
不管你來自哪個城市,相信在你的記憶中,都有自己的「家鄉話」:吳語柔軟細膩、關中方言質樸厚重、四川方言幽默詼諧、粵語古雅瀟灑……
某種意義上說,方言不只是一種語言習慣,也是一種情感連結、一種文化認同。我們「上網衝浪」遇到的新鮮詞彙中,有不少就是來自各地方言。
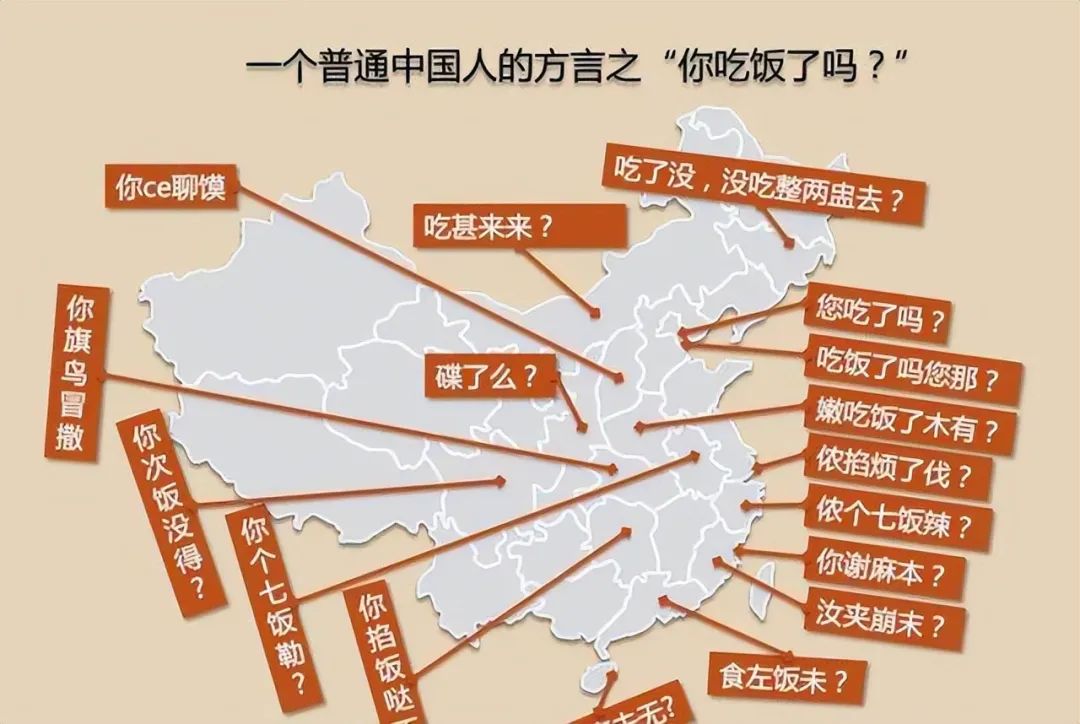
當然,有些時候,方言也是一種溝通「壁壘」。
在現實生活中,我們經常會看到方言導致的“雞同鴨講”,比如這個: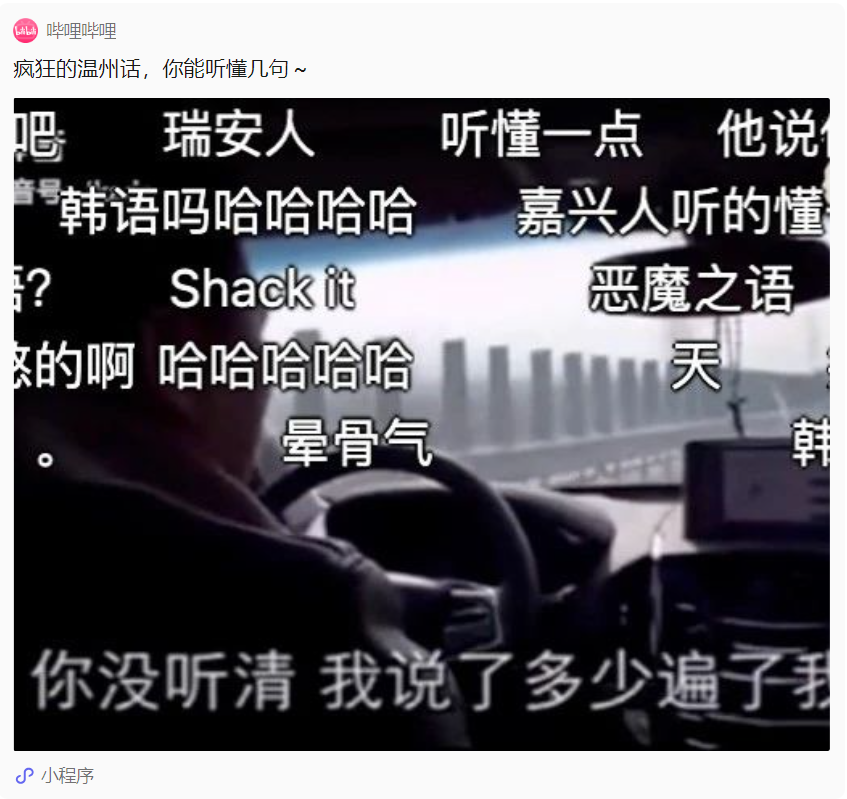
如果你關注最近科技圈的動態就會知道,當前的AI 語音助手已經能達到「即時回覆」的水準,甚至比人類反應還快。而且,AI 已經能夠充分理解人類的情感,自己也能表現出各種感情。
在這樣的基礎上,如果語音助理能夠辨識並理解每一種方言,就能徹底擊破溝通壁壘,與任何群體無障礙進行語言溝通。
實際上,這件事已經有人做了:近日,中國電信人工智慧研究院(TeleAI)發布了業內首個支援30 種方言自由混說的「星辰超多方言語音識別大模型」,可同時辨識理解粵語、上海話、四川話、溫州話等各地方言,是國內支持最多方言的語音辨識大模型。
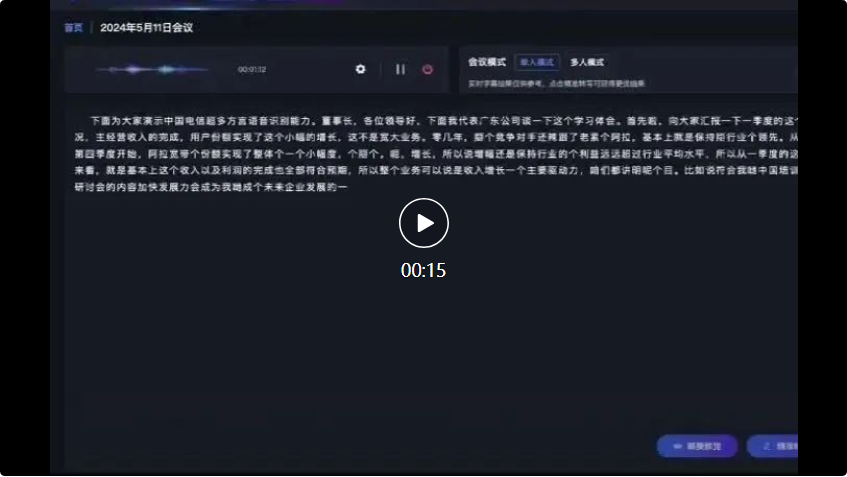
例如在以下這個會議場景中,面對多種方言的輸入,星辰超多方言語音辨識大模型的辨識準確率達到業界領先。
首先是來自廣東公司的代表,使用了粵語發言: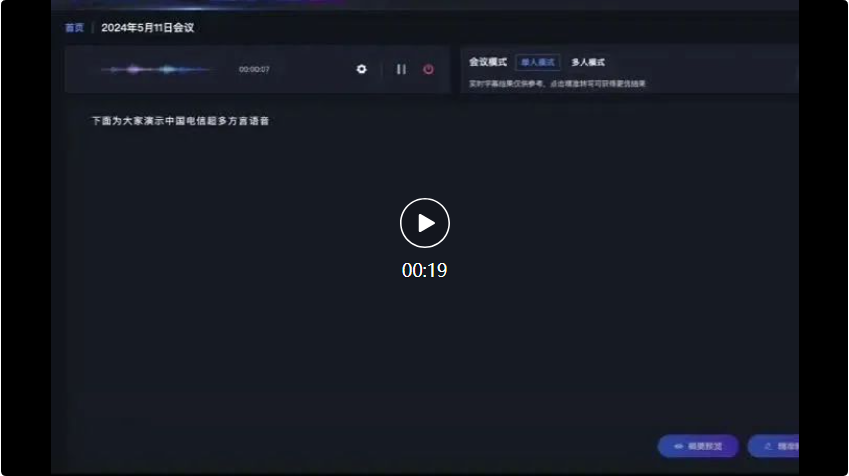
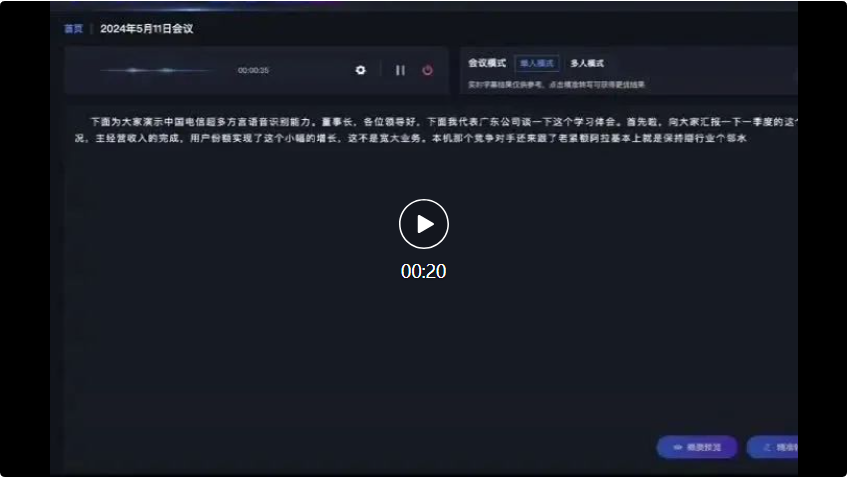 而在接下來的四川方言和山西方言的對話中,星辰超多方言語音辨識大模型也能準確辨識並轉換為文字記錄:
而在接下來的四川方言和山西方言的對話中,星辰超多方言語音辨識大模型也能準確辨識並轉換為文字記錄: 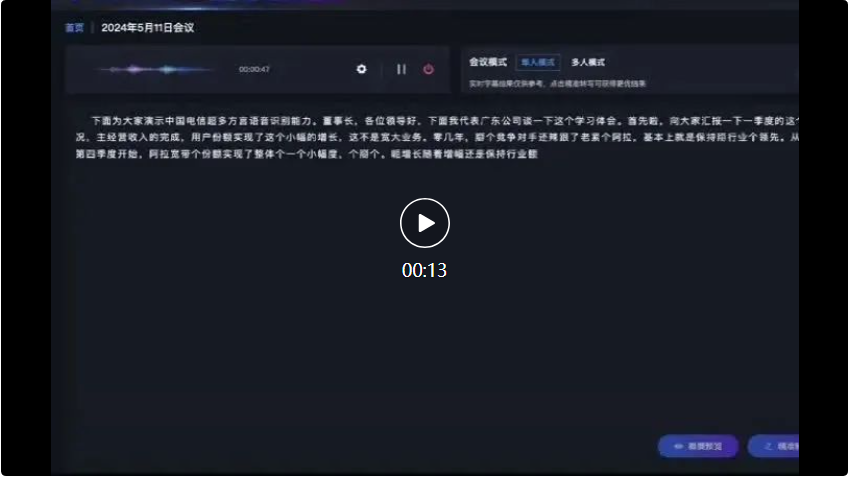
與語音助理對話過的人都知道,針對普通話的語音辨識準確率是相當不錯的,但當面對重口音或方言的時候,辨識準確度會大幅下降,甚至「張冠李戴」。
為了解決這個問題,傳統語音辨識模型的處理方式是針對每種方言單獨訓練一個方言模型,這導致了同一個應用背後需要維護多個方言模型,且無法透過一個模型識別多種方言。然而後者恰恰是現實落地場景中最需要的。
一直以來深耕語音賽道的中國電信,決定挑戰這個命題:打造一個更「通用」的語音辨識大模型。
30 多種方言,大模型如何拿下?
讓大模型一口氣學會 30 幾種方言,並沒有想像中的簡單 —— 挑戰同樣存在於數據、演算法、算力方面。
一方面,因為方言資料量的稀疏,不利用其他方言資料中的共有資訊而單獨訓練某個方言模型,效果往往不盡人意。
經過在語音領域多年的積累,TeleAI 已經構建了超 30 種、超 30 萬小時的高質量方言數據庫,方言數據庫在豐富性和高質量等層面均居於業內前列。高品質語音資料對研究者而言是一大利好,能夠讓模型更有效率、有系統地對方言進行整理歸納。更長遠地看,建構高品質方言資料庫,也是方言保護和研究的基礎。
另一方面的挑戰來自於語音辨識技術。如何讓使用者與大模型對話就像和家人講話一樣自然,無需刻意切換普通話,無需提高音量、放慢語速,是工業界當前追求的新目標。
在中國電信 CTO、人工智慧研究院院長李學龍帶領下,TeleAI 自主研發了星辰語音辨識大模型。團隊首創「蒸餾 + 膨脹」聯合訓練演算法,解決了超大規模多場景資料集和大規模參數條件下預訓練坍縮的問題,實現 80 層模型穩定訓練。同時,透過超大規模語音預訓練和多方言聯合建模,實現了單一模型支援 30 種方言自由混說語音辨識。

星辰語音識別大模型也是業內首個開源的基於離散語音表徵的語音識別大模型,透過「從語音到token 再到文本」的建模新範式,將推理時語音傳輸比特率降低了數十倍。
憑藉著絕對領先的性能,星辰語音識別大模型此前已經在國際上斬獲了多個國際權威賽事冠軍。
例如,在權威國際語音頂會Interspeech 2024 離散語音單元建模挑戰賽的ASR 賽道(Automatic Speech Recognition,自動語音辨識)中,星辰語音辨識大模型團隊領先約翰霍普金斯大學、卡內基美隆大學、英偉達等國內外知名大學與企業,一舉拿下賽道冠軍。
團隊在這場比賽中提出的系統方案極具特色:在訓練時採用了「三段式」設計,包括前端預訓練模型表徵調整策略(Frontend Model)、表徵提取與離散化過程(Dsicrete Token Process)以及多語種辨識模型訓練過程(Discrete ASR Model),而在推理階段僅使用後兩段過程。
其中的表徵離散化方法,可以讓模型在保留語音中任務相關信息的同時,去除其餘不相關信息,達到降低語音推理傳輸比特率、減少內存使用、提升訓練效率的目的,同時也為語音多任務(如ASR、TTS、說話者辨識等)統一模型建構、多模態模型建模、說話者隱私保護等方向提供了可能的解決方案。
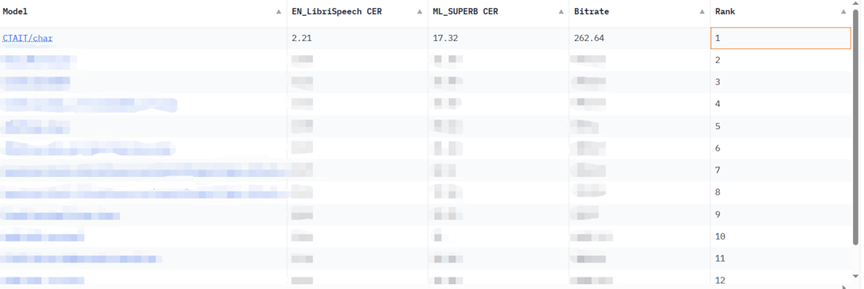
在業界知名的多方言語音辨識資料集 KeSpeech 任務上,星辰語音辨識大模型以領先先前最優結果 20% 的成績打破紀錄,實現了 92.97% 的字準確率。在 NIST(美國國家標準與技術研究院)舉辦的低資源粵語電話 Babel 語音辨識任務上,星辰語音辨識大模型也取得了業界最優結果。
在常見的算力挑戰方面,星辰語音辨識大模型的研發團隊也同樣具備優勢。中國電信是國內最早進入雲端運算領域的營運商,累積了大量算力建置與算力調度的核心技術。此外,中國電信陸續投產了京津冀智算中心、中南智算中心等多個滿足大模型訓練的公共智算中心。
基於這些優勢條件,星辰超多方言語音辨識大模型橫空出世,打破了單一模型只能辨識特定單一方言的困境。在多項基準測試中,星辰超多方言語音辨識大模型展現了極為優異的能力:
智能座艙場景為例,擅長各種方言的星辰超多方言語音識別大模型能夠使系統更準確地識別和轉錄各種方言的語音輸入,帶來更自然流暢的互動體驗,特別是在方言使用較為普遍的地區,減少「雞同鴨講」的誤會。
從情感陪伴的角度看,大模型對方言的理解和精通,能夠極大提升對話機器人類產品的陪伴質量,有效解決普通話不熟練的老年人等群體無法觸達信息服務的問題。如同科幻電影《Her》中的情節,AI 能夠給予人類超越真實世界中人際關係的高品質關懷。 
現在、Xingchen の大規模な複数方言音声認識モデルはさまざまな業界に統合され始めており、新たなアプリケーション シナリオを積極的に模索しています。たとえば、興チェンの大規模な複数方言音声認識モデルは、興チェンの大規模な複数方言にアクセスした後、福建省、江西省、広西チワン族自治区、北京、内モンゴルなどのチャイナテレコムの万豪インテリジェント顧客サービスシステムで試験運用されています。音声認識モデル、Wanhao インテリジェント カスタマー サービスは 30 の方言を数秒で理解し、1 日あたり平均約 200 万件の通話を処理します; インテリジェント カスタマー サービス Yisheng プラットフォームは、Xingchen の超多方言音声の音声理解および分析機能に接続されています。認識モデルにより、31 州を完全にカバーし、毎日 125 万件のカスタマー サービス コールに対応できます。
チャイナテレコムにとって、もう一つの非常に重要な出発点があります。それは、2023 年以前には、人々が大型モデルのテクノロジーについて語るとき、公共の福祉の価値について言及されることはほとんどなくなるということです。しかし 2024 年には、この価値がますます「認識」されるようになります。
大型モデル技術の応用は、方言文化の保護を大きく促進します。我が国の 130 以上の言語のうち、話者が 10,000 人未満の言語が 68 言語、話者が 5,000 人未満の言語が 48 言語、話者が 1,000 人未満の言語が 25 言語あり、話者が十数人または数人しかいない言語もあります。話せる。大規模な音声モデルの参加は、絶滅の危機に瀕している方言を記録して保護し、方言の継承と学習を促進するのに役立ちます。大量の方言コンテンツを含む歴史文書やアーカイブの場合、方言大規模モデルは、文化遺産の損失を防ぐためのデジタル化と整理作業にも役立ちます。
「音声アシスタント」が全開
チャイナテレコムは大型モデル導入の戦いをどうリードできるのか?
大規模モデルを巡る戦いは 1 年半にわたって続いています。現在、業界ではコンセンサスが得られています。大規模モデルの推論のコストが大幅に低下するため、大規模モデルのアプリケーションはパンク期を迎えるでしょう。
国内外の多くの大型モデルプレーヤーの中で、チャイナテレコムは非常に特別な企業です。この新たな段階では、私たちがよく知っているテクノロジー企業と比較して、チャイナテレコムのような通信事業者はリソースとビジネスの面でより多くの利点を持っています。
一方で、オペレーターは豊富なネットワークとコンピューティングリソースを持っているため、トレーニングと推論のコストが比較的低くなります。特に大規模なモデルの構築では、スケールを活用しやすくなります。一方、チャイナテレコムは大規模な顧客ベースと豊富な2C、2H、2B情報サービス事業を有しており、さまざまな分野で大規模な人工知能モデルの実装を迅速に推進し、新たな経済成長ポイントを形成することができます。これらの利点は、通信事業者に人工知能分野への投資を増やし、技術の進歩を促進するインセンティブを与えます。
国内通信事業者の中で、チャイナテレコムはAI分野に初めて導入し、技術革新とコア機能の独立した研究開発の開発路線を堅持しています。昨年以来、Xingchen セマンティック大型モデルから Xingchen マルチモーダル大型モデル、Xingchen 音声認識大型モデルに至るまで、チャイナ テレコムの大規模モデルは常に迅速な反復を維持し、セマンティクス、音声、ビジョン、マルチモダリティの完全なモデルを完成させてきました。ダイナミックな大型モデルのレイアウト。

 このような多用途な中国語音声アシスタントを楽しみにしていますか?
このような多用途な中国語音声アシスタントを楽しみにしていますか?
以上是換了30多種方言,我們竟然沒能考倒中國電信的語音大模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















