計畫從目前的4k升級到256k,價格從0.008元/千tokens調整為全面免費。混元-standardAPI輸入價格從0.01元/千tokens降至0.0045元/千tokens,下降55%,API輸出價格從0.01元/千tokens降至0.005元/千tokens,下降50%。新上線的混元-standard-256k,具備處理超過38萬字符的超長文字能力,API輸入價格下調至0.015元/千toke
 來自科技進步一等獎的肯定:騰訊破解萬億參數大模型訓練難題
Mar 27, 2024 pm 09:41 PM
來自科技進步一等獎的肯定:騰訊破解萬億參數大模型訓練難題
Mar 27, 2024 pm 09:41 PM
中國電子學會2023科學技術獎授獎名單公佈,這次,我們發現了一個熟悉的身影-騰訊Angel機器學習平台。在大模型快速發展的當下,科學技術獎授予機器學習平台類研究和應用項目,對於模型訓練平台的價值和重要性給予了充分的肯定。科學技術獎認可了機器學習平台類專案的研究和應用,特別在大型模型快速發展的背景下,對模型訓練平台的價值和重要性給予了充分的認可。隨著深度學習的興起,各大公司開始意識到機器學習平台在發展人工智慧技術的重要性。谷歌、微軟、英偉達等公司都推出了自己的機器學習平台,以加速
 利用vscode遠端調試Linux內核
Feb 05, 2024 pm 12:30 PM
利用vscode遠端調試Linux內核
Feb 05, 2024 pm 12:30 PM
前言上一遍文章介紹了利用QEMU+GDB調試Linux核心。但是,有時候直接利用GDB調試查看程式碼還不是很方便,所以,在這麼重要的場合,怎麼能少的了vscode這個神器呢。本篇文章介紹如何使用vscode遠端調試核心。本文環境:windows10vscodeubuntu20.04我個人使用的是騰訊雲端伺服器,所以我省去了安裝虛擬機器的過程。直接從vscode配置開始。 vscode外掛安裝remote-ssh在插件庫中找到Remote-SSH插件並且安裝。安裝完成後右邊工具列會多出一個功能按F1呼出對
 GPT Store都開不下去,這家國產平台怎麼敢走這條路的? ?
Apr 19, 2024 pm 09:30 PM
GPT Store都開不下去,這家國產平台怎麼敢走這條路的? ?
Apr 19, 2024 pm 09:30 PM
注意看,這個男人把超1000種大模型接入,讓你可插拔無縫切換使用。最近也上線了可視化的AI工作流程:給你一個直覺的拖放介面,拖拖、拉拉、拽拽,就能在無限畫布上編排自己個兒的Workflow。正所謂兵貴神速,量子位聽說,這個AIWorkflow上線不到48小時,就已經有用戶配出了100多個節點的個人工作流程。不賣關子,今天要聊的是LLMOps公司Dify,及其CEO張路宇。張路宇也是Dify的創辦人。投入創業前,有11年的網路經驗。搞產品設計,懂專案管理,也對SaaS有點自己的獨到見解。後來他
 家用路由器要不要開啟ipv6「必看:家用路由器開啟 IPV6優勢」
Feb 07, 2024 am 09:03 AM
家用路由器要不要開啟ipv6「必看:家用路由器開啟 IPV6優勢」
Feb 07, 2024 am 09:03 AM
IPv4枯竭了,IPv6被剛需,可這次升級就只是因為被動改變嗎?對一般大眾而言,IPv6究竟有何意義?全面升級IPv6的改變,能為我們網路帶來多大的改變呢? 01大規模的IPv6改造即將實現最近,工信部辦公室和國家廣播電視總局辦公室發布了一份通知,提出了推動網路電視業務IPv6改造的要求。中國行動、阿里雲、騰訊雲、百度雲、京東雲、華為雲和網宿科技需要對與網路電視業務相關的內容傳遞網路(CDN)進行IPv6改造。 2020年底,基於IPv6協定的網路電視業務服務能力將達到IPv4的85%
 騰訊混元升級模型矩陣,雲端推出256k長文模型
Jun 01, 2024 pm 01:46 PM
騰訊混元升級模型矩陣,雲端推出256k長文模型
Jun 01, 2024 pm 01:46 PM
大模型落地加速,「產業實用」成為發展共識。 2024年5月17日,騰訊雲生成式AI產業應用高峰會在北京召開,公佈大模型研發、應用產品的系列進度。騰訊混元大模型能力持續升級,多個版本模型hunyuan-pro、hunyuan-standard、hunyuan-lite透過騰訊雲對外開放,滿足企業客戶、開發者在不同場景下的模型需求,落地最優性價比模型方案。騰訊雲大模型知識引擎、影像創作引擎、影片創作引擎三大工具發布,打造大模型時代原生工具鏈,透過PaaS服務簡化資料存取、模式精調、應用開發流程,協助企業
 微信連結如何製作?微信連結製作方法分享
Mar 09, 2024 pm 09:37 PM
微信連結如何製作?微信連結製作方法分享
Mar 09, 2024 pm 09:37 PM
微信,作為一款廣受歡迎的社交軟體,不僅為人們提供了即時通訊的便利,還融合了多種功能,豐富了用戶的社交體驗。其中,微信連結的製作與分享是微信功能的重要一環。微信連結的製作主要依賴微信公眾平台及其相關功能,以及第三方工具。以下是幾種常見的製作微信連結的方法。微信連結如何製作?微信連結製作方法分享第一種方法,使用微信公眾平台的圖文編輯器。 1.登入微信公眾平台,進入圖文編輯介面。 2、在編輯器中加入文字或圖片,然後利用連結按鈕加入所需的連結。這種方式適合簡單的文字或圖片連結。第二種方法,使用HTML代d
 wordpress需要備案嗎
Apr 16, 2024 pm 12:07 PM
wordpress需要備案嗎
Apr 16, 2024 pm 12:07 PM
WordPress需要備案。根據我國《網路安全管理辦法》,在境內提供網路資訊服務的網站需向所在地省級網路資訊辦公室備案,包括WordPress在內。備案流程包括選擇服務商、準備資料、提交申請、審核公示、取得備案號等步驟。備案好處有合法合規、提升可信度、滿足接取要求、確保正常存取等。備案資料需真實有效,備案後需定期更新。
