

300多篇相關研究,復旦、南洋理工最新多模態影像編輯綜述論文


AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
該文章的第一作者帥欣成,目前在復旦大學FVL實驗室攻讀博士學位,畢業於上海交通大學。他的主要研究方向包括影像和影片編輯以及多模態學習。

論文題目:A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models 發表單位:復旦大學FVL 實驗室,南洋理工大學 - 發表單位:復旦大學FVL 實驗室,南洋理工大學 發表單位:復旦大學FVL 實驗室,南洋理工大學
.org/abs/2406.14555
2.1 關於編輯任務的定義與討論範圍。相較於現有的演算法以及先前的編輯綜述,本文對於影像編輯任務的定義更加廣泛。具體的,本文將編輯任務分為 content-aware 和 content-free 場景群組。其中 content-aware 組內的場景為先前的文獻所討論的主要任務,它們的共通性是保留圖像中的一些低階語義特徵,如編輯無關區域的像素內容,或圖像結構。此外,我們開創性地將客製化任務(customization)納入到content-free 場景組中,將這一類保留高級語義(如主體身份信息,或者其他細粒度屬性)的任務作為對常規的編輯場景的補充。 

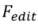 3.1 Inversion 演算法。 Inversion 演算法
3.1 Inversion 演算法。 Inversion 演算法(inversion clue),並以對應的來源文字描述
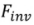 兩種類型的 inversion 演算法。其可以形式化為:
兩種類型的 inversion 演算法。其可以形式化為: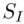
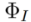
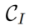 Tuning-based inversion
Tuning-based inversion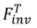 透過原有的 diffusion 訓練過程將來源影像集合植入擴散模型的生成分佈中。形式化過程為:
透過原有的 diffusion 訓練過程將來源影像集合植入擴散模型的生成分佈中。形式化過程為: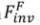

 其中
其中
。 
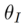
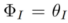 Forward-based inversion
Forward-based inversion)。形式化過程為:
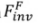
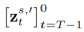
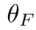 為方法中引入的參數,用於最小化
為方法中引入的參數,用於最小化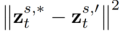 ,其中,
,其中,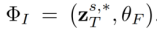 。
。 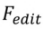 根據
根據 和多模態引導集合
和多模態引導集合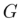 來產生最終的編輯結果
來產生最終的編輯結果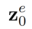 。包含 attention-based
。包含 attention-based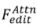 ,blending-based
,blending-based ,score-based
,score-based 以及 optimization-based
以及 optimization-based 的 editing 演算法。其可以被形式化為:
的 editing 演算法。其可以被形式化為:
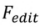 進行瞭如下操作:
進行瞭如下操作:
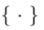 中的操作表示編輯演算法對於擴散模型的取樣,用於確保編輯後的影像
中的操作表示編輯演算法對於擴散模型的取樣,用於確保編輯後的影像 與來源影像集合
與來源影像集合 的一致性,並反應出
的一致性,並反應出 中引導條件所指明的視覺變換。
中引導條件所指明的視覺變換。 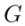


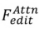 的形式化過程:
的形式化過程:

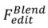 的形式化過程:
的形式化過程: 🎎 based editing
🎎 based editing
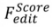
 3.3 Training-Based 的編輯方法。與 training-free 的方法不同的是,training-based 演算法透過在任務特定的資料集中直接學習來源影像集合到編輯影像的映射。這一類演算法可以看作是 tuning-based inversion 的擴展,即透過額外引入的參數將來源影像編碼到生成分佈中。在這類演算法中,最重要的是如何將來源影像注入 T2I 模型中,以下是針對不同編輯場景的注入方案。
3.3 Training-Based 的編輯方法。與 training-free 的方法不同的是,training-based 演算法透過在任務特定的資料集中直接學習來源影像集合到編輯影像的映射。這一類演算法可以看作是 tuning-based inversion 的擴展,即透過額外引入的參數將來源影像編碼到生成分佈中。在這類演算法中,最重要的是如何將來源影像注入 T2I 模型中,以下是針對不同編輯場景的注入方案。

Content-aware 任務的注入方案:

圖3. Content-free 任務的注入方案




圖 7.中關於optimization-based editing

5.不同組合在文字引導編輯場景下的比較
 結果分析以及更多實驗結果請查閱原始論文。
結果分析以及更多實驗結果請查閱原始論文。
以上是300多篇相關研究,復旦、南洋理工最新多模態影像編輯綜述論文的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 ControlNet作者又出爆款!一張圖生成繪畫全過程,兩天狂攬1.4k Star
Jul 17, 2024 am 01:56 AM
ControlNet作者又出爆款!一張圖生成繪畫全過程,兩天狂攬1.4k Star
Jul 17, 2024 am 01:56 AM
同樣是圖生視頻,PaintsUndo走出了不一樣的路線。 ControlNet作者LvminZhang又開始整活了!這次瞄準繪畫領域。新項目PaintsUndo剛上線不久,就收穫1.4kstar(還在瘋狂漲)。項目地址:https://github.com/lllyasviel/Paints-UNDO透過這個項目,用戶輸入一張靜態圖像,PaintsUndo就能自動幫你生成整個繪畫的全過程視頻,從線稿到成品都有跡可循。繪製過程,線條變化多端甚是神奇,最終視頻結果和原始圖像非常相似:我們再來看一個完整的繪
 arXiv論文可以發「彈幕」了,史丹佛alphaXiv討論平台上線,LeCun按讚
Aug 01, 2024 pm 05:18 PM
arXiv論文可以發「彈幕」了,史丹佛alphaXiv討論平台上線,LeCun按讚
Aug 01, 2024 pm 05:18 PM
乾杯!當論文討論細緻到詞句,是什麼體驗?最近,史丹佛大學的學生針對arXiv論文創建了一個開放討論論壇——alphaXiv,可以直接在任何arXiv論文之上發布問題和評論。網站連結:https://alphaxiv.org/其實不需要專門訪問這個網站,只需將任何URL中的arXiv更改為alphaXiv就可以直接在alphaXiv論壇上打開相應論文:可以精準定位到論文中的段落、句子:右側討論區,使用者可以發表問題詢問作者論文想法、細節,例如:也可以針對論文內容發表評論,例如:「給出至
 登頂開源AI軟體工程師榜首,UIUC無Agent方案輕鬆解決SWE-bench真實程式設計問題
Jul 17, 2024 pm 10:02 PM
登頂開源AI軟體工程師榜首,UIUC無Agent方案輕鬆解決SWE-bench真實程式設計問題
Jul 17, 2024 pm 10:02 PM
AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com這篇論文的作者皆來自伊利諾大學香檳分校(UIUC)張令明老師團隊,包括:StevenXia,四年級博士生,研究方向是基於AI大模型的自動代碼修復;鄧茵琳,四年級博士生,研究方
 從RLHF到DPO再到TDPO,大模型對齊演算法已經是「token-level」
Jun 24, 2024 pm 03:04 PM
從RLHF到DPO再到TDPO,大模型對齊演算法已經是「token-level」
Jun 24, 2024 pm 03:04 PM
AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com在人工智慧領域的發展過程中,對大語言模型(LLM)的控制與指導始終是核心挑戰之一,旨在確保這些模型既強大又安全地服務人類社會。早期的努力集中在透過人類回饋的強化學習方法(RL
 OpenAI超級對齊團隊遺作:兩個大模型博弈一番,輸出更好懂了
Jul 19, 2024 am 01:29 AM
OpenAI超級對齊團隊遺作:兩個大模型博弈一番,輸出更好懂了
Jul 19, 2024 am 01:29 AM
如果AI模型給的答案一點也看不懂,你敢用嗎?隨著機器學習系統在更重要的領域中得到應用,證明為什麼我們可以信任它們的輸出,並明確何時不應信任它們,變得越來越重要。獲得對複雜系統輸出結果信任的一個可行方法是,要求系統對其輸出產生一種解釋,這種解釋對人類或另一個受信任的系統來說是可讀的,即可以完全理解以至於任何可能的錯誤都可以被發現。例如,為了建立對司法系統的信任,我們要求法院提供清晰易讀的書面意見,解釋並支持其決策。對於大型語言模型來說,我們也可以採用類似的方法。不過,在採用這種方法時,確保語言模型生
 黎曼猜想显著突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
黎曼猜想显著突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
最近,被稱為千禧年七大難題之一的黎曼猜想迎來了新突破。黎曼猜想是數學中一個非常重要的未解決問題,與素數分佈的精確性質有關(素數是那些只能被1和自身整除的數字,它們在數論中扮演著基礎性的角色)。在當今的數學文獻中,已有超過一千個數學命題以黎曼猜想(或其推廣形式)的成立為前提。也就是說,黎曼猜想及其推廣形式一旦被證明,這一千多個命題將被確立為定理,對數學領域產生深遠的影響;而如果黎曼猜想被證明是錯誤的,那麼這些命題中的一部分也將隨之失去其有效性。新的突破來自MIT數學教授LarryGuth和牛津大學
 LLM用於時序預測真的不行,連推理能力都沒用到
Jul 15, 2024 pm 03:59 PM
LLM用於時序預測真的不行,連推理能力都沒用到
Jul 15, 2024 pm 03:59 PM
語言模型真的能用於時序預測嗎?根據貝特里奇頭條定律(任何以問號結尾的新聞標題,都能夠用「不」來回答),答案應該是否定的。事實似乎也果然如此:強大如斯的LLM並不能很好地處理時序資料。時序,即時間序列,顧名思義,是指一組依照時間發生先後順序排列的資料點序列。在許多領域,時序分析都很關鍵,包括疾病傳播預測、零售分析、醫療和金融。在時序分析領域,近期不少研究者都在研究如何使用大型語言模型(LLM)來分類、預測和偵測時間序列中的異常。這些論文假設擅長處理文本中順序依賴關係的語言模型也能泛化用於時間序
 首個基於Mamba的MLLM來了!模型權重、訓練程式碼等已全部開源
Jul 17, 2024 am 02:46 AM
首個基於Mamba的MLLM來了!模型權重、訓練程式碼等已全部開源
Jul 17, 2024 am 02:46 AM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。引言近年来,多模态大型语言模型(MLLM)在各个领域的应用取得了显著的成功。然而,作为许多下游任务的基础模型,当前的MLLM由众所周知的Transformer网络构成,这种网
