

無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct

在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。
这一创新成果在代码生成任务取得了显著突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。

StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。
该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数据,也无需从GPT4等商业大模型中获取数据,避免了潜在的版权问题。
在HumanEval测试中,StarCoder2-15B-Instruct以72.6%的Pass@1成绩脱颖而出,较CodeLlama-70B-Instruct的72.0%有所提升。
在LiveCodeBench数据集的评估中,这一自对齐模型的表现甚至超过了基于GPT-4生成数据训练的同类模型。这一成果证明了通过自身分布内的数据,大模型同样能够有效地学习如何与人类类似对齐,而无需依赖外部教师大模型的偏移分布。
该项目的成功实施得到了美国东北大学Arjun Guha课题组、加州大学伯克利分校、ServiceNow和Hugging Face等机构的鼎力支持。
技术揭秘
StarCoder2-Instruct的数据生成流程主要包括三个核心步骤:
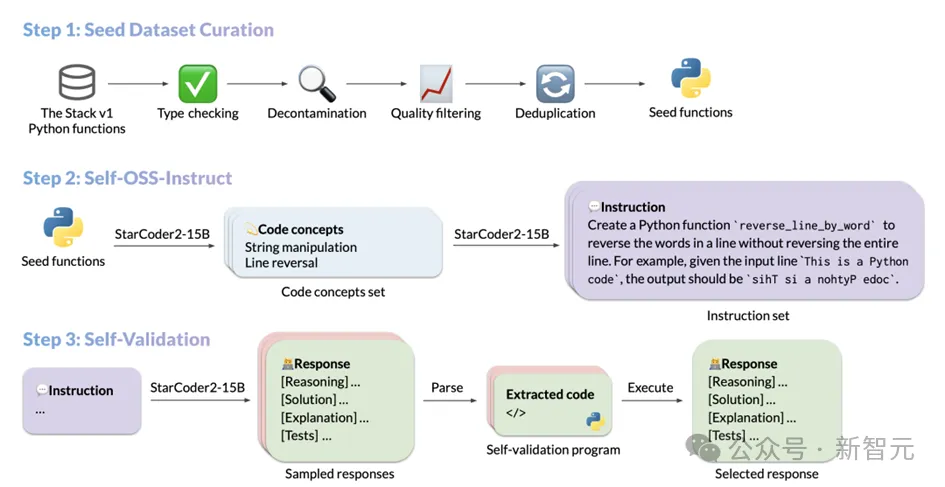
1. 种子代码片段的采集:团队从The Stack v1中筛选出高质量、多样化的种子函数,这些函数来自海量的获得许可的源代码语料库。通过严格的过滤和筛选,确保了种子代码的质量和多样性;
2. 多样化指令的生成:基于种子函数中的不同编程概念,StarCoder2-15B-Instruct能够创建出多样化且真实的代码指令。这些指令涵盖了从数据反序列化到列表连接、递归等丰富的编程场景;
3. 高质量响应的生成:对于每个指令,模型采用编译运行引导的自我验证方式,确保生成的响应是准确且高质量的。
每个步骤的具体操作如下:
精选种子代码片段的过程
为了提升代码模型在遵循指令方面的能力,模型需要广泛接触和学习不同的编程原理与实际操作。StarCoder2-15B-Instruct受到OSS-Instruct的启发,从开源代码片段中汲取灵感,尤其是The Stack V1中那些格式规范、结构清晰的Python种子函数。
在构建其基础数据集时,StarCoder2-15B-Instruct对The Stack V1进行了深度挖掘,选取了所有配备文档说明的Python函数,并借助autoimport功能自动分析并推断了这些函数所需的依赖项。
为了确保数据集的纯净性和高质量,StarCoder2-15B-Instruct对所有选取的函数进行了精细的过滤和筛选。
首先,通过Pyright类型检查器进行严格的类型检查,排除了所有可能产生静态错误的函数,从而保证了数据的准确性和可靠性。
接着,通过精确的字符串匹配技术,识别和剔除了与评估数据集存在潜在关联的代码和提示,以避免数据污染。在文档质量方面,StarCoder2-15B-Instruct更是采用了独特的筛选机制。
它利用自身的评估能力,通过向模型展示7个样本提示,让模型自行判断每个函数的文档质量是否达标,从而决定是否将其纳入最终的数据集。
这种基于模型自我判断的方法,不仅提高了数据筛选的效率和准确性,也确保了数据集的高质量和一致性。
最後,為了避免資料冗餘和重複,StarCoder2-15B-Instruct採用了MinHash和局部敏感雜湊演算法,對資料集中的函數進行了去重處理。透過設定0.5的Jaccard相似度閾值,有效去除了相似度較高的重複函數,確保了資料集的獨特性和多樣性。
經過這一系列的精細篩選和過濾,StarCoder2-15B-Instruct最終從500萬個帶有文檔的Python函數中,精選出了25萬個高質量的函數作為其種子資料集。此方法深受MultiPL-T資料收集流程的啟發。
多樣化指令的產生
#當StarCoder2-15B-Instruct完成了種子函數的收集後,它運用了Self-OSS-Instruct技術來創造多樣化的程式指令。這項技術的核心在於透過上下文學習,讓StarCoder2-15B基座模型能夠自主地為給定的種子程式碼片段產生對應的指令。
為實現這一目標,StarCoder2-15B-Instruct精心設計了16個範例,每個範例都遵循(程式碼片段,概念,指令)的結構。指令的產生過程被細分為兩個階段:
程式碼概念識別:在這一階段,StarCoder2-15B會針對每一個種子函數進行深入分析,並產生一個包含該函數中關鍵程式碼概念的清單。這些概念廣泛涵蓋了程式設計領域的基本原理和技術,如模式匹配、資料類型轉換等,這些對於開發者而言具有極高的實用價值。
指令建立:基於辨識出的程式碼概念,StarCoder2-15B會進一步產生與之對應的編碼任務指令。這個過程旨在確保產生的指令能夠準確地反映程式碼片段的核心功能和要求。
透過上述流程,StarCoder2-15B-Instruct最終成功產生了高達238k個指令,極大地豐富了其訓練資料集,並為其在程式設計任務中的表現提供了強有力的支持。
回應的自我驗證機制
#在取得Self-OSS-Instruct產生的指令後,StarCoder2-15B-Instruct的關鍵任務是為每個指令匹配高品質的回應。
傳統上,人們傾向於依賴如GPT-4等更強大的教師模型來獲取這些回應,但這種方式不僅可能面臨版權許可的難題,而且外部模型並非總是觸手可及或準確無誤。更重要的是,依賴外部模型可能引入教師與學生之間的分佈差異,這可能會影響最終結果的準確性。
為了克服這些挑戰,StarCoder2-15B-Instruct引進了一種自我驗證機制。這機制的核心概念是,讓StarCoder2-15B模型在產生自然語言回應後,自行建立對應的測試案例。這個過程類似於開發人員編寫程式碼後的自測流程。
具體而言,對於每一個指令,StarCoder2-15B會產生10個包含自然語言回應和對應測試案例的樣本。隨後,StarCoder2-15B-Instruct會在一個沙盒環境中執行這些測試案例,以驗證回應的有效性。任何在執行測試中失敗的樣本都會被過濾掉。
經過這嚴格的篩選過程,StarCoder2-15B-Instruct會從每個指令的通過測試的回應中隨機選取一個,加入最終的SFT資料集。整個過程中,StarCoder2-15B-Instruct為238k個指令產生了總計240萬個回應樣本(每個指令10個樣本)。在採用0.7的採樣策略後,有50萬個樣本成功通過了執行測試。
為了確保資料集的多樣性和質量,StarCoder2-15B-Instruct也進行了去重處理。最終,剩下5萬條指令,每個指令都配有一個隨機選取的、經過測試驗證的高品質回應。這些反應構成了StarCoder2-15B-Instruct最終的SFT資料集,為模型的後續訓練和應用提供了堅實的基礎。
StarCoder2-15B-Instruct的卓越表現與全面評估
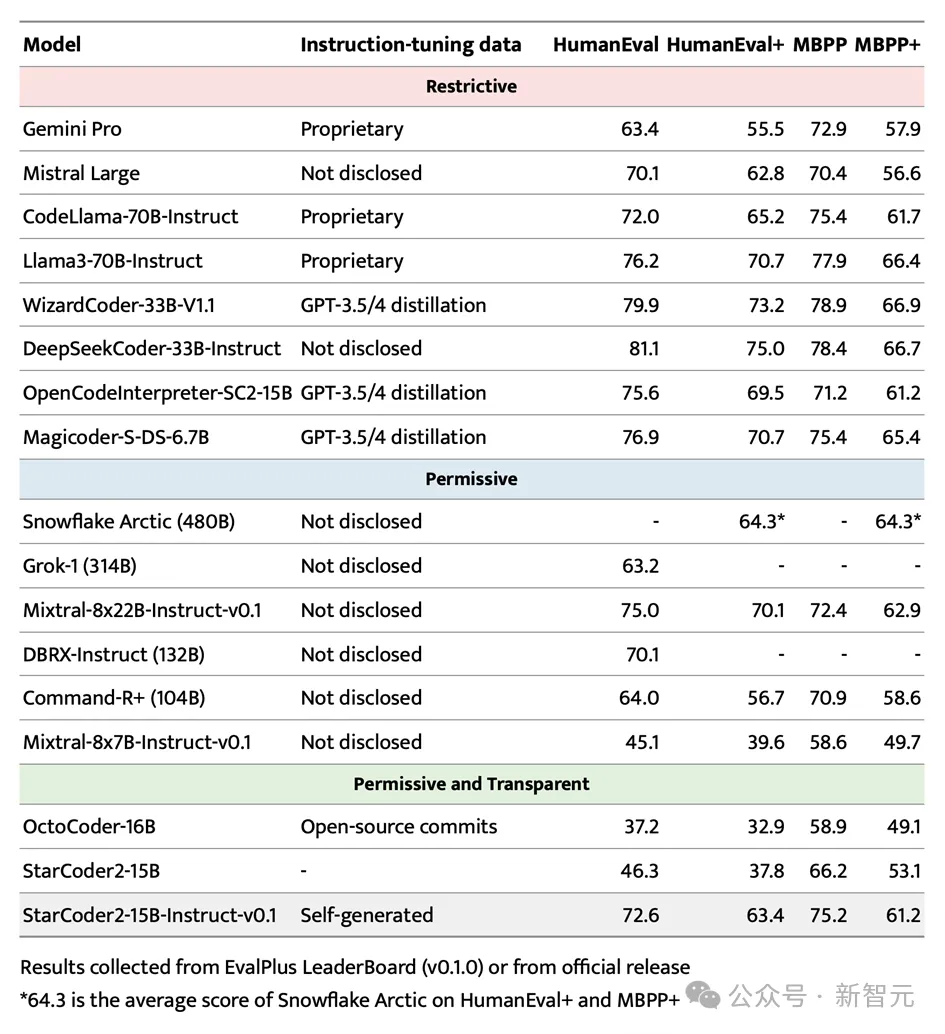
在備受矚目的EvalPlus基準測試中,StarCoder2- 15B-Instruct憑藉其規模優勢,成功脫穎而出,成為表現最出色的自主可控大型模型。
它不僅超越了規模更大的Grok-1 Command-R+和DBRX,還與Snowflake Arctic 480B和Mixtral-8x22B-Instruct等業界翹楚性能相當。
值得一提的是,StarCoder2-15B-Instruct是首个在HumanEval基准上达到70+得分的自主代码大模型,其训练过程完全透明,数据和方法的使用均符合法律法规。
在自主可控代码大模型领域,StarCoder2-15B-Instruct显著超越了之前的佼佼者OctoCoder,证明了其在该领域的领先地位。
即便与拥有限制性许可的大型强力模型如Gemini Pro和Mistral Large相比,StarCoder2-15B-Instruct依然展现出卓越的性能,并与CodeLlama-70B-Instruct平分秋色。更令人瞩目的是,StarCoder2-15B-Instruct完全依赖于自生成数据进行训练,其性能却能与基于GPT-3.5/4数据微调的OpenCodeInterpreter-SC2-15B相媲美。
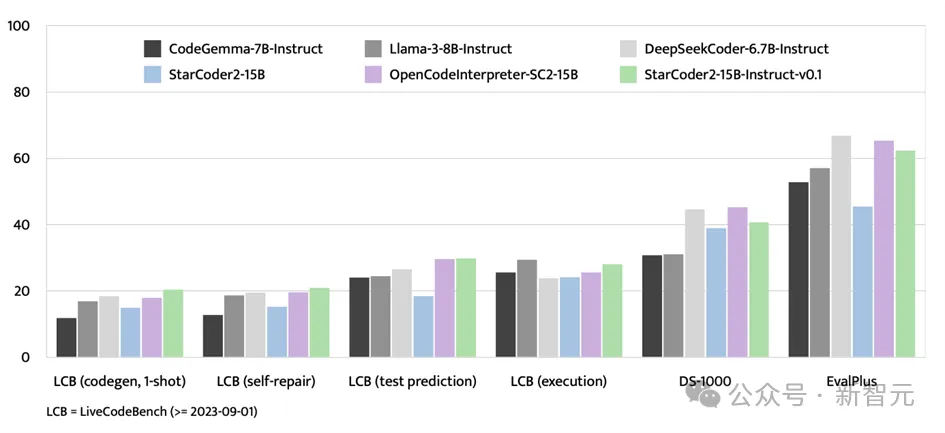
除了EvalPlus基准测试,StarCoder2-15B-Instruct在LiveCodeBench和DS-1000等评估平台上也展现出了强大的实力。
LiveCodeBench专注于评估2023年9月1日之后出现的编码挑战,而StarCoder2-15B-Instruct在该基准测试中取得了最优成绩,并且始终领先于使用GPT-4数据进行微调的OpenCodeInterpreter-SC2-15B
尽管DS-1000专注于数据科学任务,StarCoder2-15B-Instruct在训练数据中涉及的数据科学问题相对较少,但其在该基准测试中的表现依然强劲,显示出广泛的适应性和竞争力。
StarCoder2-15B-Instruct-v0.1的突破与启示
StarCoder2-15B-Instruct-v0.1的发布,标志着研究者们在代码模型自我调优领域迈出了重要一步。这款模型的成功实践,打破了以往必须依赖如GPT-4等强大外部教师模型的限制,展示了通过自我调优同样能够构建出性能卓越的代码模型。
StarCoder2-15B-Instruct-v0.1的核心在于其自我对齐策略在代码学习领域的成功应用。这一策略不仅提升了模型的性能,更重要的是,它赋予了模型更高的透明度和可解释性。这一点与Snowflake-Arctic、Grok-1、Mixtral-8x22B、DBRX和CommandR+等其他大型模型形成了鲜明对比,这些模型虽然强大,但往往因缺乏透明度而限制了其应用范围和可信赖度。
更令人欣喜的是,StarCoder2-15B-Instruct-v0.1已经将其数据集和整个训练流程——包括数据收集和训练过程——完全开源。这一举措不仅彰显了研究者的开放精神,也为未来该领域的研究和发展奠定了坚实的基础。
有理由相信,StarCoder2-15B-Instruct-v0.1的成功实践将激发更多研究者投入到代码模型自我调优领域的研究中,推动该领域的技术进步和应用拓展。同时,也期待这一领域的更多创新成果能够不断涌现,为人类社会的智能化发展注入新的动力。
作者简介
UIUC的张令明老师是一位在软件工程、程序语言和机器学习交叉领域具有深厚造诣的学者。他领导的课题组长期致力于基于AI大模型的自动软件合成、修复和验证研究,以及机器学习系统的可靠性提升。
近期,团队发布了多个创新性的代码大模型和测试基准数据集,并率先提出了一系列基于大模型的软件测试和修复技术。同时,在多个真实软件系统中成功挖掘出上千个新缺陷和漏洞,为提升软件质量做出了显著贡献。
以上是無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 比特幣值多少美金
Apr 28, 2025 pm 07:42 PM
比特幣值多少美金
Apr 28, 2025 pm 07:42 PM
比特幣的價格在20,000到30,000美元之間。 1. 比特幣自2009年以來價格波動劇烈,2017年達到近20,000美元,2021年達到近60,000美元。 2. 價格受市場需求、供應量、宏觀經濟環境等因素影響。 3. 通過交易所、移動應用和網站可獲取實時價格。 4. 比特幣價格波動性大,受市場情緒和外部因素驅動。 5. 與傳統金融市場有一定關係,受全球股市、美元強弱等影響。 6. 長期趨勢看漲,但需謹慎評估風險。
 全球幣圈十大交易所有哪些 排名前十的貨幣交易平台2025
Apr 28, 2025 pm 08:12 PM
全球幣圈十大交易所有哪些 排名前十的貨幣交易平台2025
Apr 28, 2025 pm 08:12 PM
2025年全球十大加密貨幣交易所包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、KuCoin、Bittrex和Poloniex,均以高交易量和安全性著稱。
 全球幣圈十大交易所有哪些 排名前十的貨幣交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球幣圈十大交易所有哪些 排名前十的貨幣交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球十大加密貨幣交易平台包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、KuCoin和Poloniex,均提供多種交易方式和強大的安全措施。
 解密Gate.io戰略升級:MeMebox 2.0如何重新定義加密資產管理?
Apr 28, 2025 pm 03:33 PM
解密Gate.io戰略升級:MeMebox 2.0如何重新定義加密資產管理?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0通過創新架構和性能突破重新定義了加密資產管理。 1) 它解決了資產孤島、收益衰減和安全與便利悖論三大痛點。 2) 通過智能資產樞紐、動態風險管理和收益增強引擎,提升了跨鏈轉賬速度、平均收益率和安全事件響應速度。 3) 為用戶提供資產可視化、策略自動化和治理一體化,實現了用戶價值重構。 4) 通過生態協同和合規化創新,增強了平台的整體效能。 5) 未來將推出智能合約保險池、預測市場集成和AI驅動資產配置,繼續引領行業發展。
 排名前十的虛擬幣交易app有哪 最新數字貨幣交易所排行榜
Apr 28, 2025 pm 08:03 PM
排名前十的虛擬幣交易app有哪 最新數字貨幣交易所排行榜
Apr 28, 2025 pm 08:03 PM
Binance、OKX、gate.io等十大數字貨幣交易所完善系統、高效多元化交易和嚴密安全措施嚴重推崇。
 排名靠前的貨幣交易平台有哪些 最新虛擬幣交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
排名靠前的貨幣交易平台有哪些 最新虛擬幣交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
目前排名前十的虛擬幣交易所:1.幣安,2. OKX,3. Gate.io,4。幣庫,5。海妖,6。火幣全球站,7.拜比特,8.庫幣,9.比特幣,10。比特戳。
 靠譜的數字貨幣交易平台推薦 全球十大數字貨幣交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠譜的數字貨幣交易平台推薦 全球十大數字貨幣交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠谱的数字货币交易平台推荐:1. OKX,2. Binance,3. Coinbase,4. Kraken,5. Huobi,6. KuCoin,7. Bitfinex,8. Gemini,9. Bitstamp,10. Poloniex,这些平台均以其安全性、用户体验和多样化的功能著称,适合不同层次的用户进行数字货币交易
 C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
使用C 中的chrono庫可以讓你更加精確地控制時間和時間間隔,讓我們來探討一下這個庫的魅力所在吧。 C 的chrono庫是標準庫的一部分,它提供了一種現代化的方式來處理時間和時間間隔。對於那些曾經飽受time.h和ctime折磨的程序員來說,chrono無疑是一個福音。它不僅提高了代碼的可讀性和可維護性,還提供了更高的精度和靈活性。讓我們從基礎開始,chrono庫主要包括以下幾個關鍵組件:std::chrono::system_clock:表示系統時鐘,用於獲取當前時間。 std::chron
