
AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
近年來,多模態大型語言模型(MLLM)在各個領域的應用取得了顯著的成功。然而,作為許多下游任務的基礎模型,目前的 MLLM 由眾所周知的 Transformer 網路構成,這種網路具有較低效率的二次計算複雜度。為了提高這類基礎模型的效率,大量的實驗表明:(1)Cobra 與目前計算效率高的最先進方法(例如,LLaVA-Phi,TinyLLaVA 和MobileVLM v2)具有極具競爭力的性能,並且由於Cobra的線性序列建模,其速度更快。 (2)有趣的是,封閉集挑戰性預測基準的結果顯示,Cobra 在克服視覺錯覺和空間關係判斷方面表現良好。 (3)值得注意的是,Cobra 甚至在參數數量只有 LLaVA 的 43% 左右的情況下,也取得了與 LLaVA 相當的性能。 大語言模型(LLMs)受限於僅透過語言進行交互,限制了它們處理更多樣化任務的適應性。多模態理解對於增強模型有效應對現實世界挑戰的能力至關重要。因此,研究人員正在積極努力擴展大型語言模型,以納入多模態資訊處理能力。視覺 - 語言模型(VLMs)如 GPT-4、LLaMA-Adapter 和 LLaVA 已經被開發出來,以增強 LLMs 的視覺理解能力。 然而,先前的研究主要嘗試以類似的方法獲得高效的 VLMs,即在保持基於注意力的 Transformer 結構不變的情況下減少基礎語言模型的參數或視覺 token 的數量。本文提出了一個不同的視角:直接採用狀態空間模型(SSM)作為骨幹網絡,得到了一個線性計算複雜度的 MLLM。此外,本文也探討和研究了各種模態融合方案,以創建一個有效的多模態 Mamba。具體來說,本文採用 Mamba 語言模型作為 VLM 的基礎模型,它已經顯示出可以與 Transformer 語言模型競爭的效能,但推理效率更高。測試顯示 Cobra 的推理性能比同參數量級的 MobileVLM v2 3B 和 TinyLLaVA 3B 快 3 倍至 4 倍。即使與參數數量更多的 LLaVA v1.5 模型(7B 參數)相比,Cobra 仍然可以在參數數量約為其 43% 的情況下在幾個基準測試上實現可以匹配的性能。 
調查了現有的多模態大型語言模型(MLLMs)通常依賴Transformer 網絡,這表現出二次方的計算複雜度。為了解決這種低效率問題,本文引入了 Cobra,一個新穎的具有線性計算複雜度的 MLLM。 深入探討了各種模態融合方案,以優化 Mamba 語言模型中視覺和語言訊息的整合。透過實驗,本文探討了不同融合策略的有效性,確定了產生最有效多模態表示的方法。
-
進行了廣泛的實驗,評估 Cobra 與旨在提高基礎 MLLM 計算效率的平行研究的性能。值得注意的是,Cobra 甚至在參數較少的情況下實現了與 LLaVA 相當的性能,突顯了其效率。
-
- 原文連結:https://arxiv.org/pdf/2403.14520v2.pdf
- 專案連結:https://sites.Google.com/view/cobravlm/
- 計畫連結:https://sites.google.com/view/cobravlm/
Extending Mamba to Multi-Modal Large Language Model for Efficient Inference
方法介紹連接兩個模由態的投影機和LLM 語言主幹組成的VLM 結構。 LLM 主幹部分採用了 2.8B 參數預訓練的 Mamba 語言模型,該模型在 600B token 數量的 SlimPajama 資料集上進行了預訓練並經過了對話資料的指令微調。 圖Cobra 網路結構圖上與工作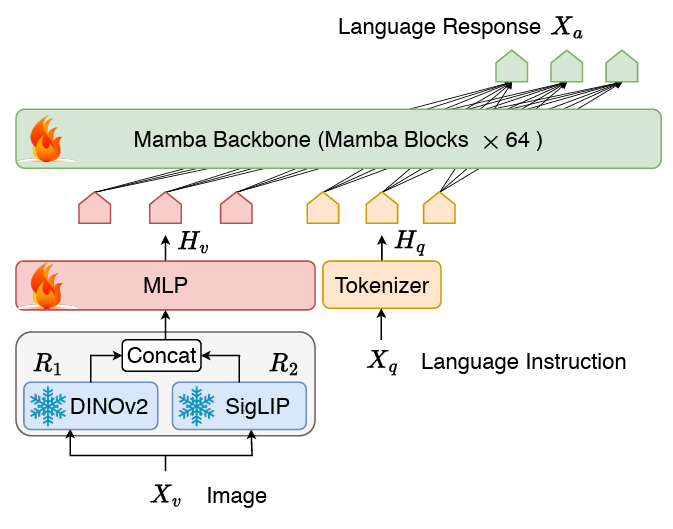 2 和SigLIP 融合的視覺表徵,透過將兩個視覺編碼器的輸出拼接在一起送入投影器,模型能夠更好的捕捉到SigLIP 帶來的高層次的語義特徵和DINOv2 提取的低層次的細粒度影像特徵。
2 和SigLIP 融合的視覺表徵,透過將兩個視覺編碼器的輸出拼接在一起送入投影器,模型能夠更好的捕捉到SigLIP 帶來的高層次的語義特徵和DINOv2 提取的低層次的細粒度影像特徵。
最近的研究表明,對於基於LLaVA 的現有訓練範式(即,只對準層的預對齊階段和LLM 骨幹的微調階段各一次骨幹階段可能是不必要的,而且微調後的模型仍處於欠擬合狀態。因此,Cobra 捨棄了預對齊階段,直接對整個 LLM 語言主幹和投影機進行微調。這個微調過程在一個組合資料集上隨機抽樣進行兩個週期,該資料集包括:在LLaVA v1.5 中使用的混合資料集,其中包含總計655K 視覺多輪對話,包括學術VQA 樣本,以及LLaVA-Instruct 中的視覺指令調校資料和ShareGPT 中的純文字指令調校資料。 LVIS-Instruct-4V,其中包含 220K 張帶有視覺對齊和上下文感知指令的圖片,這些指令由 GPT-4V 產生。 LRV-Instruct,這是一個包含 400K 視覺指令資料集,涵蓋了 16 個視覺語言任務,目的是減輕幻覺現象。
- 整個數據集大約包含 120 萬張圖片和相應的多輪對話數據,以及純文字對話數據。
實驗
定量實驗 實驗部分,本文提出了Cobra 樣源的基礎和基本對照模型,本文對開源實驗量級是基於Transformer 架構的VLM 模型的回答速度。 圖上產生速度與效能相比較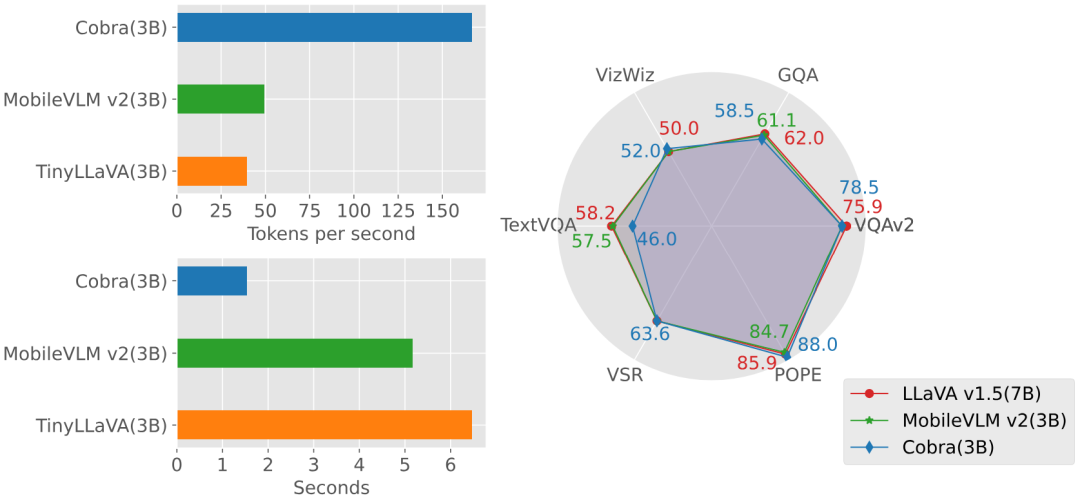 2,GQA,VizWiz,TextVQA 四個開放VQA 任務以及VSR,POPE 兩個閉集預測任務,共6 個benchmark 上進行了分數比較。
2,GQA,VizWiz,TextVQA 四個開放VQA 任務以及VSR,POPE 兩個閉集預測任務,共6 個benchmark 上進行了分數比較。
.  此外Cobra 也給出了兩個VQA 範例以定性說明Cobra 在物體的空間關係認知和減輕模型幻覺兩個能力上的優越性。
此外Cobra 也給出了兩個VQA 範例以定性說明Cobra 在物體的空間關係認知和減輕模型幻覺兩個能力上的優越性。
圖 Cobra 和其他基線收到則在兩個問題上都做出了精確的描述,尤其在第二個實例中,Cobra 準確的辨識出了圖片是來自於機器人的模擬環境。 消融實驗本文從性能和生成速度這兩個維度對 Cobra 採取的方案進行了消融研究。實驗方案分別對投影機、視覺編碼器、LLM 語言主幹進行了消融實驗。 時所採取的實驗性對比圖7557575% 所採取的實驗性測量的實驗性對比投影機在效果上顯著優於致力於減少視覺token 數量以提升運算速度的LDP 模組,同時,由於Cobra 處理序列的速度和運算複雜度均優於Transformer,在生成速度上LDP 模組並沒有明顯優勢,因此在Mamba 類模型中使用透過犧牲精度減少視覺token 數量的採樣器可能是不必要的。 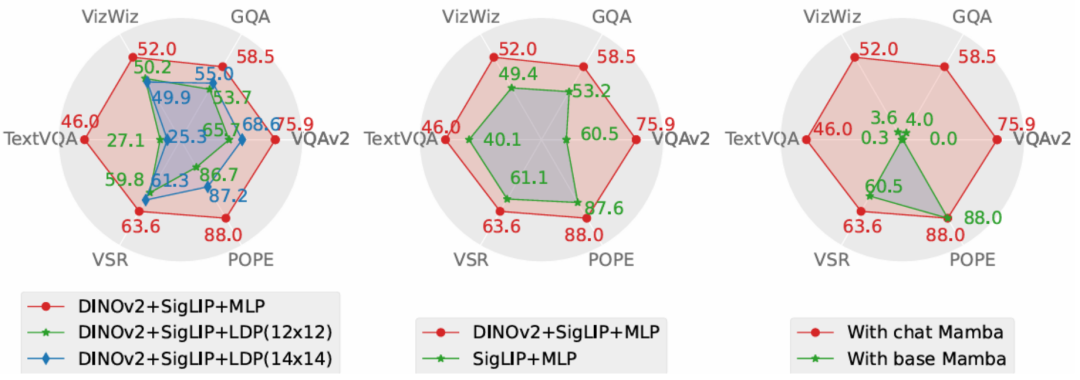
圖中 Cobra v2 特徵的融合有效的提升了 Cobra 的性能。而在語言主幹的實驗中,未經指令微調的 Mamba 語言模型在開放問答的測驗中完全無法給出合理的答案,而經過微調的 Mamba 語言模型則可以在各類任務上達到可觀的表現。 結論
本文提出了 Cobra,它解決了現有依賴具有二次計算複雜度的 Transformer 網路的多模態大型語言模型的效率瓶頸。本文探討了具有線性計算複雜度的語言模型與多模態輸入的結合。在融合視覺和語言資訊方面,本文透過對不同模態融合方案的深入研究,成功優化了 Mamba 語言模型的內部資訊整合,實現了更有效的多模態表徵。實驗表明,Cobra 不僅顯著提高了計算效率,而且在性能上與先進模型如 LLaVA 相當,尤其在克服視覺幻覺和空間關係判斷方面表現出色。它甚至顯著減少了參數的數量。這為未來在需要高頻處理視覺訊息的環境中部署高性能 AI 模型,例如基於視覺的機器人回饋控制,開啟了新的可能性。
以上是首個基於Mamba的MLLM來了!模型權重、訓練程式碼等已全部開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















