

AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者潘亮博士目前是上海人工智慧實驗室的Research Scientist。此前,在2020年至2023年,他於新加坡南洋理工大學S-Lab擔任Research Fellow,指導老師為劉子緯教授。他的研究重點是電腦視覺、3D點雲和虛擬人類,並在頂級會議和期刊上發表了多篇論文,谷歌學術引用超過2700次。此外,他還多次擔任電腦視覺和機器學習等領域頂尖會議和期刊的審稿人。
近期,商湯科技- 南洋理工大學聯合AI 研究中心S-Lab ,上海人工智慧實驗室,北京大學與密西根大學聯合提出DreamGaussian4D(DG4D),透過結合空間變換的明確建模與靜態3D Gaussian Splatting(GS)技術實現高效四維內容生成。
四維內容生成近來取得了顯著進展,但是現有方法存在優化時間長、運動控制能力差、細節品質低等問題。 DG4D 提出了一個包含兩個主要模組的整體框架:1)圖像到4D GS - 我們首先使用DreamGaussianHD 生成靜態3D GS,接著基於HexPlane 生成基於高斯形變的動態生成;2)視頻到視頻紋理細化- 我們細化產生的UV 空間紋理映射,並透過使用預先訓練的影像到視訊擴散模型來增強其時間一致性。
值得注意的是,DG4D 將四維內容生成的優化時間從幾小時縮短到幾分鐘(如圖1 所示),允許視覺上控制生成的三維運動,並支持生成可以在三維引擎中真實渲染的動畫網格模型。

論文名稱: DreamGaussian4D: Generative 4D Gaussian Splatting
主頁地址arxiv.org/abs/2312.17142
Demo 地址: https://huggingface.co/spaces/jiawei011/dreamgaussian 圖1. DG4D 在四分半鐘內達到四維度內容優化基本收斂
生成模型可以大大簡化多樣化數位內容(如二維影像、影片和三維景物)的生產和製作,近年來取得了顯著進步。四維內容是諸如遊戲、影視等諸多下游任務的重要內容形式。四維生成內容也應支援導入傳統圖形學渲染引擎軟體(例如,Blender 或 Unreal Engine),以連接現有圖形學內容生產管線(見圖 2)。 
主流的四維內容生成方法都基於四維動態神經輻射場(4D NeRF)表示。例如,MAV3D [1] 透過在 HexPlane [2] 上提煉文字到影片的擴散模型,實現了文字到四維內容的生成。 Consistent4D [3] 引入了一個視訊到四維的框架,以優化級聯的 DyNeRF,從靜態捕獲的影片中產生四維景物。透過多重擴散模型的先驗,Animate124 [4] 能夠透過文字運動描述將單一未處理的二維影像動畫化為三維的動態影片。基於混合 SDS [5] 技術,4D-fy [6] 使用多個預訓練擴散模型可實現引人入勝的文本到四維內容的生成。 然而,所有上述現有方法 [1,3,4,6] 產生單一 4D NeRF 都需要數個小時,這極大地限制了它們的應用潛力。此外,它們都難以有效控製或選擇最後生成的運動。以上不足主要來自以下幾個因素:首先,前述方法的底層隱式四維表示不夠高效,存在渲染速度慢和運動規律性差的問題;其次,視頻SDS 的隨機性質增加了收斂難度,並在最終結果中引入了不穩定性和多種瑕疵偽影現象。 方法介紹 與直接優化 4D NeRF 的方法不同,DG4D 透過結合靜態高斯潑濺技術和顯式的空間變換建模,為四維內容生成構建了一個高效和強力的表徵。此外,視訊生成方法有潛力提供有價值的時空先驗,增強高品質的 4D 生成。具體而言,我們提出了一個包含兩個主要階段的整體框架:1)影像到 4D GS 的生成;2)基於視訊大模型的紋理圖細化。 1. 影像到4D GS 的產生 在這一階段中,我們使用靜態3D GS 及其空間變形來表示動態的四維景物。基於一張給定的二維圖片,我們使用增強方法 DreamGaussianHD 方法產生靜態 3D GS。隨後,透過在靜態 3D GS 函數上優化時間依賴的變形場,估計各個時間戳處的高斯變形,旨在讓變形後的每一幀的形狀和紋理都與驅動視頻裡面的對應幀盡力保持吻合。這一階段結束,將可產生一段動態的三維網格模型序列。 1 Gaussian Deformation 基於生成的靜態3D GS 模型,我們透過預測每一幀中高斯核的變形來產生符合期望視頻的動態4D GS 模型。在動態效果的表徵上,我們選用 HexPlane(如圖 5 所示)來預測每一個時間戳下高斯核位移、旋轉和比例尺度,從而驅動產生每一幀的動態模型。此外,我們也針對性地調整設計網絡,特別是對最後幾個線性操作的網絡層做了殘差連接和零初始化的設計,從而可以平滑充分地基於靜態3D GS 模型初始化動態場(效果如圖6 所示)。 2. 視訊到影片的紋理最佳化 框架圖
類似於 DreamGaussian,在第一階段基於 4D GS 的四維動態模型生成結束後,可以提取四維的網格模型序列。而且,我們也可以類似 DreamGaussian 的做法,在網格模型的 UV 空間中對紋理做進一步的最佳化。有別於 DreamGaussian 只對單獨的三維網格模型使用圖片產生模型做紋理的最佳化,我們需要對整個三維網格序列做最佳化。 並且,我們發現如果沿用DreamGaussian 的做法,即對每個三維網格序列做獨立的紋理優化,會導致三維網格的紋理在不同的時間戳下有不一致的生成,並且常常會有閃爍等瑕疵偽影效果出現。有鑑於此,我們有別於 DreamGaussian,提出了基於視訊生成大模型的視訊到視訊的 UV 空間下紋理優化方法。具體而言,我們在優化過程中隨機生成了一系列相機軌跡,並基於此渲染出多個視頻,並對渲染出的視頻做相應的加噪和去噪處理,從而實現對生成網格模型序列的紋理增強。 基於圖片生成大模型和基於視頻生成大模型做的紋理優化效果對比展示在圖 8 中。 圖8 基於視訊到視訊的紋理最佳化可以實現時序上紋理的穩定性和一致性 實驗結果 相比之前整體最佳化4D NeRF 的方法,DG4D 顯著減少了四維內容生成所需的時間。具體的用時對比可見表 1。 用中對維我們跟隨先前方法的比較方式,將產生的四維內容與給定圖片的一致程度報告在表2 中。 對於基於影片產生四維內容的設置,影片產生四維內容方法的數值結果比較可見表 3。 對 SoTA 的圖產生四維內容方法和影片產生四維內容方法的效果比較圖,分別展示在圖9和圖10 中。
圖 10 視訊中建立四維內容效果圖
此外,我們還基於近期的直接前饋實現單圖生成 3D GS 的方法(即非使用 SDS 優化方法),做了靜態三維內容的生成,並基於此初始化了動態 4D GS 的生成。直接前饋生成 3D GS,可以比基於 SDS 優化的方法,更快得到品質更高,也更多樣化的三維內容。基於此得到的四維內容,展示在圖 11 中。 的四維內容展示在圖 12 中。 結語 基於 4D GS,我們提出了 DreamGaussian4D(DG4D),這是一個高效的圖像到 4D 生成框架。相較於現存的四維內容生成框架,DG4D 顯著將優化時間從幾小時縮短到幾分鐘。此外,我們展示了使用生成的影片進行驅動運動生成,實現了視覺可控的三維運動生成。 最後,DG4D 允許進行三維網格模型提取,並支持實現時序上保持連貫一致的高品質紋理最佳化。我們希望 DG4D 提出的四維內容生成框架,將促進四維內容生成方向的研究工作,並有助於多樣化的實際應用。 [1] Singer et al. "Text-to-4D dynamic scene generation." Proceedings of the 40008. [ 2] Cao et al. "Hexplane: A fast representation for dynamic scenes." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. . 360° Dynamic Object Generation from Monocular Video." The Twelfth International Conference on Learning Representations. 2023. [4] Zhao et al. "Animate124: 4157 月 15 月 124:202124: 102124: 102124: 102124: 12124: 12124: 12124: 12124: 202124 212124:202124:202124: 12124: 202124) 125) 4603 (2023). [5] Poole et al. "DreamFusion: Text-to-3D using 2D Diffusion." The Eleventh International Conference on Learning Represcomations. 2022. , Sherwin, et al. "4d-fy: Text-to-4d generation using hybrid score distillation sampling." arXiv preprint arXiv:2311.17984 (2023).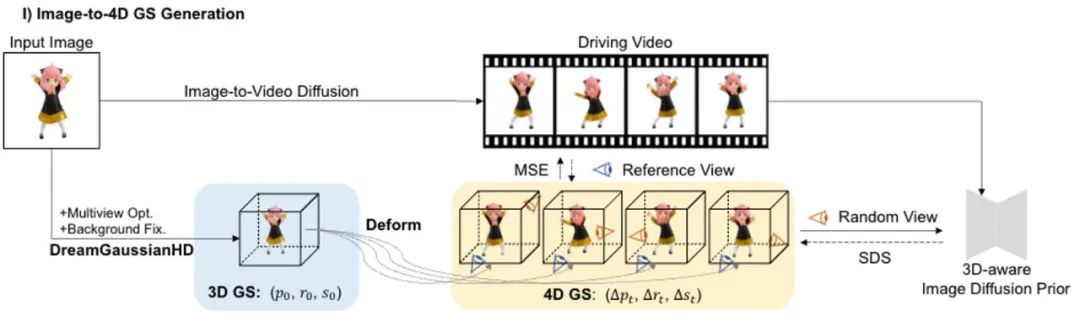

基於近來使用3D GS 的圖生三維物體方法DreamGaussian [7],我們做了一些進一步的改進,整理出一套效果更佳的3D GS 生成與初始化方法。主要改進的操作包括有 1)採取多視角的最佳化方式;2)設定最佳化過程中的渲染圖片背景為更適合生成的黑色背景。我們稱呼改良後的版本為 DreamGaussianHD,具體的改良效果圖可見圖 4。


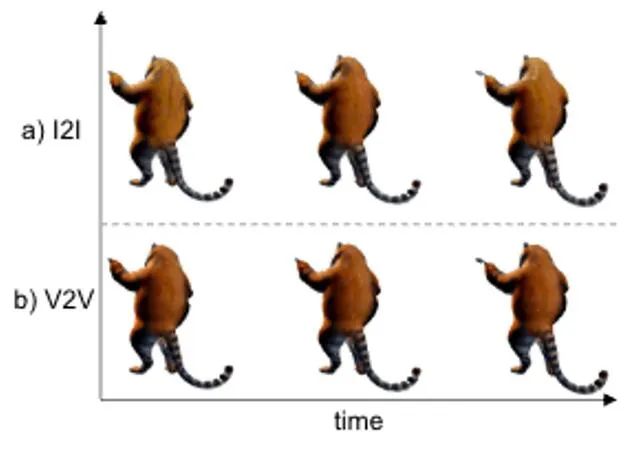
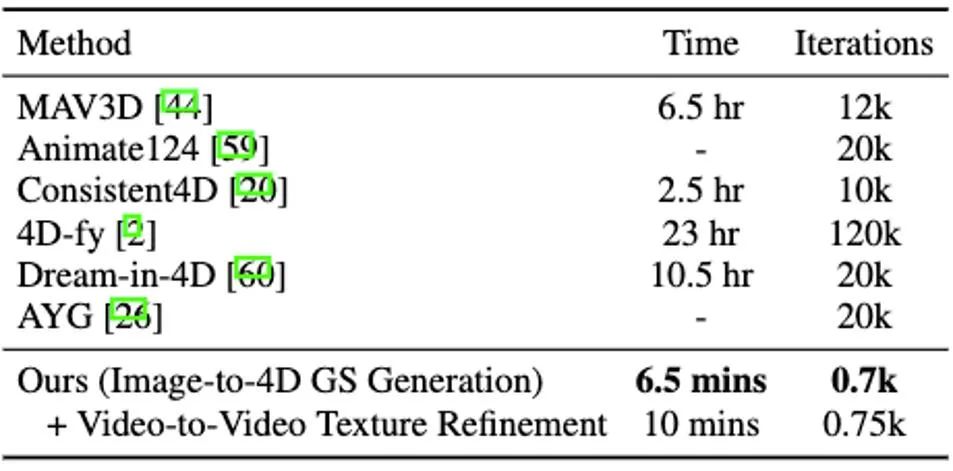
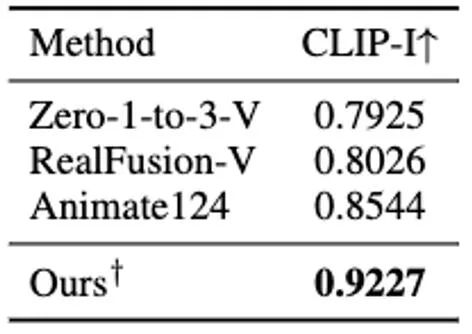 表 2 基於單圖產生的四維內容與圖片的一致性比較
表 2 基於單圖產生的四維內容與圖片的一致性比較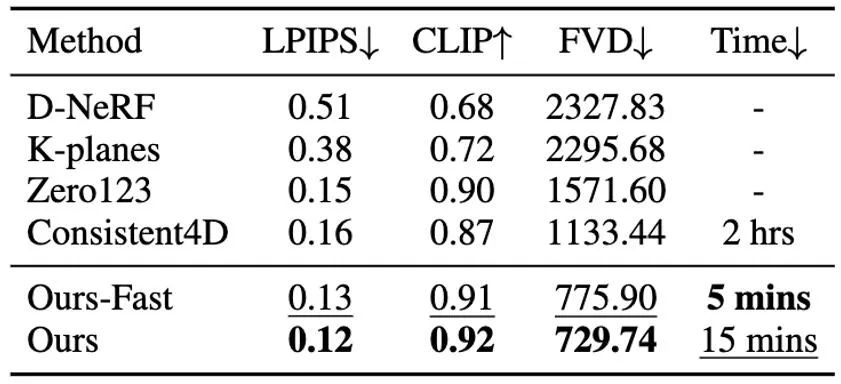 此外 我們也對最符合我們方法的單圖產生四維內容的各個方法的生成結果做了用戶採樣測試,測試的結果報告在表4 中。
此外 我們也對最符合我們方法的單圖產生四維內容的各個方法的生成結果做了用戶採樣測試,測試的結果報告在表4 中。 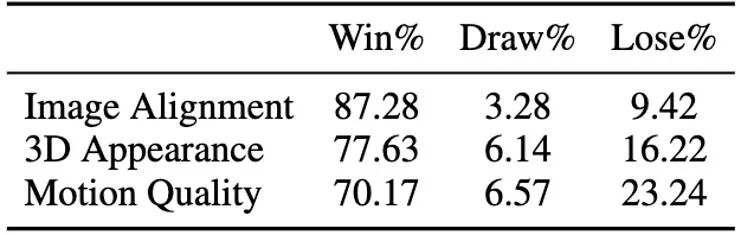



以上是幾分鐘產生四維內容,還能控制運動效果:北大、密西根提出DG4D的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















