

有效評估Agent實際表現,新型線上評測架構WebCanvas來了

潘奕琛:浙江大學碩士一年級研究生。孔德涵:跨越星空科技模型演算法負責人。周思達:南昌大學 2024 年畢業生,將於西安電子科技大學攻讀碩士。崔成:浙江中醫藥大學 2024 屆畢業生,將於蘇州大學攻讀碩士。
潘奕琛、週思達、崔成以跨越星空科技演算法實習生的身份共同完成了本論文的研究工作。
在當今科技迅速發展的時代,大型語言模型(Large Language Model,LLM)正以前所未有的速度改變著我們與數位世界的互動方式。基於 LLM 的智慧型代理(LLM Agent),從簡單的資訊搜尋到複雜的網頁操作,它們正在逐步融入我們的生活。然而,一個關鍵問題仍然懸而未決:當這些 LLM Agent 踏入真實的線上網路世界時,它們的表現能否如預期般游刃有餘?
現有的評測方法大多停留在靜態資料集或模擬網站的層面。這些方法有其價值,但限制顯而易見:靜態資料集難以捕捉網頁環境的動態變化,如介面更新和內容迭代;而模擬網站則缺乏真實世界的複雜性,未能充分考慮跨站操作,例如使用搜尋引擎等操作,這些因素在真實環境中是不可或缺的。
為破解這個難題,一篇題為《WebCanvas: Benchmarking Web Agents
in Online Environments》的論文提出了一種創新的在線評測框架——WebCanvas,旨在為Agent 在真實網絡世界中的表現提供一個全面的評估方法。

論文連結:https://arxiv.org/pdf/2406.12373
WebCanvas 平台連結:https://imean.ai/web
- WebCanvas 平台連結:https://imean.ai/web-canvaso: //github.com/iMeanAI/WebCanvas
- 資料集連結:https://huggingface.co/datasets/iMeanAI/Mind2Web-Live

WebCanvas 框架圖。左側展示的是任務的標註過程,右側顯示的是任務的評估過程。 WebCanvas 考慮到了線上網路互動中任務路徑的非唯一性,「獎盃」 代表成功到達每個關鍵節點後獲得的步驟分數。
基於 WebCanvas 框架,作者建立了 Mind2Web-Live 資料集,該資料集包含從 Mind2Web 中隨機挑選出的 542 個任務。本文作者也為資料集中的每個任務都標註了關鍵節點。透過一系列實驗,我們發現,當 Agent 配備 Memory 模組,輔以 ReAct 推理框架,並搭載 GPT-4-turbo 模型後,其任務成功率提升至 23.1%。我們深信,隨著科技的不斷演進,Web Agent 的潛力依舊無限,這個數字很快就會被突破。關鍵節點
「關鍵節點」 的概念是 WebCanvas 的核心思想之一。關鍵節點指的是完成特定網路任務過程中不可或缺的步驟,也就是說,無論完成任務的路徑如何,這些步驟都是不可或缺的。這些步驟涵蓋了造訪特定網頁以及在頁面上執行特定操作,例如填寫表單或點擊按鈕。
以 WebCanvas 框架圖綠色部分為例,用戶需要在爛番茄網站上尋找評分最高的即將上映的冒險電影。他可以透過多種途徑達到目的,例如從爛番茄的首頁開始探索,或直接透過搜尋引擎定位置 “即將上映的電影” 頁面。在篩選影片的過程中,使用者可能會先選擇 「冒險」 類型,再根據受歡迎程度排序,或反之亦然。雖然存在多條實現目標的路徑,但進入特定頁面並進行篩選是完成任務不可或缺的步驟。因此,這三個操作被定義為該任務的關鍵節點。評估指標
WebCanvas 的評估系統分為兩大部分:步驟得分和任務得分,兩者共同構評估 WebAgent 綜合能力。- 步驟得分:衡量Agent 在關鍵節點上的表現,每個關鍵節點都與一個評估函數相關聯,透過三種評估目標(URL、元素路徑、元素值)和三種匹配函數(精確、包含、語意)來實現。每到達一個關鍵節點並通過評估函數,Agent 就能獲得對應的分數。

Ikhtisar fungsi penilaian, di mana E mewakili elemen web Element
Skor tugasan: dibahagikan kepada skor penyelesaian tugas dan skor kecekapan. Skor penyelesaian tugasan mencerminkan sama ada Ejen berjaya memperoleh semua markah langkah untuk tugasan ini. Skor kecekapan mengambil kira penggunaan sumber pelaksanaan tugas dan dikira sebagai purata bilangan langkah yang diperlukan untuk menjaringkan setiap langkah.
Mind2Web-Live Dataset
Pengarang memilih secara rawak 601 tugasan bebas masa daripada set latihan Mind2Web dan 179 tugasan bebas masa yang sama daripada subset Tugasan Silang set ujian ini, dan kemudian digabungkan dianotasi dalam persekitaran dalam talian sebenar. Akhirnya, penulis membina set data Mind2Web-Live yang terdiri daripada 542 tugasan, termasuk 438 sampel latihan dan 104 sampel untuk ujian. Rajah di bawah menunjukkan secara visual taburan hasil anotasi dan fungsi penilaian.

Alat anotasi data
Semasa proses anotasi data, pengarang menggunakan pemalam pelayar iMean Builder yang dibangunkan oleh Chuanxingkong Technology. Pemalam ini boleh merekodkan tingkah laku interaksi penyemak imbas pengguna, termasuk tetapi tidak terhad kepada klik, input teks, melayang, menyeret dan tindakan lain Ia juga merekodkan jenis operasi tertentu, parameter pelaksanaan, laluan Pemilih elemen sasaran, serta kandungan elemen dan kedudukan koordinat halaman. Selain itu, iMean Builder juga menjana tangkapan skrin halaman web untuk setiap langkah operasi, memberikan paparan intuitif aliran kerja pengesahan dan penyelenggaraan.
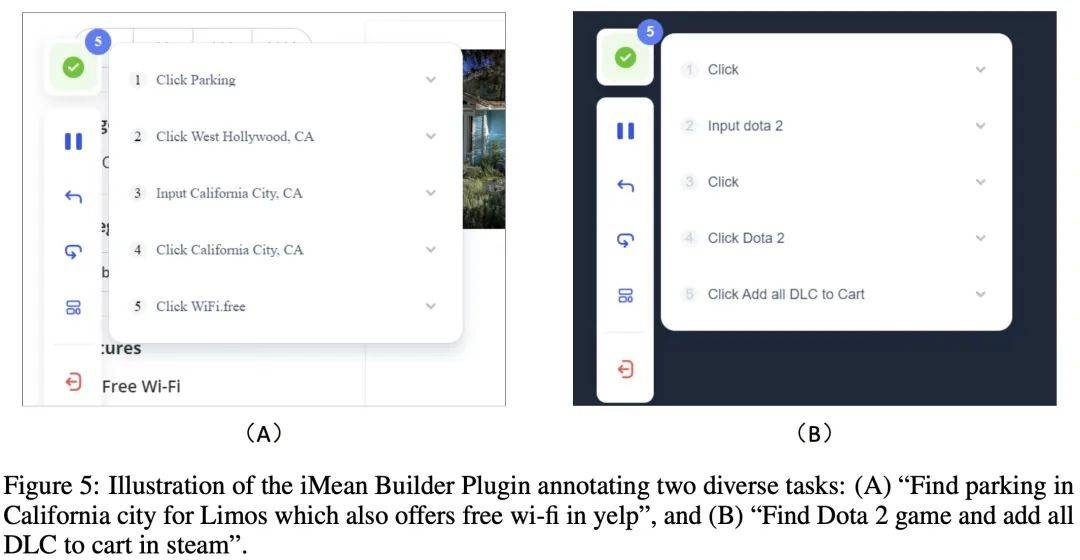
Contoh: Menganotasi dua tugasan berbeza menggunakan pemalam iMean Builder. (A) Cari tempat letak kereta limosin di California yang menawarkan Wi-Fi percuma di Yelp, (B) Cari permainan Dota 2 di Steam dan tambahkan semua DLC pada troli beli-belah anda
Penyelenggaraan data
Persekitaran rangkaian berubah dengan pantas, kemas kini kandungan laman web, pelarasan antara muka pengguna dan juga penutupan tapak adalah tidak dapat dielakkan dan normal. Perubahan ini boleh menyebabkan tugas atau nod utama yang ditakrifkan sebelum ini kehilangan ketepatan masanya, sekali gus menjejaskan kesahihan dan kesaksamaan penilaian.
Untuk tujuan ini, penulis telah merangka pelan penyelenggaraan data bertujuan untuk memastikan perkaitan dan ketepatan set penilaian yang berterusan. Dalam fasa pengumpulan data, selain menandakan nod utama, pemalam iMean Builder juga boleh merekodkan maklumat terperinci pada setiap langkah pelaksanaan aliran kerja, termasuk jenis tindakan, laluan Pemilih, nilai elemen, kedudukan koordinat, dsb. Penggunaan seterusnya strategi pemadanan elemen SDK iMean Replay boleh menghasilkan semula tindakan aliran kerja dan segera mengesan dan melaporkan sebarang keadaan tidak sah dalam aliran kerja atau fungsi penilaian.
Melalui penyelesaian ini, kami menyelesaikan cabaran yang disebabkan oleh kegagalan proses dengan berkesan, memastikan set data penilaian boleh menyesuaikan diri dengan evolusi berterusan dunia dalam talian, dan menyediakan asas yang kukuh untuk keupayaan Ejen penilaian automatik.
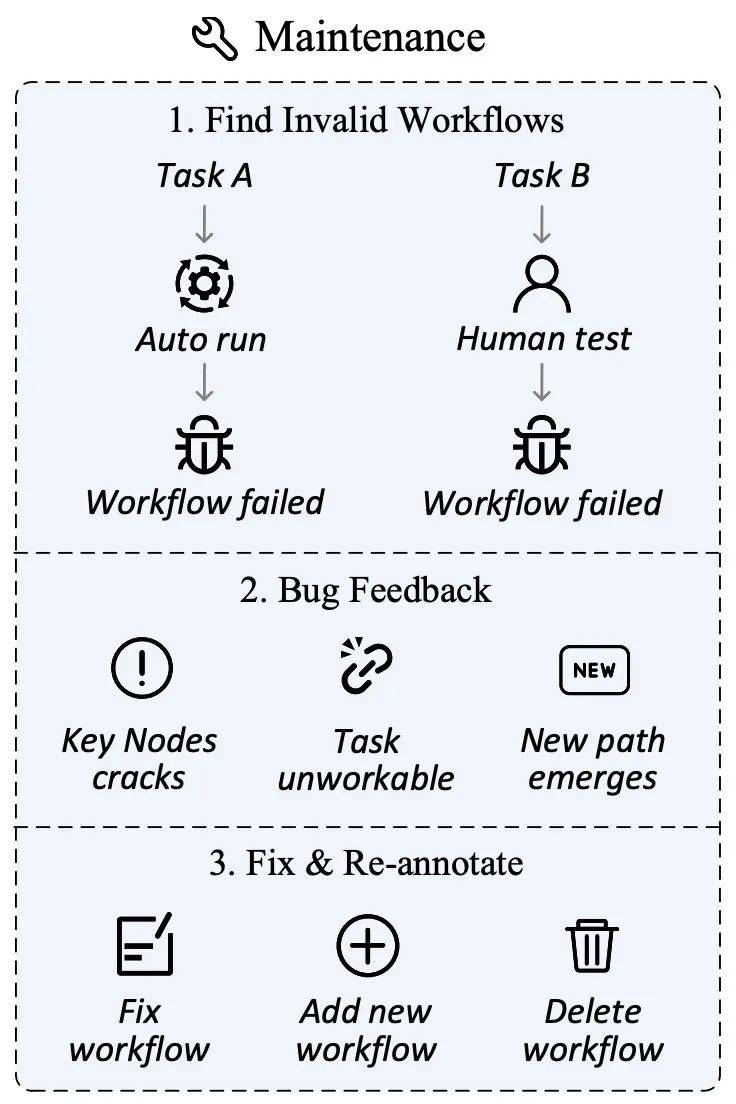
Platform Pengurusan Data
Di tapak web WebCanvas, pengguna boleh menyemak imbas dengan jelas semua proses tugasan yang direkodkan dan nod utama mereka, dan juga boleh memberi maklum balas yang cepat terhadap proses yang gagal kepada pentadbir platform untuk memastikan ketepatan masa dan ketepatan data.
Pada masa yang sama, penulis menggalakkan ahli komuniti untuk mengambil bahagian secara aktif dan bersama-sama membina ekosistem yang baik. Sama ada ia mengekalkan integriti data sedia ada, membangunkan ejen yang lebih maju untuk ujian, atau bahkan mencipta set data baharu sepenuhnya, WebCanvas mengalu-alukan sumbangan dari semua jenis. Ini bukan sahaja menggalakkan peningkatan kualiti data, tetapi juga menggalakkan inovasi teknologi, yang boleh membentuk kitaran murni untuk menggalakkan pembangunan seluruh bidang.
webcanvas homepage
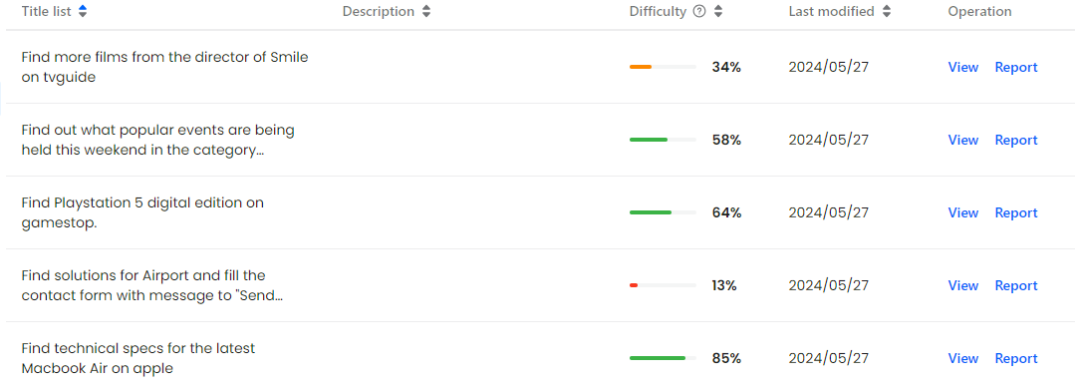
visual paparan mind2web-live dataset
basic ejen rangka kerja
Penulis telah membina rangka kerja ejen yang komprehensif yang direka untuk mengoptimumkan ejen dalam rangkaian pelaksanaan tugas dalam talian dalam persekitaran. Rangka kerja ini terutamanya terdiri daripada empat komponen utama: modul Perancangan, Pemerhatian, Ingatan dan Ganjaran.
Perancangan: Berdasarkan input Pokok Kebolehcapaian, modul Perancangan menggunakan rangka kerja penaakulan ReAct untuk melaksanakan inferens logik dan menjana arahan operasi khusus. Fungsi teras modul ini adalah untuk memberikan laluan tindakan berdasarkan status semasa dan matlamat tugas.
Pemerhatian: Ejen menghuraikan kod sumber HTML yang disediakan oleh penyemak imbas dan menukarnya menjadi struktur Pokok Kebolehcapaian. Proses ini memastikan bahawa Ejen boleh menerima maklumat halaman web dalam format piawai untuk analisis dan membuat keputusan seterusnya.
Memori: Modul Memori bertanggungjawab untuk menyimpan data sejarah Ejen semasa pelaksanaan tugas, termasuk tetapi tidak terhad kepada proses pemikiran Ejen, keputusan lepas, dsb.
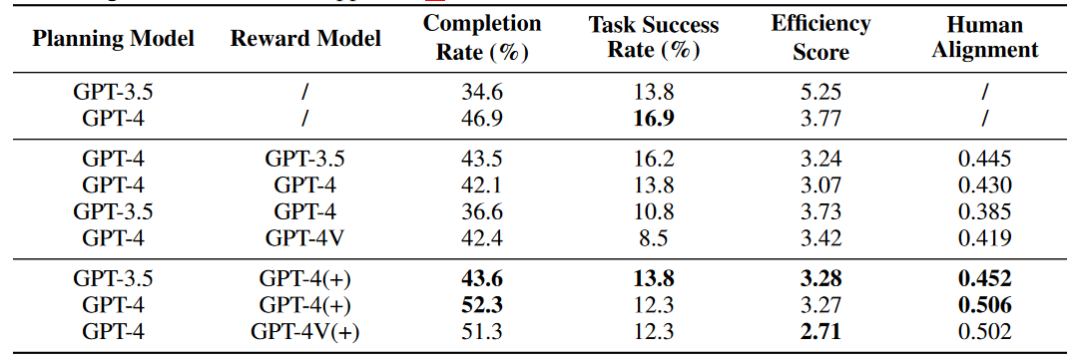
Ganjaran: Modul Ganjaran boleh menilai tingkah laku Ejen, termasuk maklum balas tentang kualiti membuat keputusan dan memberi isyarat penyelesaian tugas. . Keputusan percubaan ditunjukkan dalam rajah di bawah, di mana Kadar Penyiapan merujuk kepada kadar pencapaian nod utama, dan Kadar Kejayaan Tugasan merujuk kepada kadar kejayaan tugasan.

Selain itu, penulis juga meneroka kesan modul Ganjaran terhadap keupayaan Ejen Tanda (+) menunjukkan bahawa maklumat Ganjaran mengandungi data anotasi manusia dan maklumat nod utama untuk rujukan Ejen. skor Penjajaran Manusia mewakili Sejauh mana ejen itu sejajar dengan manusia. Keputusan percubaan awal menunjukkan bahawa dalam persekitaran rangkaian dalam talian, Ejen tidak dapat meningkatkan keupayaannya melalui modul Ganjaran Diri, tetapi modul Ganjaran yang menyepadukan data anotasi asal boleh meningkatkan keupayaan Ejen.
Experimental Analysis
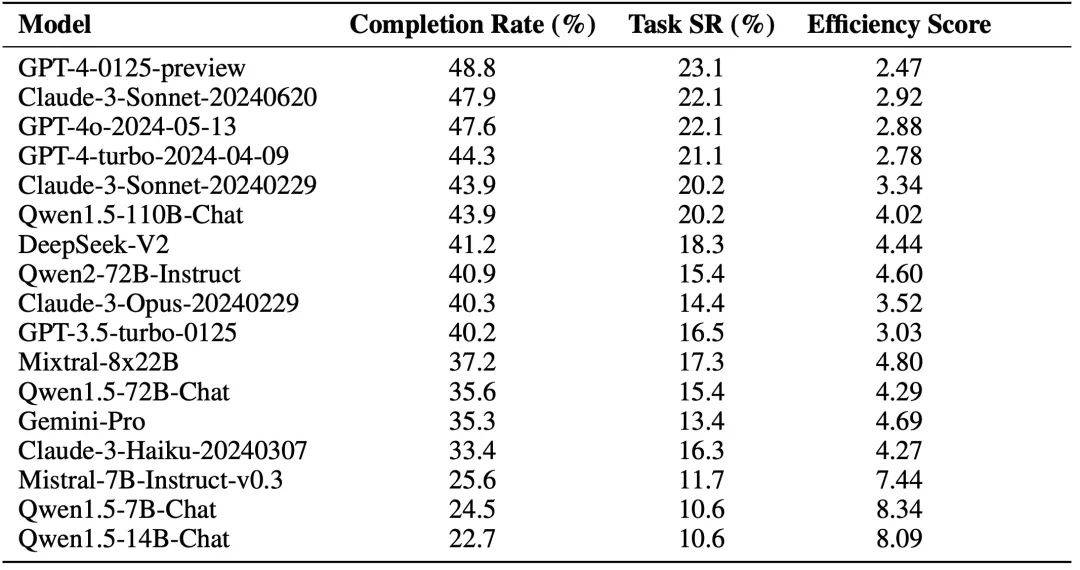

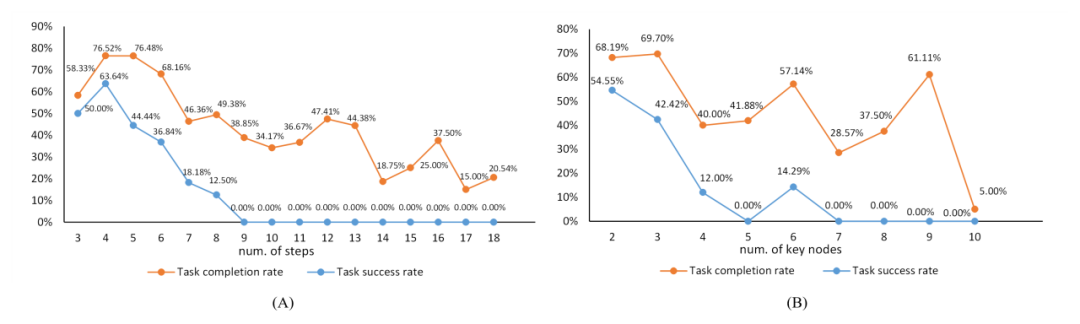
Hubungan antara kerumitan tugas dan kesukaran tugas. "bilangan langkah" merujuk kepada panjang urutan tindakan dalam data beranotasi, yang bersama-sama dengan bilangan nod utama berfungsi sebagai rujukan untuk kerumitan tugas.
 Jadual berikut menunjukkan hubungan antara keputusan percubaan dan kawasan, peralatan dan sistem.
Jadual berikut menunjukkan hubungan antara keputusan percubaan dan kawasan, peralatan dan sistem.
Ringkasan
 Dalam perjalanan untuk mempromosikan pembangunan LLM dan teknologi Agen, adalah penting untuk membina sistem penilaian yang menyesuaikan diri dengan persekitaran rangkaian sebenar. Artikel ini memberi tumpuan kepada menilai prestasi Ejen secara berkesan dalam dunia Internet yang berubah dengan pantas. Kami menghadapi cabaran secara berterusan dan mencapai matlamat ini dengan mentakrifkan nod utama dan fungsi penilaian yang sepadan dalam persekitaran terbuka, dan membangunkan sistem penyelenggaraan data untuk mengurangkan kos penyelenggaraan seterusnya.
Dalam perjalanan untuk mempromosikan pembangunan LLM dan teknologi Agen, adalah penting untuk membina sistem penilaian yang menyesuaikan diri dengan persekitaran rangkaian sebenar. Artikel ini memberi tumpuan kepada menilai prestasi Ejen secara berkesan dalam dunia Internet yang berubah dengan pantas. Kami menghadapi cabaran secara berterusan dan mencapai matlamat ini dengan mentakrifkan nod utama dan fungsi penilaian yang sepadan dalam persekitaran terbuka, dan membangunkan sistem penyelenggaraan data untuk mengurangkan kos penyelenggaraan seterusnya.
Melalui usaha yang tidak putus-putus, kami telah mengambil langkah besar ke arah mewujudkan sistem penilaian dalam talian yang mantap dan tepat. Walau bagaimanapun, menjalankan semakan dalam ruang siber dinamik bukanlah mudah, dan ia memperkenalkan satu siri isu kompleks yang tidak ditemui dalam senario luar talian yang tertutup. Dalam proses menilai Ejen, kami menghadapi kesukaran seperti sambungan rangkaian yang tidak stabil, akses laman web yang terhad dan pengehadan fungsi penilaian. Masalah ini menyerlahkan tugas sukar untuk menilai Ejen dalam persekitaran dunia sebenar yang kompleks, yang memerlukan kami untuk terus memperhalusi dan melaraskan rangka kerja penaakulan dan penilaian Ejen. Kami menyeru seluruh komuniti penyelidikan saintifik untuk bekerjasama untuk menghadapi cabaran yang tidak diketahui dan mempromosikan inovasi dan peningkatan teknologi penilaian. Kami amat percaya bahawa hanya melalui penyelidikan dan amalan yang berterusan, halangan ini dapat diatasi secara beransur-ansur. Kami berharap dapat bekerjasama dengan rakan sebaya kami untuk mencipta era baharu Agen LLM.
以上是有效評估Agent實際表現,新型線上評測架構WebCanvas來了的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 突破傳統缺陷檢測的界限,\'Defect Spectrum\'首次實現超高精度豐富語意的工業缺陷檢測。
Jul 26, 2024 pm 05:38 PM
突破傳統缺陷檢測的界限,\'Defect Spectrum\'首次實現超高精度豐富語意的工業缺陷檢測。
Jul 26, 2024 pm 05:38 PM
在現代製造業中,精準的缺陷檢測不僅是確保產品品質的關鍵,更是提升生產效率的核心。然而,現有的缺陷檢測資料集常常缺乏實際應用所需的精確度和語意豐富性,導致模型無法辨識特定的缺陷類別或位置。為了解決這個難題,由香港科技大學廣州和思謀科技組成的頂尖研究團隊,創新地開發了「DefectSpectrum」資料集,為工業缺陷提供了詳盡、語義豐富的大規模標註。如表一所示,相較於其他工業資料集,「DefectSpectrum」資料集提供了最多的缺陷標註(5438張缺陷樣本),最細緻的缺陷分類(125個缺陷類別
 數百萬晶體資料訓練,解決晶體學相位問題,深度學習方法PhAI登Science
Aug 08, 2024 pm 09:22 PM
數百萬晶體資料訓練,解決晶體學相位問題,深度學習方法PhAI登Science
Aug 08, 2024 pm 09:22 PM
編輯|KX時至今日,晶體學所測定的結構細節和精度,從簡單的金屬到大型膜蛋白,是任何其他方法都無法比擬的。然而,最大的挑戰——所謂的相位問題,仍然是從實驗確定的振幅中檢索相位資訊。丹麥哥本哈根大學研究人員,開發了一種解決晶體相問題的深度學習方法PhAI,利用數百萬人工晶體結構及其相應的合成衍射數據訓練的深度學習神經網絡,可以產生準確的電子密度圖。研究表明,這種基於深度學習的從頭算結構解決方案方法,可以以僅2埃的分辨率解決相位問題,該分辨率僅相當於原子分辨率可用數據的10%到20%,而傳統的從頭算方
 英偉達對話模式ChatQA進化到2.0版本,上下文長度提到128K
Jul 26, 2024 am 08:40 AM
英偉達對話模式ChatQA進化到2.0版本,上下文長度提到128K
Jul 26, 2024 am 08:40 AM
開放LLM社群正是百花齊放、競相爭鳴的時代,你能看到Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1等許多表現優良的模型。但是,相較於以GPT-4-Turbo為代表的專有大模型,開放模型在許多領域仍有明顯差距。在通用模型之外,也有一些專精關鍵領域的開放模型已被開發出來,例如用於程式設計和數學的DeepSeek-Coder-V2、用於視覺-語言任務的InternVL
 GoogleAI拿下IMO奧數銀牌,數學推理模型AlphaProof面世,強化學習 is so back
Jul 26, 2024 pm 02:40 PM
GoogleAI拿下IMO奧數銀牌,數學推理模型AlphaProof面世,強化學習 is so back
Jul 26, 2024 pm 02:40 PM
對AI來說,奧數不再是問題了。本週四,GoogleDeepMind的人工智慧完成了一項壯舉:用AI做出了今年國際數學奧林匹克競賽IMO的真題,並且距拿金牌僅一步之遙。上週剛結束的IMO競賽共有六道賽題,涉及代數、組合學、幾何和數論。谷歌提出的混合AI系統做對了四道,獲得28分,達到了銀牌水準。本月初,UCLA終身教授陶哲軒剛剛宣傳了百萬美元獎金的AI數學奧林匹克競賽(AIMO進步獎),沒想到7月還沒過,AI的做題水平就進步到了這種水平。 IMO上同步做題,做對了最難題IMO是歷史最悠久、規模最大、最負
 PRO | 為什麼基於 MoE 的大模型更值得關注?
Aug 07, 2024 pm 07:08 PM
PRO | 為什麼基於 MoE 的大模型更值得關注?
Aug 07, 2024 pm 07:08 PM
2023年,幾乎AI的每個領域都在以前所未有的速度進化,同時,AI也不斷地推動著具身智慧、自動駕駛等關鍵賽道的技術邊界。在多模態趨勢下,Transformer作為AI大模型主流架構的局面是否會撼動?為何探索基於MoE(專家混合)架構的大模型成為業界新趨勢?大型視覺模型(LVM)能否成為通用視覺的新突破? ……我們從過去的半年發布的2023年本站PRO會員通訊中,挑選了10份針對以上領域技術趨勢、產業變革進行深入剖析的專題解讀,助您在新的一年裡為大展宏圖做好準備。本篇解讀來自2023年Week50
 為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
編輯|ScienceAI問答(QA)資料集在推動自然語言處理(NLP)研究中發揮著至關重要的作用。高品質QA資料集不僅可以用於微調模型,也可以有效評估大語言模型(LLM)的能力,尤其是針對科學知識的理解和推理能力。儘管目前已有許多科學QA數據集,涵蓋了醫學、化學、生物等領域,但這些數據集仍有一些不足之處。其一,資料形式較為單一,大多數為多項選擇題(multiple-choicequestions),它們易於進行評估,但限制了模型的答案選擇範圍,無法充分測試模型的科學問題解答能力。相比之下,開放式問答
 準確率達60.8%,浙大基於Transformer的化學逆合成預測模型,登Nature子刊
Aug 06, 2024 pm 07:34 PM
準確率達60.8%,浙大基於Transformer的化學逆合成預測模型,登Nature子刊
Aug 06, 2024 pm 07:34 PM
編輯|KX逆合成是藥物發現和有機合成中的關鍵任務,AI越來越多地用於加快這一過程。現有AI方法性能不盡人意,多樣性有限。在實踐中,化學反應通常會引起局部分子變化,反應物和產物之間存在很大重疊。受此啟發,浙江大學侯廷軍團隊提出將單步逆合成預測重新定義為分子串編輯任務,迭代細化目標分子串以產生前驅化合物。並提出了基於編輯的逆合成模型EditRetro,該模型可以實現高品質和多樣化的預測。大量實驗表明,模型在標準基準資料集USPTO-50 K上取得了出色的性能,top-1準確率達到60.8%。
 Nature觀點,人工智慧在醫學上的測試一片混亂,該怎麼做?
Aug 22, 2024 pm 04:37 PM
Nature觀點,人工智慧在醫學上的測試一片混亂,該怎麼做?
Aug 22, 2024 pm 04:37 PM
編輯|ScienceAI基於有限的臨床數據,數百種醫療演算法已被批准。科學家們正在討論由誰來測試這些工具,以及如何最好地進行測試。 DevinSingh在急診室目睹了一名兒科患者因長時間等待救治而心臟驟停,這促使他探索AI在縮短等待時間中的應用。 Singh利用了SickKids急診室的分診數據,與同事們建立了一系列AI模型,用於提供潛在診斷和推薦測試。一項研究表明,這些模型可以加快22.3%的就診速度,將每位需要進行醫學檢查的患者的結果處理速度加快近3小時。然而,人工智慧演算法在研究中的成功只是驗證此
