

Riva是NVIDIA推出的一款SDK,用於即時的Speech AI服務。它是一個高度可自訂的工具,並且使用GPU進行加速。 NGC上提供了許多預先訓練好的模型,這些模型開箱即用,可以直接使用Riva提供的ASR和TTS解決方案進行部署。
為了滿足特定領域的需求或進行客製化功能的開發,使用者也可以使用 NeMo 對這些模型進行重新訓練或微調。從而進一步提升模型的效能,使其更適應使用者的需求。
Riva+Skills是一種高度可自訂化的工具,它利用GPU加速即時串流的語音辨識和語音合成,並且能夠同時處理成千上萬個並發請求。它支援多種部署平台,包括本地端、雲端和端側。

在語音辨識方面,Riva使用了準確度很高的SOTA 模型,例如Citrinet、 Conformer 和NeMo 自我研究的FastConformer 等。目前,Riva 支援超過10種單語言模型,並且還支援多語種的語音識別,包括英語-西班牙語、英語-中文和英語-日語等多語言語音識別。
通透過客製化的功能,可以進一步提升模型的準確率。例如,針對特定行業術語、口音或方言的支持,以及對噪音環境的客製化處理,都可以幫助提高語音辨識的性能。
Riva的整體框架能夠適用於多種場景,例如客服和會議系統等。除了通用場景外,Riva的服務還可以根據不同行業的需求進行客製化,例如CSP、教育、金融等行業。
在Riva ASR 的整個流程中,有一些可客製化的模組,這些模組可以依照難度分為三類。

首先,橘色框中是在 inference 過程中,在客戶端即可做的客製化。例如支援熱詞功能,透過在 inference 過程中加入產品名稱或專有名詞,使語音模型更能準確地辨識這些特定的詞彙。這項功能是 Riva 本身就支援的,在不重新訓練模型或重新啟動 Riva 伺服器的情況下即可完成客製化。
紫色方塊中是部署時可以進行的一些客製化。例如,在 Riva 的串流識別中,提供了延遲優化或吞吐優化兩種模式,可以根據業務需求進行選擇,以獲得更好的效能表現。此外,在部署過程中,還可以進行發音字典的客製化。透過客製化發音字典,可以確保特定術語、名稱或行業術語的正確發音,並提高語音辨識的準確性。
綠色框中是訓練過程中可以進行的客製化,也就是在伺服器端進行的訓練和調整。例如在訓練開始的文本正規化階段,可以加入一些特定文本的處理。另外,可以微調或重新訓練聲學模型,以解決特定業務場景下的諸如口音、噪音等問題,使模型更加穩健。還可以重新訓練語言模型、微調標點模型、逆文本正規化等。
以上就是 Riva 可以客製化的部分。

#Riva TTS 流程如上圖右側所示,它包含以下幾個模組:
上圖中,以合成"Hello World"這句話為例,首先進入文字正規化模組,對文字進行標準化處理,例如將大小寫規範化。接著進入 G2P 模組,將文字轉換為音素序列。之後進入頻譜合成模組,透過神經網路訓練,得到頻譜。最後進入 vocoder,將頻譜轉換為最終的聲音。
Riva 提供串流 TTS 支持,使用了目前流行的 FastPitch 和 HiFi-GAN 模型的組合。目前支援多種語言,包括英語、中文普通話、西班牙語、義大利語和德語等。
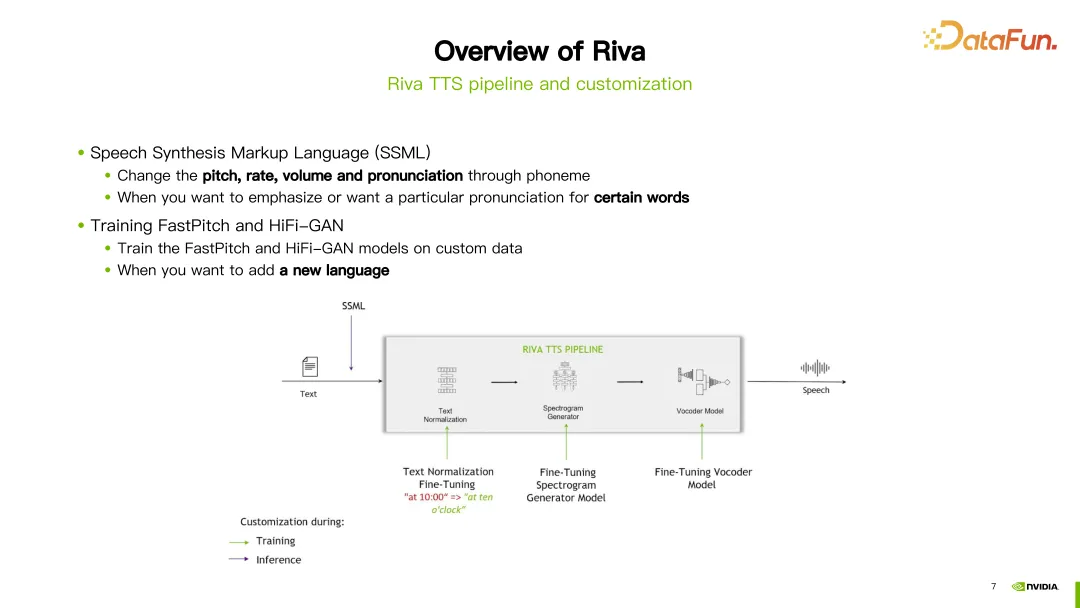
在Riva 的TTS 流程中,為客製化提供了兩種方式。第一種方式是使用語音合成標記語言(SSML),這是一種比較容易的客製化方式。透過一些配置,可以調整發音的音調、語速、音量等。通常情況下,如果想改變特定單字的發音,會選擇這種方式。
另一種方式是進行微調或重新訓練 FastPitch 或 HiFi-GAN 模型。可以使用自己的特定資料對這兩個模型進行微調或重新訓練。

在過去的一年中,Riva 對中文模型進行了一些更新和改進。接下來介紹其中一些重要的更新。
首先,持續優化中文語音辨識(ASR)模型。可以在對應的連結中找到最新的 ASR 模型。
其次,引入了統一模型(Unified Model)的支援。這意味著在一次推理中,可以同時做語音辨識標點符號預測。
第三,增加了中英文混合模型的支持。這意味著模型可以同時處理中文和英文的語音輸入。
此外,也引入了一些新的模組和功能支援。包括基於神經網路的語音活動偵測(VAD)和說話者日誌(Speaker Diarization)模組。也引入了中文逆文本正規化的功能。這些模型的詳細資訊都可以在相應的連結中找到。
#除此之外,我們也為中文提供了詳細的教學。第一部分是關於熱詞(Word Boosting)的教學。

熱詞是透過在辨識時候對特定的字詞的權重做調整,這使得這個字詞辨識得更準。在教程中,展示了一個中文模型使用熱詞的示例,如"望岳",這是一首古詩的名字,我們為這個詞賦予了一個分數為 20 的權重。接著,使用 Riva 提供的 add_word_boosting_to_config 方法,將我們希望新增的詞彙及其分數配置到客戶端。然後,將配置好的請求傳送給 ASR 伺服器,就可以取得加入熱詞後的識別結果。
在配置熱詞時,需要設定兩個參數:boosted_lm_words 和boosted_lm_score。 boosted_lm_words 是我們希望提高辨識準確度的詞彙清單。而 boosted_lm_score 則是為這些詞彙所設定的分數,通常在 20 到 100 之間。

除了前面的基本配置,Riva 的熱詞功能也支援一些進階用法。例如,可以同時提升多個詞彙的權重。例如,在例子中我們給"五 G"和"四 G"這兩個詞彙,分別設定了權重 20 和 30。
此外,我們還可以使用 word boosting 來降低某些詞彙的準確度,即給它們分配負的權重,從而降低其出現的機率。例如,在例子中,我們給了一個漢字"她",它的分數設定為 -100。這樣,模型就會傾向於不辨識出這個漢字。理論上,我們可以設定任意數量的熱詞,不會對延遲造成影響。另外值得注意的是,boosting 的過程是在客戶端實現的,對伺服器端沒有影響。
第二個教學課程,是關於如何微調 Conformer 聲學模型。

微調 ASR 所使用的是 NeMo 工具。配置 NGC 帳戶後,就可以使用"NGC download"指令直接下載 Riva 所提供的預先訓練好的中文模型。在這個例子中,下載了第五個版本的中文 ASR 模型。下載完成後,需要載入預訓練模型。
首先,需要導入一些套件。參數 model path 設定為剛下載好的模型的路徑。接下來,使用 NeMo 提供的 ASRModel.restore_from 函數來取得模型的設定文件,透過 target 這個參數可以取得原始 ASR 模型的類別。接著,使用 import_class_by_path 函數取得實際的模型類別。最後,使用該類別下模型的 restore_from 方法來載入指定路徑下的 ASR 模型參數。

載入了模型後,就可以使用 NeMo 提供的訓練腳本來微調。在這個例子中,我們以訓練 CTC 模型為例,使用的腳本是 speech_to_text_ctc.py。一些需要配置的參數包括 train_ds.manifest_filepath,即訓練資料的 JSON 檔案路徑,還有是否使用 GPU、最佳化器以及最大迭代輪數等。
在訓練完模型之後,可以進行評估。評估時需要注意將 use_cer 參數設為true,因為對於中文,我們使用字元錯誤率(Character Error Rate)作為指標。完成了模型的訓練和評估之後,可以使用 nemo2riva 指令將 NeMo 模型轉換為 Riva 模型。然後使用 Riva 的 Quickstart 工具來部署模型。
接下來介紹Riva TTS 服務。
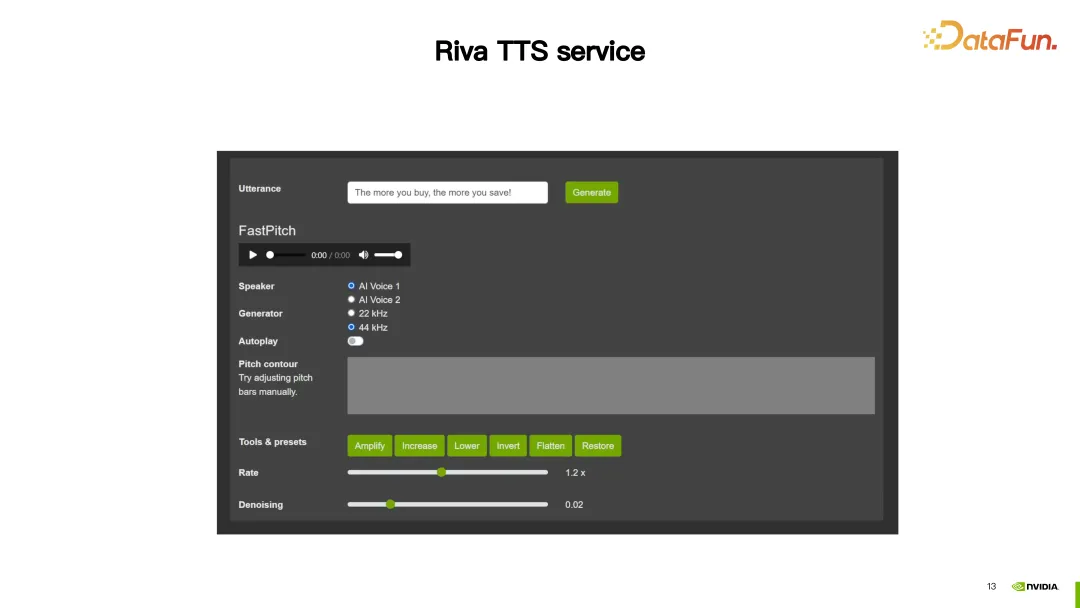
#在這一示範中,Riva TTS 提供的自訂功能,使合成出的語音更加自然。
接下來將介紹 Riva TTS 提供的兩種客製化方式。

#首先是前面提到的SSML(Speech Synthesis Markup Language),它透過一個腳本來進行配置。透過 SSML,可以調整 TTS 中的韻律,包括音高(pitch)和語速(rate),另外還可以調整音量。
如上圖所示,對第一句話「Today is a sunny day“,將其節奏的 pitch 改成了 2.5。對第二句話,做了兩個配置,一個是將它的 rate 設成 high,另外一個將音量加 1DB。這樣就可以獲得一個客製化的結果。
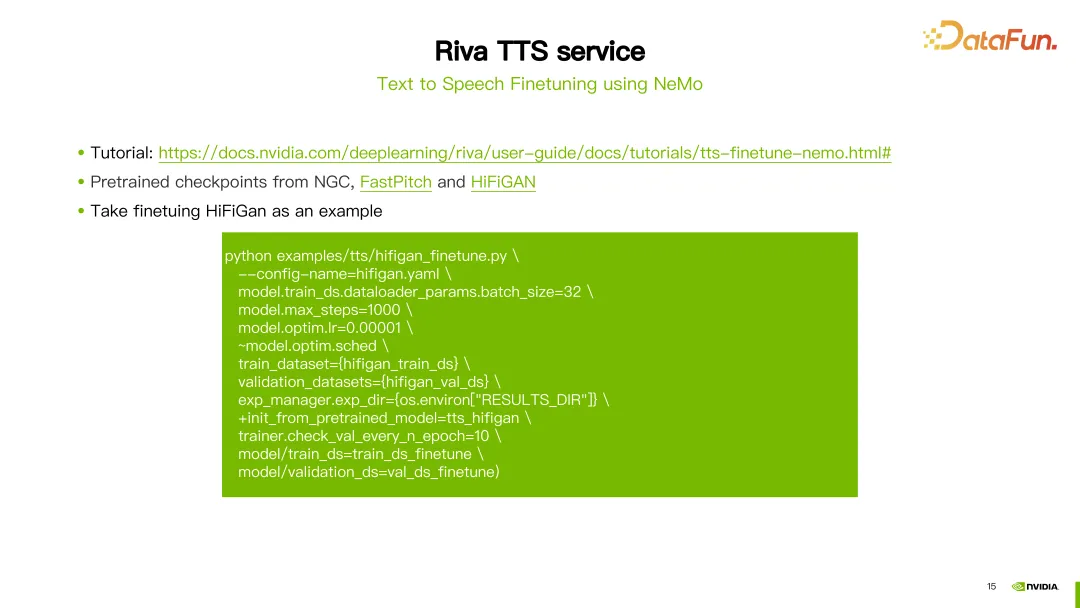
除了 SSML 之外,還可以使用 NeMo 工具微調或重新訓練 Riva TTS 的FastPitch 或 HiFi-GAN 模型。
Riva 提供了相關教程,在 NGC 上也提供了一些預訓練模型(請參閱上圖中的連結)。
圖中舉了一個微調 HiFi-GAN 模型的例子。使用 hifigan_finetune.py 指令,並設定模型組態名稱、批次大小、最大迭代步數、學習率等參數。透過設定train_dataset 參數設定微調 HiFi-GAN 所需的資料集路徑。如果從 NGC 下載了預訓練模型,也可以使用 init_from_pretrained_model 參數來載入預訓練模型。這樣就可以重新訓練 HiFi-GAN 模型。
客製化好的模型就可以使用 Quickstart 工具來進行部署。

#在開始之前,需要註冊一個NGC 帳號,並確保GPU 支持Riva,並且已經安裝了Docker 環境。
一旦準備工作完成,即可透過提供的連結下載 Riva Quickstart。如果已經設定了 NGC CLI,也可以使用 NGC CLI 直接下載 Riva Quickstart。
在下載完成 Riva Quick Start 之後,可以使用其中提供的腳本來進行伺服器的初始化、啟動和關閉等操作。

以最新版本的Riva(2.13.1)為例,下載完成後,只需執行riva_init.sh、riva_start.sh 或riva_stop .sh 即可完成伺服器的初始化、啟動和關閉操作。
如果想要使用中文模型,只要將語言程式碼設定為 zh-CN,工具就會自動下載對應的預訓練模型。即可啟動服務使用中文的 ASR(自動語音辨識)和 TTS(文字轉語音)功能。

#一旦伺服器啟動成功,即可使用Riva 提供的腳本riva_start_client .sh 來呼叫服務。如果希望進行離線語音識別,只需執行 riva_asr_client 命令並指定要識別的音訊檔案路徑。如果要進行串流語音識別,則可以使用 riva_streaming_asr_client 指令。如果要進行語音合成,可以使用 riva_tts_client 指令,向剛啟動的伺服器傳送要處理或合成的音訊。
以下是一些Riva 相關的文件資源:

Riva 官方文件:這個文件提供了關於Riva 的詳細信息,包括安裝、配置和使用指南等。您可以在這裡找到 Riva 的官方文檔,以便深入了解和學習 Riva 的各個方面。
Riva Quick Start 使用者指南:這個指南為使用者提供了 Riva Quick Start 的詳細說明,包括安裝和設定步驟,以及常見問題的解答。如果您在使用 Riva Quick Start 過程中遇到任何問題,您可以在這個使用者指南中找到答案。
Riva Release Notes:這個文件提供了關於 Riva 最新模型的更新資訊。您可以在這裡了解每個版本的更新內容和改進。
以上這些資源將可以為使用者更能理解並使用 Riva 提供協助。
以上就是這次分享的內容,謝謝大家。
A1:對,Riva 使用的是 Nvidia Triton 的inference 框架,是基於 Nvidia Triton 所做的一些開發。
A2:Riva 目前應該主要還是聚焦在 Speech AI 領域。
A3:Riva 更專注於部署的解決方案,用Nemo 訓練的模型可以用Riva 來部署,我們也可以使用Nemo 來做一些fine-tuning 和訓練的工作,然後fine-tune 好的模型也可以在Riva 當中部署。
A4:其他框架訓練的暫時是不支援的,或是需要一些額外的開發工作。
A5:Riva 現在主要支援的是 Nemo 訓練出來的模型,Nemo 其實就是基於 PyTorch 所做的一些開發。
A6:對於自研的模型,想在 Riva 裡面支持的話,是需要做一些額外的開發的。
A7:可參考 Riva 提供的適配平台相關文檔,其中有不同型號 GPU 的適配的情況。
A8:可以直接在 NGC 下載 Riva Quickstart 工具包來試用 Riva。
A9:對的。可以使用自己的一些方言的數據。在 Riva 提供的預訓練模型基礎上進行微調,再在 Riva 裡面部署就可以了。
A10:Riva 的加速其實也是使用 Tensor RT,Riva 是一個基於 Tensor RT 和 Triton 的產品。
以上是利用 NVIDIA Riva 快速部署企業級中文語音 AI 服務並進行優化加速的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















