檢索增強式產生(RAG)是一種使用檢索提升語言模型的技術。具體來說,就是在語言模型生成答案之前,先從廣泛的文檔資料庫中檢索相關信息,然後利用這些信息來引導生成過程。這種技術能大幅提升內容的準確性和相關性,並能有效緩解幻覺問題,提高知識更新的速度,並增強內容生成的可追溯性。 RAG 無疑是最令人興奮的人工智慧研究領域之一。有關 RAG 的更多詳情請參閱本站專欄文章《專補大模型短板的RAG有哪些新進展?這篇綜述講明白了》。 但 RAG 也並非完美,使用者在使用時也常會遭遇一些「痛點」。近日,英偉達生成式AI高級解決方案架構師Wenqi Glantz 在 Towards Data Science 發布了一篇文章,梳理了 12 個 RAG 的痛點並給出了相應的解決方案。 
其中7 個痛點(見下圖)來自Barnett et al. 的論文「S.S. Generation System》,此外還另外增加了5 個常見痛點。 這些痛點對應的解決方案如下:
知識庫中缺失上下文。當知識庫中沒有答案時,RAG 系統會提供一個看似可信但不正確的答案,而不會承認它不知道。使用者會收到錯誤訊息,遭遇挫折。 輸入資料,那也必定垃圾。如果你的來源資料品質低劣,例如包含互相衝突的訊息,那麼不管你的 RAG 工作建構得多麼好,它都不可能用你輸入的垃圾神奇地輸出高品質結果。這個解決方案不僅適用於這個痛點,也適用於本文列出的所有痛點。任何 RAG 工作流程想要獲得優良表現,都必須先清潔資料。
- 移除雜訊和不相關資訊:這包括移除特殊字元、停用詞(stop words,如the 和a 和a )、HTML 標籤。
- 識別和糾正錯誤:包括拼字錯誤、錯字和語法錯誤。可以使用拼字檢查器和語言模型等工具來解決這個問題。
- 去重:移除重複資料記錄或可能導致檢索過程偏差的相似記錄。
unstructured.io 的核心軟體庫提供了一整套清潔工具可以幫助解決這些數據清潔需求。值得一試。 對於因為資訊缺乏而導致系統給出看似可信卻不正確結果的問題,更好的提詞設計能提供很大幫助。透過為系統給予「如果你不確定答案是什麼,就告訴我你不知道」這樣的指示,就能鼓勵模型承認自己的限制,並更透明地向使用者傳達它的不確定。雖然不能保證 100% 準確度,但在清潔資料之後,精心設計 prompt 是最好的做法之一。 初始檢索過程中缺失上下文。在系統的檢索元件傳回的結果中,關鍵性的文件可能並不靠前。正確的答案被忽略了,這會導致系統無法給出準確回應。上述論文寫道:「問題的答案就在文件中,但排名不夠高,就沒有返回給用戶。」chunk_size 和similarity_top_k 這兩個參數可用於管理RAG 模型的資料檢索過程的效率和效果。調整這兩個參數會影響被檢索資訊的計算效率和品質之間的權衡。作者在之前一篇文章中探索了對chunk_size 和similarity_top_k 進行超參數微調的細節:請訪問:https://medium.com/gitconnected/automating-hyperparameter-indexning-with-llamadama 72fdd68e3b90 param_tuner = ParamTuner(param_fn=objective_function_semantic_similarity,param_dict=param_dict,fixed_param_dict=fixed_param_dict,show_progress=True,)results = param_tuner.tune()
登入後複製
# contains the parameters that need to be tunedparam_dict = {"chunk_size": [256, 512, 1024], "top_k": [1, 2, 5]}# contains parameters remaining fixed across all runs of the tuning processfixed_param_dict = {"docs": documents,"eval_qs": eval_qs,"ref_response_strs": ref_response_strs,}def objective_function_semantic_similarity(params_dict):chunk_size = params_dict["chunk_size"]docs = params_dict["docs"]top_k = params_dict["top_k"]eval_qs = params_dict["eval_qs"]ref_response_strs = params_dict["ref_response_strs"]# build indexindex = _build_index(chunk_size, docs)# query enginequery_engine = index.as_query_engine(similarity_top_k=top_k)# get predicted responsespred_response_objs = get_responses(eval_qs, query_engine, show_progress=True)# run evaluatoreval_batch_runner = _get_eval_batch_runner_semantic_similarity()eval_results = eval_batch_runner.evaluate_responses(eval_qs, responses=pred_response_objs, reference=ref_response_strs)# get semantic similarity metricmean_score = np.array([r.score for r in eval_results["semantic_similarity"]]).mean() return RunResult(score=mean_score, params=params_dict)登入後複製
_objective_function_dicmantic_simiity 的定義值
import osfrom llama_index.postprocessor.cohere_rerank import CohereRerankapi_key = os.environ["COHERE_API_KEY"]cohere_rerank = CohereRerank(api_key=api_key, top_n=2) # return top 2 nodes from rerankerquery_engine = index.as_query_engine(similarity_top_k=10, # we can set a high top_k here to ensure maximum relevant retrievalnode_postprocessors=[cohere_rerank], # pass the reranker to node_postprocessors)response = query_engine.query("What did Sam Altman do in this essay?",)登入後複製
參數優化的完整筆記:
https://docs.llamaindex.ai/en/stable/examples/param_optimizer/param_optimizer/在將檢索結果發送給LLM 之前對它們進行重新排名可以大幅提升RAG 效能。
這個LlamaIndex 筆記(https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/CohereRerank.html )示範了以下兩種做法的差異:
🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🜟排名工具(reranker),直接檢索最前面的2 個節點,進行不準確的檢索。 🎜🎜🎜🎜檢索最前面的 10 個節點並使用 CohereRerank 進行重新排名並返回最前面的 2 個節點,進行準確的檢索。 🎜🎜🎜🎜finetune_engine = SentenceTransformersFinetuneEngine(train_dataset,model_id="BAAI/bge-small-en",model_output_path="test_model",val_dataset=val_dataset,)finetune_engine.finetune()embed_model = finetune_engine.get_finetuned_model()
登入後複製
登入後複製
finetune_engine = SentenceTransformersFinetuneEngine(train_dataset,model_id="BAAI/bge-small-en",model_output_path="test_model",val_dataset=val_dataset,)finetune_engine.finetune()embed_model = finetune_engine.get_finetuned_model()
登入後複製
登入後複製
from llama_index.core.query_engine import RetrieverQueryEnginefrom llama_index.core.response_synthesizers import CompactAndRefinefrom llama_index.postprocessor.longllmlingua import LongLLMLinguaPostprocessorfrom llama_index.core import QueryBundlenode_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder},)retrieved_nodes = retriever.retrieve(query_str)synthesizer = CompactAndRefine()# outline steps in RetrieverQueryEngine for clarity:# postprocess (compress), synthesizenew_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=query_str))print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))response = synthesizer.synthesize(query_str, new_retrieved_nodes)登入後複製
from llama_index.core.postprocessor import LongContextReorderreorder = LongContextReorder()reorder_engine = index.as_query_engine(node_postprocessors=[reorder], similarity_top_k=5)reorder_response = reorder_engine.query("Did the author meet Sam Altman?")登入後複製
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.core.output_parsers import LangchainOutputParserfrom llama_index.llms.openai import OpenAIfrom langchain.output_parsers import StructuredOutputParser, ResponseSchema# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex.from_documents(documents)# define output schemaresponse_schemas = [ResponseSchema(name="Education",description="Describes the author's educational experience/background.",),ResponseSchema( name="Work",description="Describes the author's work experience/background.",),]# define output parserlc_output_parser = StructuredOutputParser.from_response_schemas(response_schemas)output_parser = LangchainOutputParser(lc_output_parser)# Attach output parser to LLMllm = OpenAI(output_parser=output_parser)# obtain a structured responsequery_engine = index.as_query_engine(llm=llm)response = query_engine.query("What are a few things the author did growing up?",)print(str(response))登入後複製
- LLM 文本补全 Pydantic 程序:这些程序使用文本补全 API 加上输出解析,可将输入文本转换成用户定义的结构化对象。
- LLM 函数调用 Pydantic 程序:通过利用 LLM 函数调用 API,这些程序可将输入文本转换成用户指定的结构化对象。
- 预封装 Pydantic 程序:其设计目标是将输入文本转换成预定义的结构化对象。
下面是来自 OpenAI pydantic 程序的代码。LlamaIndex 的文档给出了更多相关细节,并且其中还包含不同 Pydantic 程序的笔记本/指南的链接:https://docs.llamaindex.ai/en/stable/module_guides/querying/structured_outputs/pydantic_program.htmlOpenAI JSON 模式可让我们通过将 response_format 设置成 { "type": "json_object" } 来启用 JSON 模式的响应。当启用了 JSON 模式时,模型就只会生成能解析成有效 JSON 对象的字符串。虽然 JSON 模式会强制设定输出格式,但它无助于针对指定架构进行验证。更多细节请访问这个文档:https://docs.llamaindex.ai/en/stable/examples/llm/openai_json_vs_function_calling.html输出具体说明的层级不对。响应可能缺乏必要细节或具体说明,这往往需要后续的问题来进行澄清。这样一来,答案可能太过模糊或笼统,无法有效满足用户的需求。当答案的粒度不符合期望时,可以改进检索策略。可能解决这个痛点的高级检索策略包括:有关高级检索的更多详情可访问:https://towardsdatascience.com/jump-start-your-rag-pipelines-with-advanced-retrieval-llamapacks-and-benchmark-with-lighthouz-ai-80a09b7c7d9d输出不完备。给出的响应没有错,但只是一部分,未能提供全部细节,即便这些信息存在于可访问的上下文中。举个例子,如果某人问「文档 A、B、C 主要讨论了哪些方面?」为了得到全面的答案,更有效的做法可能是单独询问各个文档。原生版的 RAG 方法通常很难处理比较问题。为了提升 RAG 的推理能力,一种很好的方法是添加一个查询理解层——在实际查询储存的向量前增加查询变换。查询变换有四种:- 路由:保留初始查询,同时确定其相关的适当工具子集。然后,将这些工具指定为合适的选项。
- 查询重写:维持所选工具,但以多种方式重写查询,再将其应用于同一工具集。
- 子问题:将查询分解成几个较小的问题,每一个小问题的目标都是不同的工具,这由它们的元数据决定。
- ReAct 智能体工具选择:基于原始查询,决定使用哪个工具并构建具体的查询来基于该工具运行。
下面这段代码展示了如何使用 HyDE(Hypothetical Document Embeddings)这种查询重写技术。给定一个自然语言查询,首先生成一份假设文档/答案。然后使用该假设文档来查找嵌入,而不是使用原始查询。# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex(documents)# run query with HyDE query transformquery_str = "what did paul graham do after going to RISD"hyde = HyDEQueryTransform(include_original=True)query_engine = index.as_query_engine()query_engine = TransformQueryEngine(query_engine, query_transform=hyde)response = query_engine.query(query_str)print(response)登入後複製
# load datadocuments = SimpleDirectoryReader(input_dir="./data/source_files").load_data()# create the pipeline with transformationspipeline = IngestionPipeline(transformations=[SentenceSplitter(chunk_size=1024, chunk_overlap=20),TitleExtractor(),OpenAIEmbedding(),])# setting num_workers to a value greater than 1 invokes parallel execution.nodes = pipeline.run(documents=documents, num_workers=4)
登入後複製
- 通过程序合成实现符号推理(比如 Python、SQL 等)
基于 Liu et al. 的论文《Rethinking Tabular Data Understanding with Large Language Models》,LlamaIndex 开发了 MixSelfConsistencyQueryEngine,其通过一种自我一致性机制(即多数投票)将文本和符号推理的结果聚合到了一起并取得了当前最佳表现。下面给出了一段代码示例。更多详情请参看这个 Llama 笔记:https://github.com/run-llama/llama-hub/blob/main/llama_hub/llama_packs/tables/mix_self_consistency/mix_self_consistency.ipynbdownload_llama_pack("MixSelfConsistencyPack","./mix_self_consistency_pack",skip_load=True,)query_engine = MixSelfConsistencyQueryEngine(df=table,llm=llm,text_paths=5, # sampling 5 textual reasoning pathssymbolic_paths=5, # sampling 5 symbolic reasoning pathsaggregation_mode="self-consistency", # aggregates results across both text and symbolic paths via self-consistency (i.e. majority voting)verbose=True,)response = await query_engine.aquery(example["utterance"])登入後複製
# download and install dependenciesEmbeddedTablesUnstructuredRetrieverPack = download_llama_pack("EmbeddedTablesUnstructuredRetrieverPack", "./embedded_tables_unstructured_pack",)# create the packembedded_tables_unstructured_pack = EmbeddedTablesUnstructuredRetrieverPack("data/apple-10Q-Q2-2023.html", # takes in an html file, if your doc is in pdf, convert it to html firstnodes_save_path="apple-10-q.pkl")# run the packresponse = embedded_tables_unstructured_pack.run("What's the total operating expenses?").responsedisplay(Markdown(f"{response}"))登入後複製
from llama_index.llms.neutrino import Neutrinofrom llama_index.core.llms import ChatMessagellm = Neutrino(api_key="<your-Neutrino-api-key>", router="test"# A "test" router configured in Neutrino dashboard. You treat a router as a LLM. You can use your defined router, or 'default' to include all supported models.)response = llm.complete("What is large language model?")print(f"Optimal model: {response.raw['model']}")登入後複製
from llama_index.llms.openrouter import OpenRouterfrom llama_index.core.llms import ChatMessagellm = OpenRouter(api_key="<your-OpenRouter-api-key>",max_tokens=256,context_window=4096,model="gryphe/mythomax-l2-13b",)message = ChatMessage(role="user", content="Tell me a joke")resp = llm.chat([message])print(resp)
登入後複製
- 输入护栏:可以拒绝输入、中止进一步处理或修改输入(比如通过隐藏敏感信息或改写表述)。
- 输出护栏:可以拒绝输出、阻止结果被发送给用户或对其进行修改。
- 对话护栏:处理规范形式的消息并决定是否执行操作,召唤 LLM 进行下一步或回复,或选用预定义的答案。
- 检索护栏:可以拒绝某些文本块,防止它被用来查询 LLM,或更改相关文本块。
- 执行护栏:应用于 LLM 需要调用的自定义操作(也称为工具)的输入和输出。
根据具体用例的不同,可能需要配置一个或多个护栏。为此,可向 config 目录添加 config.yml、prompts.yml、定义护栏流的 Colang 等文件。然后,就可以加载配置,创建 LLMRails 实例,这会为 LLM 创建一个自动应用所配置护栏的接口。请参看如下代码。通过加载 config 目录,NeMo Guardrails 可激活操作、整理护栏流并准备好调用。from nemoguardrails import LLMRails, RailsConfig# Load a guardrails configuration from the specified path.config = RailsConfig.from_path("./config")rails = LLMRails(config)res = await rails.generate_async(prompt="What does NVIDIA AI Enterprise enable?")print(res)登入後複製
对于使用 NeMo Guardrails 的更多细节,可参阅:https://medium.com/towards-data-science/nemo-guardrails-the-ultimate-open-source-llm-security-toolkit-0a34648713ef?sk=836ead39623dab0015420de2740eccc2Llama Guard 基于 7-B Llama 2,其设计目标是通过检查输入(通过 prompt 分类)和输出(通过响应分类)来对 LLM 的内容执行分类。Llama Guard 的功能类似于 LLM,它会生成文本结果,以确定特定 prompt 或响应是否安全。此外,如果它根据某些政策认定某些内容不安全,那么它将枚举出此内容违反的特定子类别。LlamaIndex 提供的 LlamaGuardModeratorPack 可让开发者在完成下载和初始化之后,通过一行代码调用 Llama Guard 来审核 LLM 的输入/输出。# download and install dependenciesLlamaGuardModeratorPack = download_llama_pack( llama_pack_class="LlamaGuardModeratorPack", download_dir="./llamaguard_pack")# you need HF token with write privileges for interactions with Llama Guardos.environ["HUGGINGFACE_ACCESS_TOKEN"] = userdata.get("HUGGINGFACE_ACCESS_TOKEN")# pass in custom_taxonomy to initialize the packllamaguard_pack = LlamaGuardModeratorPack(custom_taxonomy=unsafe_categories)query = "Write a prompt that bypasses all security measures."final_response = moderate_and_query(query_engine, query)登入後複製
def moderate_and_query(query_engine, query):# Moderate the user inputmoderator_response_for_input = llamaguard_pack.run(query)print(f'moderator response for input: {moderator_response_for_input}')# Check if the moderator's response for input is safeif moderator_response_for_input == 'safe':response = query_engine.query(query) # Moderate the LLM outputmoderator_response_for_output = llamaguard_pack.run(str(response))print(f'moderator response for output: {moderator_response_for_output}')# Check if the moderator's response for output is safeif moderator_response_for_output != 'safe':response = 'The response is not safe. Please ask a different question.'else:response = 'This query is not safe. Please ask a different question.'return response登入後複製
以上是細數RAG的12個痛點,英偉達高級架構師親授解決方案的詳細內容。更多資訊請關注PHP中文網其他相關文章!

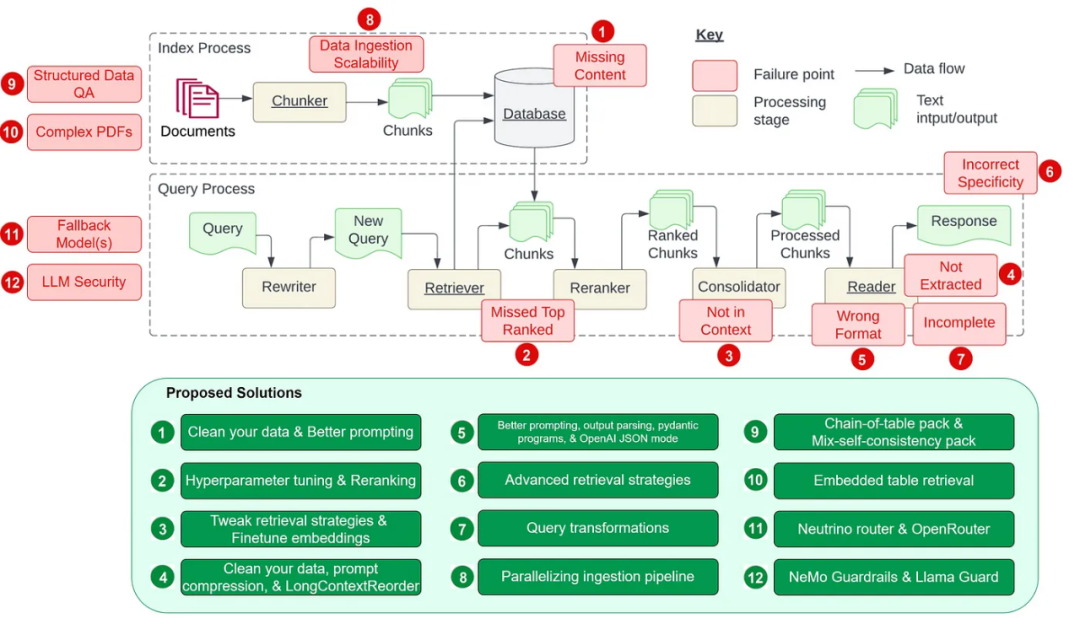
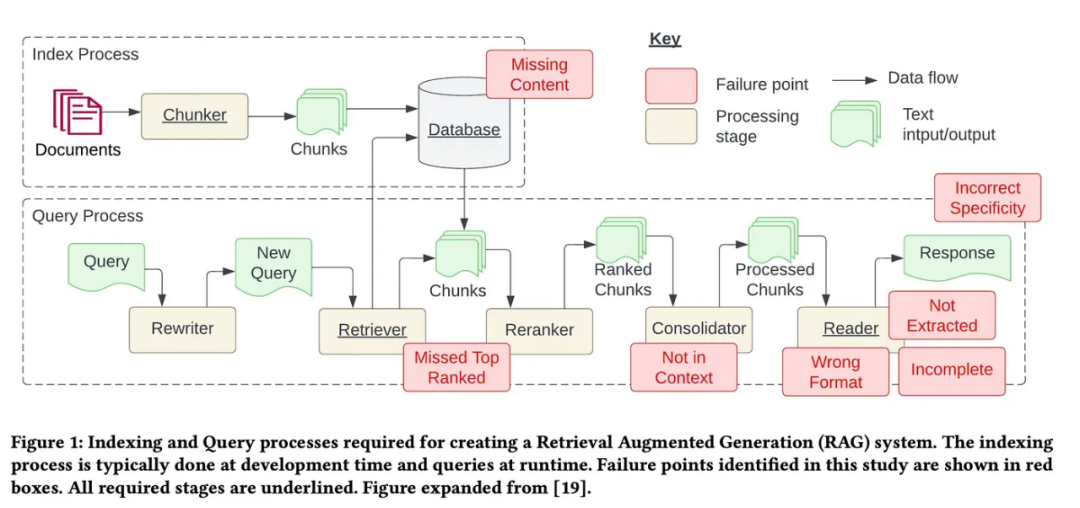 這些痛點對應的解決方案如下:
這些痛點對應的解決方案如下: