
想像一下,如果機器人能夠聽懂你的需求,並且努力滿足,是不是很美好呢?
如果想讓機器人幫助你,你通常需要下達一個較為精準的指令,但指令在實際中的實現效果不一定理想。如果考慮真實環境,當要求機器人找某個特定的物品時,這個物品不一定真的存在當前的環境內,機器人無論如何也找不到;但是環境當中是不是可能存在一個其他物品,它和用戶要求的物品有類似的功能,也能滿足使用者的需求呢?這就是用 「需求」 作為任務指令的好處了。
近日,北京大學董豪團隊提出了一個新的導航任務 —— 需求驅動導航(Demand-driven Navigation,DDN),目前已被 NeurIPS 2023 接收。在這個任務當中,機器人被要求根據一個使用者給定的需求指令,尋找能夠滿足使用者需求的物品。同時,董豪團隊也提出了學習基於需求指令的物品屬性特徵,有效提高了機器人尋找物品的成功率。

論文地址:https://arxiv.org/pdf/2309.08138.pdf
專案首頁:https://sites.google.com/view/demand-driven-navw* 
將需求作為指令,意味著機器人需要對指令的內容進行推理和探索當前場景中的物品種類,然後才能找到滿足使用者需求的物品。從這一點上來說,需求驅動導航要比視覺物品導航困難得多。雖說難度增加了,但是一旦機器人學會了根據需求指示尋找物品,好處還是很多的。例如:
 用戶只需要根據自己的需求提出指令,而不用考慮場景內有什麼。
用戶只需要根據自己的需求提出指令,而不用考慮場景內有什麼。
考慮到能滿足同一個需求的物品之間有相似的屬性,如果能學到這種物品屬性上的特徵,機器人似乎就能利用這些屬性特徵來尋找物品。例如,對於 「我渴了」 這個需求,所需的物品應該要有 「解渴」 這個屬性,而 「果汁」、「茶」 都具有這個屬性。這裡要注意的是,對於一個物品,在不同的需求下可能表現出不同的屬性,比如“水” 既能表現出“清潔衣物” 的屬性(在“洗衣服” 的需求下),也能表現出「解渴」 這屬性(在「我渴了」 的需求下)。
屬性學習階段
那麼,如何讓模型理解這種 「解渴」、「清潔衣物」 這些需求呢?注意到在某一需求下物品所表現出的屬性,是一種較為穩定的常識。而最近幾年,隨著大語言模型(LLM)逐漸興起,LLM 所表現出的對人類社會常識方面的理解讓人驚嘆。因此,北大董豪團隊決定向 LLM 學習這種常識。他們先讓 LLM 產生了許多需求指令(在圖中稱為 Language-grounding Demand,LGD),然後再詢問 LLM,這些需求指令能被哪些物品滿足(在圖中稱為 Language-grounding Object,LGO)。
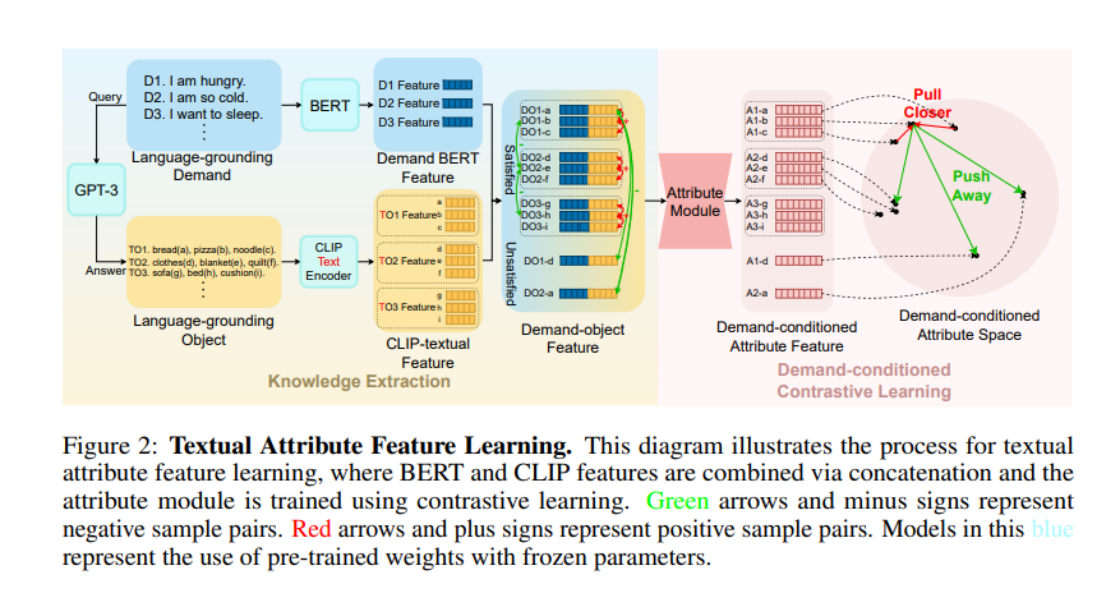
在這裡要說明,Language-grounding 這個前綴強調了這些demand/object 是可以從LLM 中獲取而不依賴於某個特定的場景;下圖中的World-grounding 強調了這些demand/ object 是與某個特定的環境(例如ProcThor、Replica 等場景資料集)緊密結合的。
接著為了取得 LGO 在 LGD 下所表現出的屬性,作者們使用了 BERT 編碼 LGD、CLIP-Text-Encoder 編碼 LGO,然後拼接得到 Demand-object Features。注意到在一開始介紹物品的屬性時,有一個 “相似性”,作者們就利用這種相似性,定義了 “正負樣本”,然後採用對比學習的方式訓練 “物品屬性”。具體來說,對於兩個拼接之後的Demand-object Features,如果這兩個特徵對應的物品能滿足同一個需求,那麼這兩個特徵就互為正樣本(比如圖中的物品a 和物品b 都能滿足需求D1,那麼DO1-a 和DO1-b 就互為正樣本);其他任何拼接均互為負樣本。作者們將 Demand-object Features 輸入到一個 TransformerEncoder 架構的 Attribute Module 之後,就採用 InfoNCE Loss 訓練了。
導航策略學習階段
透過對比學習,Attribute Module 中已經學到了LLM 提供的常識,在導航策略學習階段,Attribute Module 的參數被直接導入,然後採用模仿學習的方式學習由A* 演算法收集的軌跡。在某一個時間步,作者採用 DETR 模型,將目前視野中的物品分割出來,得到 World-grounding Object,然後由 CLIP-Visual-Endocer 編碼。其他的流程與屬性學習階段類似。最後將對需求指令的 BERT 特徵、全域圖片特性、屬性特性拼接,送入一個 Transformer 模型,最終輸出一個動作。

值得注意的是,作者們在屬性學習階段使用了 CLIP-Text-Encoder,而在導航策略學習階段,作者們使用了 CLIP-Visual-Encoder。這裡巧妙地借助於 CLIP 模型在視覺和文字上強大的對齊能力,將從 LLM 中學習到的文本常識轉移到了每一個時間步的視覺上。
實驗結果
實驗是在 AI2Thor simulator 和 ProcThor 數據集上進行,實驗結果表明,該方法顯著高於之前各種視覺物品導航演算法的變種、大語言模型加持下的演算法。

VTN 是一種閉詞彙集的物品導航演算法(closed-vocabulary navigation),只能在預先設定的物品上進行導航任務。作者們對它的演算法做了一些變種,然而不管是將需求指令的 BERT 特徵作為輸入、還是將 GPT 對指令的解析結果作為輸入,演算法的結果都不是很理想。當換成ZSON 這種開詞彙集的導航演算法(open-vocabulary navigation),由於CLIP 在需求指令和圖片之間的對齊效果並不好,導致了ZSON 的幾個變種也無法很好的完成需求驅動導航任務。而一些基於啟發式搜尋 + LLM 的演算法由於 Procthor 資料集場景面積較大,探索效率較低,其成功率並沒有很高。純粹的 LLM 演算法,例如 GPT-3-Prompt 和 MiniGPT-4 都表現出較差的對場景不可見位置的推理能力,導致無法有效地發現滿足要求的物品。
消融實驗顯示了 Attribute Module 顯著提高了導航成功率。作者們展示了 t-SNE 圖很好地表現出 Attribute Module 透過 demand-conditioned contrastive learning 成功地學習到了物品的屬性特徵。而 Attribute Module 架構換成 MLP 之後,效能出現了下降,說明 TransformerEncoder 架構更適合用來捕捉屬性特性。 BERT 很好地提取了需求指令的特徵,使得對 unseen instruction 泛化性得到了提升。

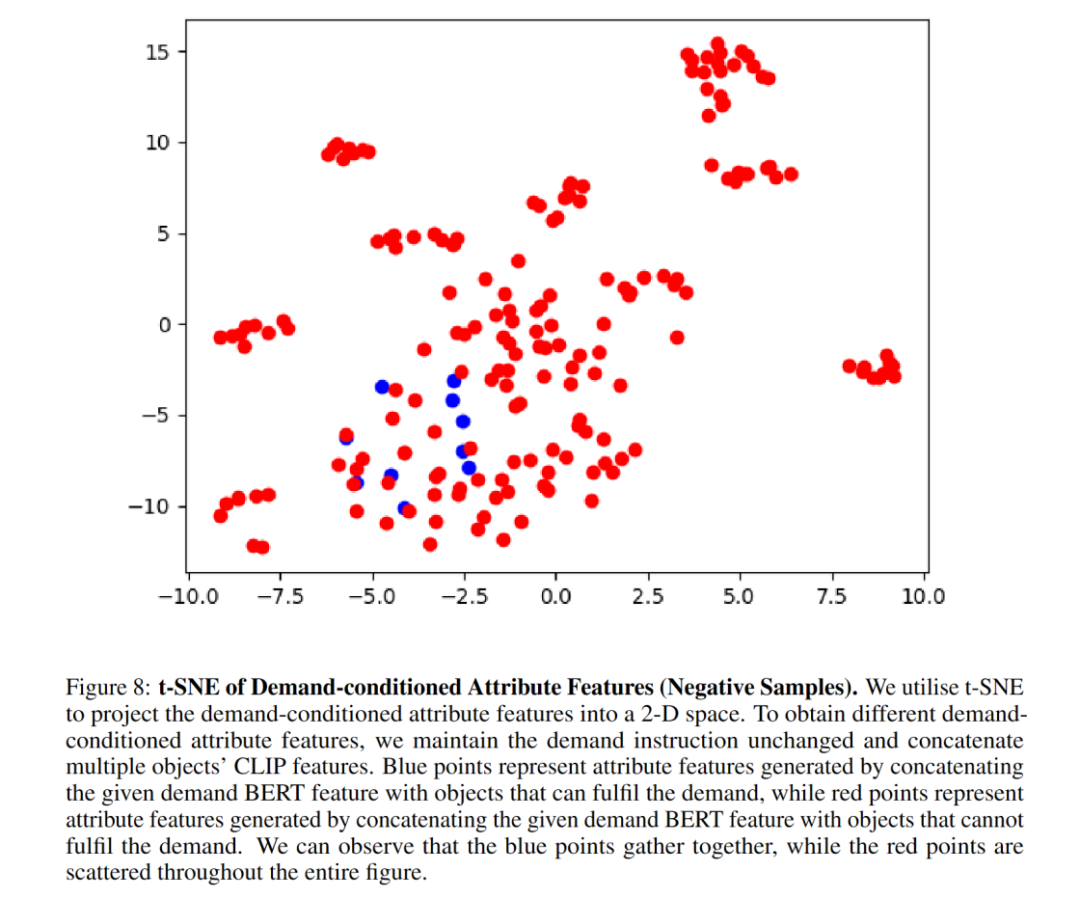
下面是一些視覺化:




 參考連結:
參考連結:
[1] https://zsdonghao.github.io/
以上是北大具身智慧團隊提出需求驅動導航,對齊人類需求,讓機器人更有效率的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















