大語言模型(LLM)被越來越多應用於各種領域。然而,它們的文本生成過程既昂貴又緩慢。這種低效率歸因於自迴歸解碼的運算規則:每個字(token)的生成都需要進行一次前向傳播,需要存取數十億至數千億參數的 LLM。這導致傳統自回歸解碼的速度較慢。 近日,滑鐵盧大學、加拿大向量研究院、北京大學等機構聯合發布 EAGLE,旨在提升大語言模型的推理速度,同時保證模型輸出文本的分佈一致。這種方法外推 LLM 的第二個頂層特徵向量,能夠顯著提升生成效率。 
- 技術報告:https://sites.google.com/view/eagle-llm
- 程式碼(支援商用Apache 2.0):https://github.com/LE
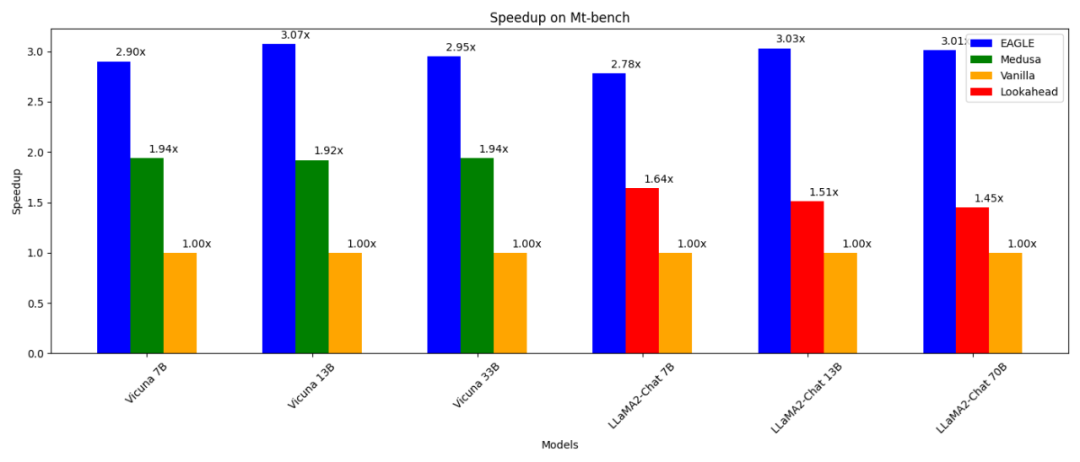
比普通自回歸解碼(13B)快3 倍;- 比普通自回歸解碼(13B)快3 倍;比;解碼(13B)快1.6 倍;
-
可以在RTX 3090 上進行訓練(1-2 天內)和測試;可以在RTX 3090 上進行訓練(1-2 月)和測試;
與vLLM、DeepSpeed、Mamba、FlashAttention、量化和硬體優化等其他平行技術結合使用。
加速自迴歸解碼的一種方法是投機取樣(speculative sampling)。這種技術使用一個較小的草稿模型,透過標準自迴歸產生來猜測接下來的多個字。隨後,原始 LLM 並行驗證這些猜測的字詞(只需要進行一次前向傳播進行驗證)。如果草稿模型準確預測了 α 詞,原始 LLM 的一次前向傳播就可以產生 α+1 個字。
這個局限啟發了 EAGLE 的發展。 EAGLE 利用原始 LLM 擷取的上下文特徵(即模型第二頂層輸出的特徵向量)。 EAGLE 建立在以下第一原理之上:特徵向量序列是可壓縮的,所以根據前面的特徵向量預測後續特徵向量比較容易。 EAGLE 訓練了一個輕量級插件,稱為自回歸頭(Auto-regression Head),與詞嵌入層一起,基於當前特徵序列從原始模型的第二頂層預測下一個特徵。然後使用原始 LLM 的凍結分類頭來預測下一個單字。特徵比詞序列包含更多信息,使得回歸特徵的任務比預測詞的任務簡單得多。總之,EAGLE 在特徵層面上進行外推,使用一個小型自回歸頭,然後利用凍結的分類頭產生預測的單字序列。與投機採樣、Medusa 和 Lookahead 等類似的工作一致,EAGLE 關注的是每次提示推理的延遲,而不是整體系統吞吐量。 EAGLE——一種增強大語言模型生成效率的方法
上圖顯示了 EAGLE 與標準投機取樣、Medusa 以及 Lookahead 關於輸入輸出的差異。下圖展示了 EAGLE 的工作流程。在原始 LLM 的前向過程中,EAGLE 從第二頂層收集特徵。自回歸頭以這些特徵以及先前生成的詞的詞嵌入作為輸入,開始猜下一個詞。隨後,使用凍結的分類頭(LM Head)確定下一個單字的分佈,使 EAGLE 能夠從這個分佈中進行取樣。透過多次重複採樣,EAGLE 進行了類似樹狀的生成過程,如下圖右側所示。在這個例子中,EAGLE 的三次前向傳播 “猜” 出了 10 個字組成的樹。 
EAGLE 使用輕量級的自回歸頭來預測原始 LLM 的特徵。為了確保產生文字分佈的一致性,EAGLE 隨後驗證預測的樹狀結構。這個驗證過程可以使用一次前向傳播完成。透過這個預測和驗證的循環,EAGLE 能夠快速產生文字單字。 訓練自回歸頭代價很小。 EAGLE 使用 ShareGPT 資料集進行訓練,該資料集包含不到 70,000 輪對話。自回歸頭的可訓練參數數量也很少。如上圖中的藍色部分所示,大多數組件都是凍結的。唯一要額外訓練的是自回歸頭,這是一個單層 Transformer 結構,具有 0.24B-0.99B 參數。即使在 GPU 資源不足的情況下,也可以訓練自回歸頭。例如,Vicuna 33B 的自回歸頭可以在 8 卡 RTX 3090 伺服器上在 24 小時內完成訓練。 Medusa 僅使用第二頂層的特徵來預測下一個詞,下下個字......與Medusa 不同,EAGLE 還動態地將當前採樣得到的詞嵌入作為自回歸頭輸入的一部分來進行預測。這額外的資訊有助於 EAGLE 處理抽樣過程中不可避免的隨機性。考慮下圖中的例子,假設提示詞是 “I”。 LLM 給了 “I” 後面跟著 “am” 或 “always” 的機率。 Medusa 不考慮是抽樣了 “am” 還是 “always”,直接預測 “I” 下個字的機率。因此,Medusa 的目標是,在只給定 “I” 的基礎上,預測 “I am” 或 “I always” 的下一個字。由於抽樣過程的隨機性,Medusa 的相同輸入 “I” 可能有不同的下個詞輸出 “ready” 或 “begin”,導致輸入和輸出之間缺乏一致的映射。相較之下,EAGLE 的輸入包括了抽樣結果的字詞嵌入,確保了輸入和輸出之間的一致映射。這種區別使 EAGLE 能夠考慮抽樣過程建立的上下文,進而更準確地預測後續詞彙。 
與投機採樣、Lookahead 和Medusa 等其他猜測- 驗證框架不同,EAGLE 在「猜詞」 階段採用類似樹狀的生成結構,進而實現而實現了更相似高的解碼效率。如圖所示,標準投機採樣和 Lookahead 的生成過程是線性或鍊式的。 Medusa 的方法由於在猜測階段無法建立上下文,故透過笛卡爾積生成樹,導致相鄰層之間形成全連接圖。這種方法經常導致無意義的組合,例如 “I am begin”。對比之下,EAGLE 創造了一個更稀疏的樹狀結構。這種稀疏的樹狀結構可防止形成無意義的序列,將計算資源集中在更合理的字詞組合上。 
標準投機採樣方法在進行 “猜詞” 的過程中保持了分佈的一致性。為了適應樹狀猜詞場景,EAGLE 將這種方法擴展成了多輪遞歸形式。下面呈現了多輪投機採樣的偽代碼。在樹狀生成過程中,EAGLE 記錄了每個抽樣詞對應的機率。透過多輪投機取樣,EAGLE 確保最終生成的每個單字的分佈與原始 LLM 的分佈保持一致。 
次の図は、さまざまなタスクにおける Vicuna 33B の EAGLE の加速効果を示しています。多数の固定テンプレートを含む「コーディング」タスクは、最高の高速化パフォーマンスを示します。 
EAGLE を体験して、GitHub の問題を通じてフィードバックや提案をお寄せください: https://github.com/SafeAILab/EAGLE/issues以上是大模型推理效率無損提升3倍,滑鐵盧大學、北京大學等機構發表EAGLE的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 在投機採樣中,草稿模型的任務是基於當前詞序列預測下一個詞。使用一個參數數量顯著較少的模型完成這個任務極具挑戰性,通常會產生次優結果。此外,標準投機採樣方法中的草稿模型獨立預測下一個詞而不利用原始 LLM 提取的豐富語義訊息,導致潛在的效率低下。
在投機採樣中,草稿模型的任務是基於當前詞序列預測下一個詞。使用一個參數數量顯著較少的模型完成這個任務極具挑戰性,通常會產生次優結果。此外,標準投機採樣方法中的草稿模型獨立預測下一個詞而不利用原始 LLM 提取的豐富語義訊息,導致潛在的效率低下。 




















