

Google「誠意之作」,開源9B、27B版Gemma2,主打高效、經濟!

性能翻倍的Gemma 2, 讓同量級的Llama3怎麼玩?


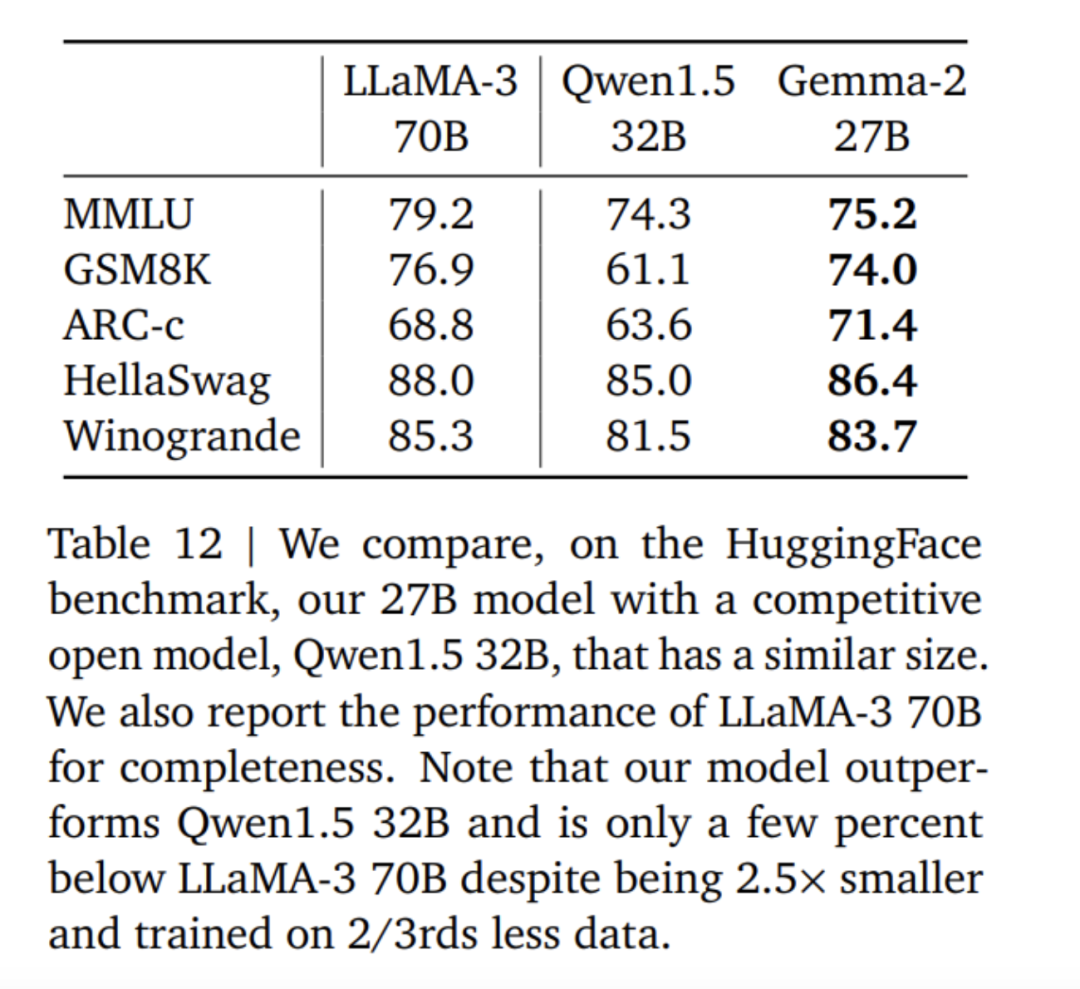
性能卓越:Gemma 2 27B模型在其同體積類別中提供了最佳性能,甚至可以與體積超過其兩倍的模型競爭。 9B Gemma 2模型在其同等體積類別中也表現出色,並超越了Llama 3 8B和其他同類開放模型。 高效率、低成本:27B Gemma 2模型設計用於在單一Google Cloud TPU主機、NVIDIA A100 80GB Tensor Core GPU或NVIDIA H100 Tensor Core GPU上以全精度高效運行推理,在保持高性能的同時大幅降低成本。這使得AI部署更加便利和經濟實惠。 超高速推理:Gemma 2經過最佳化,能夠在各種硬體上以驚人的速度運行,無論是強大的遊戲筆記本、高階桌上型電腦,還是基於雲端的設定。使用者可以在Google AI Studio上嘗試全精度運行Gemma 2,也可以在CPU上使用Gemma.cpp的量化版本解鎖本地性能,或者透過Hugging Face Transformers在家用電腦上使用NVIDIA RTX或GeForce RTX進行嘗試。

以上是 Gemma2 與 Llama3、Grok-1 的得分數據對比。
其實從各項得分資料來看,此次開源的 9B 大模型優勢並不是特別明顯。近1個月前智譜AI 開源的國產大模式 GLM-4-9B 更具優勢。

開放且易於存取:與原始Gemma模型一樣,Gemma 2允許開發者和研究人員分享和商業化創新成果。 廣泛的框架相容性:Gemma 2相容於主要的AI框架,如Hugging Face Transformers,以及透過Keras 3.0、vLLM、Gemma.cpp、Llama.cpp和Ollama原生支援的JAX、PyTorch和Tensor,使其能夠輕鬆與使用者偏好的工具和工作流程結合。此外,Gemma已通過NVIDIA TensorRT-LLM優化,可以在NVIDIA加速的基礎設施上運行,或作為NVIDIA NIM推理微服務運行,未來還將優化NVIDIA的NeMo,並且可以使用Keras和Hugging Face進行微調。除此之外,谷歌正在積極升級微調能力。 輕鬆部署:從下個月開始,Google Cloud客戶將能夠在Vertex AI上輕鬆部署和管理Gemma 2。
在最新的部落格中,Google宣布向所有開發者開放了Gemini 1.5 Pro的200萬token上下文視窗存取權限。但是,隨著上下文視窗的增加,輸入成本也可能增加。為了幫助開發者減少使用相同token的多prompt任務成本,Google貼心地在Gemini API中為Gemini 1.5 Pro和1.5 Flash推出了上下文快取功能。 為解決大型語言模型在處理數學或資料推理時需要產生和執行程式碼來提高準確性,Google在Gemini 1.5 Pro和1.5 Flash中啟用了程式碼執行功能。開啟後,模型可以動態產生並運行Python程式碼,並從結果中迭代學習,直到達到所需的最終輸出。執行沙盒不連接互聯網,並標配一些數值庫,開發者只需根據模型的輸出token進行計費。這是Google在模型功能中首次引入程式碼執行的步驟,今天即可透過Gemini API和Google AI Studio中的「進階設定」使用。 谷歌希望讓所有開發者都能接觸到AI,無論是透過API金鑰整合Gemini模型,或是使用開放模型Gemma 2。為了幫助開發者動手操作Gemma 2模型,Google團隊將在Google AI Studio中提供其用於實驗。

-
論文網址:https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf blog technology/developers/google-gemma-2/

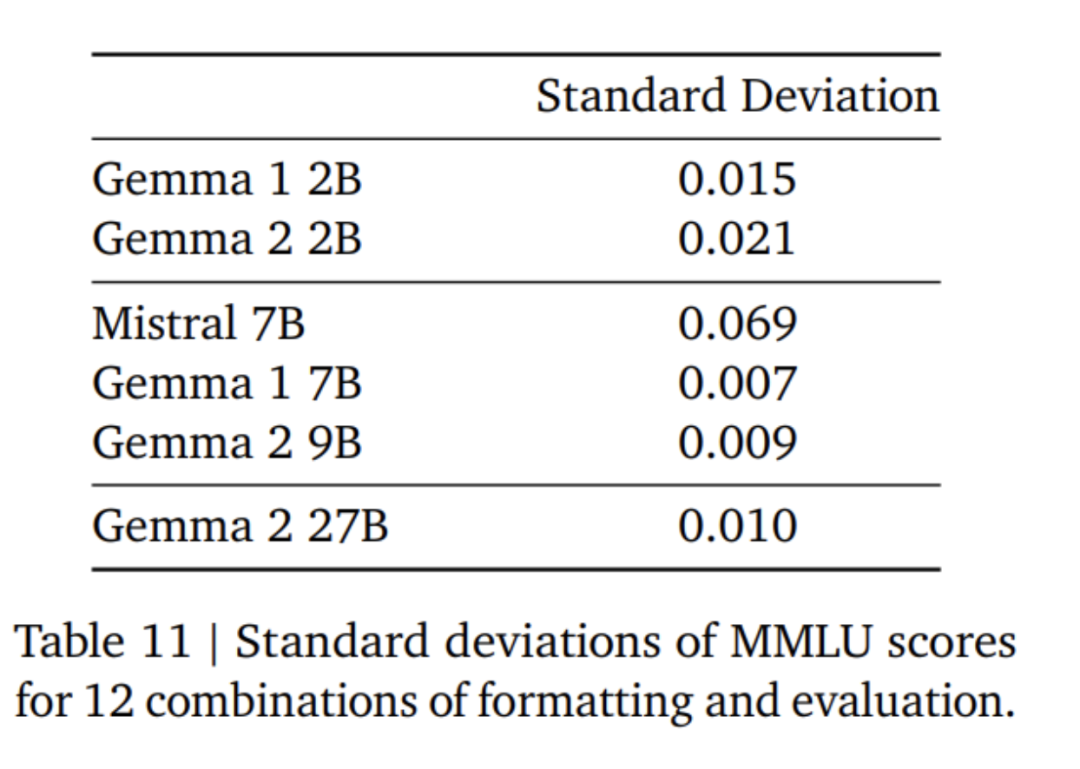
局部滑動視窗和全局注意力。研究團隊在每隔一層交替使用局部滑動視窗注意力和全局注意力。局部注意力層的滑動視窗大小設定為4096個token,而全域注意力層的跨距設定為8192個token。 Logit軟封頂。根據Gemini 1.5的方法,研究團隊在每個注意力層和最終層限制logit,使得logit的值保持在−soft_cap和+soft_cap之間。 對於9B和27B模型,研究團隊將注意力對數封頂設定為50.0,最終對數封頂設定為30.0。截至本文發表時,注意力logit軟封頂與常見的FlashAttention實作不相容,因此他們已從使用FlashAttention的庫中移除了此功能。研究團隊對模型生成進行了有無注意力logit軟封頂的消融實驗,發現在大多數預訓練和後期評估中,生成品質幾乎不受影響。本文中的所有評估均使用包含注意力logit軟封頂的完整模型架構。然而,某些下游性能可能仍會受到此移除的輕微影響。 使用RMSNorm進行post-norm 和pre-norm。為了穩定訓練,研究團隊使用RMSNorm對每個變換子層、注意力層和前饋層的輸入和輸出進行歸一化。 分組查詢注意力。 27B和9B模型均使用GQA,num_groups = 2,基於消融實驗顯示在保持下游性能的同時提高了推理速度。

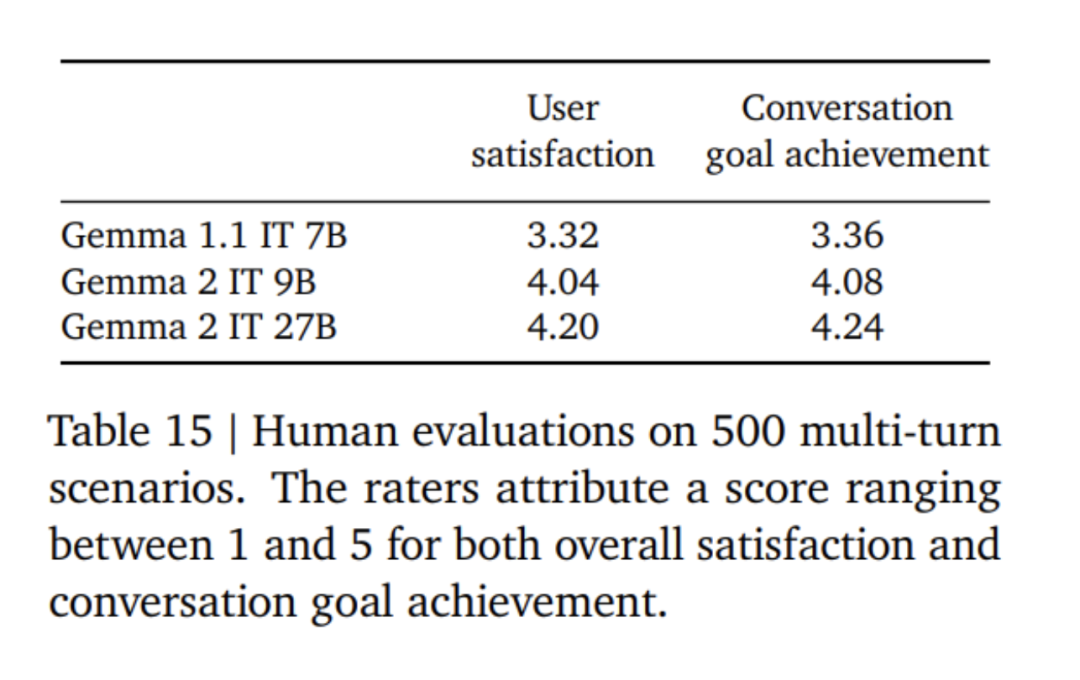
首先,在混合的純文本、純英文合成和人工生成的prompt-響應對上應用監督微調(SFT)。 然後,在這些模型上應用基於獎勵模型(RLHF)的強化學習,獎勵模型訓練基於token的純英文偏好數據,策略則與SFT階段使用相同的prompt。 最後,透過平均每個階段獲得的模型以提高整體性能。最終的資料混合和訓練後方法,包括調優的超參數,都是基於在提高模型有用性的同時最小化與安全性和幻覺相關的模型危害來選擇的。





以上是Google「誠意之作」,開源9B、27B版Gemma2,主打高效、經濟!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 歐易okex賬號怎麼註冊、使用、註銷教程
Mar 31, 2025 pm 04:21 PM
歐易okex賬號怎麼註冊、使用、註銷教程
Mar 31, 2025 pm 04:21 PM
本文詳細介紹了歐易OKEx賬號的註冊、使用和註銷流程。註冊需下載APP,輸入手機號或郵箱註冊,完成實名認證。使用方面涵蓋登錄、充值提現、交易以及安全設置等操作步驟。而註銷賬號則需要聯繫歐易OKEx客服,提供必要信息並等待處理,最終獲得賬號註銷確認。 通過本文,用戶可以輕鬆掌握歐易OKEx賬號的完整生命週期管理,安全便捷地進行數字資產交易。
 如何優化jieba分詞以改善景區評論的關鍵詞提取效果?
Apr 01, 2025 pm 06:24 PM
如何優化jieba分詞以改善景區評論的關鍵詞提取效果?
Apr 01, 2025 pm 06:24 PM
如何優化jieba分詞以改善景區評論的關鍵詞提取?在使用jieba分詞處理景區評論數據時,如果發現分詞結果不理�...
 虛擬幣最老的幣排行榜最新更新
Apr 22, 2025 am 07:18 AM
虛擬幣最老的幣排行榜最新更新
Apr 22, 2025 am 07:18 AM
虛擬貨幣“最老”排行榜如下:1. 比特幣(BTC),發行於2009年1月3日,是首個去中心化數字貨幣。 2. 萊特幣(LTC),發行於2011年10月7日,被稱為“比特幣的輕量版”。 3. 瑞波幣(XRP),發行於2011年,專為跨境支付設計。 4. 狗狗幣(DOGE),發行於2013年12月6日,基於萊特幣代碼的“迷因幣”。 5. 以太坊(ETH),發行於2015年7月30日,首個支持智能合約的平台。 6. 泰達幣(USDT),發行於2014年,是首個與美元1:1錨定的穩定幣。 7. 艾達幣(ADA),發
 Web IDE目錄樹縮進:為什麼谷歌瀏覽器和火狐瀏覽器渲染結果不同?
Apr 04, 2025 pm 10:15 PM
Web IDE目錄樹縮進:為什麼谷歌瀏覽器和火狐瀏覽器渲染結果不同?
Apr 04, 2025 pm 10:15 PM
關於WebIDE目錄樹在不同瀏覽器下的渲染差異本文將探討一個在谷歌瀏覽器和火狐瀏覽器中重命名Web...
 在HTTP頁面中如何解決navigator.mediaDevices返回undefined的問題?
Apr 05, 2025 am 07:30 AM
在HTTP頁面中如何解決navigator.mediaDevices返回undefined的問題?
Apr 05, 2025 am 07:30 AM
H5部署後視頻媒體獲取問題處理在部署H5應用時,有時會遇到頁面視頻媒體獲取的問題,特別是當使用navigator.medi...
 谷歌和微軟身份驗證器是否支持HOTP算法?如何解決不支持的問題?
Apr 02, 2025 pm 03:39 PM
谷歌和微軟身份驗證器是否支持HOTP算法?如何解決不支持的問題?
Apr 02, 2025 pm 03:39 PM
關於谷歌和微軟身份驗證器是否支持HOTP算法的探討在使用雙因素身份驗證時,我們經常會用到像谷歌和微軟這�...
 歐易網頁版怎麼提現
Mar 27, 2025 pm 05:03 PM
歐易網頁版怎麼提現
Mar 27, 2025 pm 05:03 PM
歐易網頁版提現流程:登錄賬戶,進入資產頁面,選擇提現幣種和方式(鏈上或法幣)。鏈上提現需填寫正確提現地址和匹配網絡,法幣提現需綁定銀行賬戶。完成安全驗證後提交申請,等待審核到賬。務必核對地址、網絡等信息,注意手續費和最低提現金額。
 gate官網登錄地址 gateio網頁版登錄入口地址
Mar 31, 2025 pm 01:15 PM
gate官網登錄地址 gateio網頁版登錄入口地址
Mar 31, 2025 pm 01:15 PM
Gate.io 不僅提供基本的買賣交易功能,還推出了多種創新的交易模式和服務,滿足不同用戶的需求。平台還提供了豐富的交易工具和分析功能,幫助用戶做出更明智的投資決策。用戶可以將持有的加密貨幣質押到平台上,參與挖礦活動,獲取額外的收益。
