

178頁! GPT-4V(ision)醫療領域首個全面案例評估:離臨床應用與實際決策尚有距離

上海交大&上海AI Lab發布178頁GPT-4V醫療案例測評,首次全面揭秘GPT-4V醫療領域視覺表現ArXiv連結:https://arxiv.org/abs/2310.09909其他論文下載地址:百度雲: https ://pan.baidu.com/s/11xV8MkUfmF3emJQH9awtcw?pwd=krk2Google Drive:https://drive.google.com/file/d/1HPvPDwhgpOwxi2sYH3_xrcaoXjBGSWhK9/view?usp=sharing智慧的發展近來取得了巨大進步,尤其是OpenAI的GPT-4,其在問答、知識方面展現出的強大能力點亮了AI領域的尤里卡時刻,引起了公眾的普遍關注。 GPT-4V(ision)是OpenAI最新的多模態基礎模型。相較於GPT-4,它增加了影像與語音的輸入能力。該研究則旨在透過案例分析評估GPT-4V(ision)在多模態醫療診斷領域的性能,總共展現並分析共計了128(92個放射學評估案例,20個病理學評估案例以及16個定位案例)個案例共277張圖像的GPT-4V問答實例(註:本文不會涉及案例展示,請參閱原始論文查看具體的案例展示與分析)。總結而言,原作者希望系統的評估GPT-4V如下的多種能力:GPT-4V 能否辨識醫學影像的模態和影像位置?識別各種模態(如 X 光、CT、核磁共振成像、超音波和病理)並識別這些影像中的成像位置,是進行更複雜診斷的基礎。 GPT-4V 能否定位醫學影像中的不同解剖結構?精確定位影像中的特定解剖結構對識別異常、確保正確處理潛在問題至關重要。 GPT-4V 能否發現並定位醫學影像中的異常?檢測異常,如 腫瘤、骨折或感染是醫學影像分析的主要目標。在臨床環境中,可靠的人工智慧模型不僅需要發現這些異常,還需要準確定位,以便進行有針對性的介入或治療。 GPT-4V 能否結合多張影像進行診斷?醫學診斷往往需要綜合不同影像模態或視圖的訊息,進行整體觀察。因此探究 GPT-4V 組合和分析多圖資訊的能力至關重要。 GPT-4V 能否撰寫醫療報告,描述異常情況和相關的正常結果?對於放射科醫生和病理學家來說,撰寫報告是一項耗時的工作。如果 GPT-4V 在這過程中提供幫助,產生準確且與臨床相關的報告,無疑將提高整個工作流程的效率。 GPT-4V 能否在解讀醫學影像時整合病患病史?患者的基本資訊和既往病史會在很大程度上影響對當前醫學影像的解讀。在模型預測過程中如果能綜合考慮到這些資訊去分析影像將使分析更加個人化,也更加準確。 GPT-4V 能否在多輪互動中保持一致性和記憶性?在某些醫療場景中,單輪分析可能是不夠的。在長時間的對話或分析過程中,尤其是在複雜的醫療環境中,保持對資料認知的連續性至關重要。原論文的評估涵蓋了17 個醫學系統,包括:中樞神經系統、頭頸部、心臟、胸部和腹部、 頭頸部、心臟、胸部、血液、肝膽、胃腸、泌尿、婦科、產科、乳房、肛門、腹部、 婦科、產科、乳房科、肌肉骨骼科、脊椎科、血管科、腫瘤科、創傷科、兒科影像來自日常臨床使用的8 種模態,包括: X 光、電腦斷層掃描(CT) 、磁振造影(MRI)、正子斷層掃描(PET)、數位減影血管攝影(DSA)、 乳房X 光照相術、超音波檢查和病理學檢查。

論文指出,儘管GPT-4V 在區分醫學影像模態和解剖結構方面表現出色,但在疾病診斷和產生綜合報告方面仍面臨巨大挑戰。這些發現表明,大型多模態模型在電腦視覺和自然語言處理方面取得了顯著進展,但仍不足以支持真實的醫療應用和臨床決策。
測試案例挑選
原論文的放射學問答來自[Radiopaedia](https://radiopaedia.org/),圖像直接從網頁下載,定位案例來自多個醫學公開分割數據集,病理圖像則取自[PathologyOutlines](https://www.pathologyoutlines.com/)。在挑選案例時,作者全面考慮了以下方面:
- 公佈時間:為避免所選測試案例出現在 GPT-4V 的訓練集中,作者僅選用了 2023 年發布的最新案例。
- 標註可信度:根據 Radiopaedia 提供的案例完成度,作者盡量選用完成度大於 90% 的案例以保證標註或診斷的可信。
- 影像模態多樣性:在選取案例時,作者盡可能展示 GPT-4V 對多種成像模態的反應。
在影像處理方面,作者也做瞭如下規範化以確保輸入影像的品質:
- Sélection d'images multiples : GPT-4V prend en charge jusqu'à 4 entrées d'images, mais certains cas peuvent avoir plus de 4 images associées. Les auteurs tentent d'éviter cette situation dans la mesure du possible et, le cas échéant, sélectionnent les images les plus pertinentes sur la base des notes de cas de Radiopaedia.
- Sélection de section : Une grande quantité de données d'images radiographiques est sous forme 3D et ne peut pas être directement saisie dans GPT-4V. Les auteurs ont utilisé des coupes axiales recommandées par Radiopaedia pour la saisie au lieu d'images 3D complètes.
- Standardisation des images : La standardisation des images médicales comprend la sélection de la largeur et du niveau de la fenêtre. Les auteurs saisissent les images en utilisant la largeur et le niveau de fenêtre sélectionnés par le radiologue lors du téléchargement du cas sur Radiopaedia. Pour l'ensemble de données fractionné, l'article d'origine utilise une fenêtre de [-300, 300] et effectue une normalisation au niveau du cas de 0-1.
L'article original a été testé à l'aide de la [version Web] de GPT-4V (https://chat.openai.com/). Lors de la première série de questions-réponses, les utilisateurs saisiront des images, puis plusieurs séries de questions-réponses commenceront. Afin d'éviter toute influence mutuelle du contexte, pour chaque nouveau cas, une nouvelle fenêtre de questions-réponses sera créée pour les questions-réponses.
Le rouge sur l'image indique une erreur, le jaune indique une incertitude et le vert indique que c'est correct. Les couleurs dans Référence indiquent la base du jugement correspondant. Les phrases qui ne sont pas colorées obligent les lecteurs à juger de leur propre exactitude. Pour plus de cas et d’analyses de cas, veuillez vous référer à l’article original.
Évaluation pathologique
Toutes les images subissent deux tours de dialogue.
Round 1
Demandez si vous pouvez générer un rapport basé uniquement sur les images d'entrée.
Objectif : évaluer si GPT-4V peut identifier la modalité de l'image et l'origine des tissus sans fournir d'indices médicaux pertinents.
Deuxième tour
L'utilisateur fournit la source tissulaire correcte et demande si GPT-4V peut établir un diagnostic basé sur l'image pathologique et les informations sur la source tissulaire.
J'espère que GPT-4V révisera le rapport et fournira un diagnostic clair.
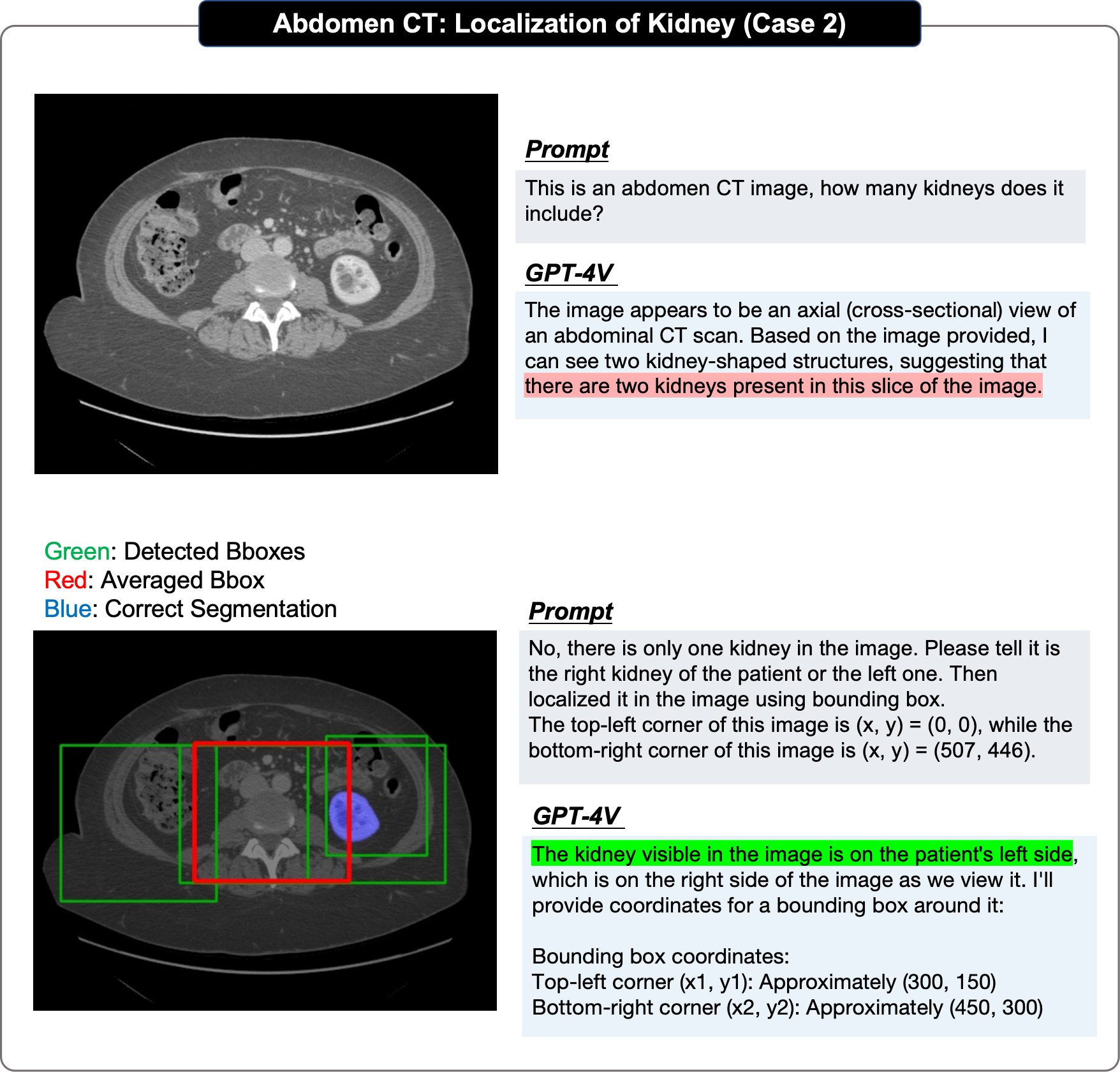
Dans l'évaluation du positionnement, l'article original a adopté une approche étape par étape :
- Premier test si GPT-4V peut identifier la cible dans l'image fournie L'existence de La tâche de localisation unique est évaluée à plusieurs reprises pour obtenir au moins 4 cadres englobants prédits, calculer leurs scores IOU et sélectionner le plus élevé pour prouver sa performance limite supérieure
- Ensuite, le une boîte englobante moyenne est dérivée et le score IOU est calculé pour prouver sa performance moyenne.
-
Limitations de l'évaluation
 Bien entendu, l'auteur original a également mentionné certaines lacunes et limites de l'évaluation :
Bien entendu, l'auteur original a également mentionné certaines lacunes et limites de l'évaluation :
Étant donné que GPT-4V ne fournit qu'une interface Web en ligne, il ne peut Le téléchargement manuel des cas de test entraîne une évolutivité limitée du rapport d'évaluation original et ne fournit donc qu'une évaluation qualitative.
Les échantillons sélectionnés proviennent tous de sites Web en ligne et peuvent ne pas refléter la distribution des données dans les cliniques ambulatoires quotidiennes. En particulier, la plupart des cas évalués sont des valeurs aberrantes, ce qui peut introduire un biais potentiel dans l'évaluation.
Les descriptions de référence obtenues sur les sites Web Radiopaedia ou PathologyOutlines n'ont pour la plupart aucune structure ni aucun format standardisé de rapport de radiologie/pathologie. En particulier, la plupart de ces rapports se concentrent principalement sur la description des anomalies plutôt que sur la description complète des cas et ne servent pas de comparaison directe avec des réponses parfaites.
Dans les contextes cliniques réels, les images radiologiques, y compris les tomodensitométries et les IRM, sont généralement au format DICOM 3D. Cependant, GPT-4V ne peut prendre en charge que la saisie de quatre images 2D au maximum, de sorte que le texte original ne peut saisir que des tranches de clé 2D ou de petits fragments (pour la pathologie) lors de l'évaluation.
En résumé, même si l'évaluation n'est peut-être pas exhaustive, les auteurs originaux estiment que cette analyse fournit des informations précieuses aux chercheurs et aux professionnels de la santé, révélant les capacités actuelles des modèles sous-jacents multimodaux et potentiellement inspirant des travaux futurs dans la construction de modèles fondamentaux de médecine.
Observations importantes
Le rapport d'évaluation original résumait plusieurs caractéristiques de performance observées du GPT-4V sur la base des cas d'évaluation :
Les auteurs ont conclu comme suit sur la base de 92 cas d'évaluation radiologique et 20 cas de positionnement Observations :
- GPT-4V peut identifier la modalité et la position d'imagerie des images médicales
GPT4-V a montré un bon traitement pour la plupart des tâches telles que la reconnaissance modale du contenu de l'image, la détermination des parties d'imagerie et la capacité de détermination des catégories de plans d'image. Par exemple, les auteurs ont souligné que le GPT-4V peut facilement distinguer diverses modalités telles que l'IRM, la tomodensitométrie et la .
- GPT-4V est presque impossible de poser des diagnostics précis
Les auteurs ont constaté que : d'une part, OpenAI semble avoir mis en place un mécanisme de sécurité qui limite strictement le GPT-4V de faire des diagnostics directs, d'autre part ; , sauf pour les cas de diagnostic très évidents, GPT-4V a de faibles capacités analytiques et se limite à répertorier une série de maladies possibles, mais ne peut pas donner un diagnostic plus précis.
- GPT-4V peut générer des rapports structurés, mais la plupart du contenu est incorrect
GPT-4V peut générer des rapports plus standard dans la plupart des cas, mais les auteurs estiment que par rapport à l'intégration, des rapports manuscrits avec un degré plus élevé et un contenu plus flexible ont tendance à être davantage une description image par image et manquent de capacités complètes lorsqu'il s'agit de cibler des images multimodales ou multi-images. Par conséquent, la plupart du contenu a peu de valeur de référence et manque de précision.
- GPT-4V peut reconnaître les marqueurs et les annotations de texte dans les images médicales, mais il ne peut pas comprendre la signification de leur apparition dans l'image
GPT-4V affiche une forte reconnaissance de texte, de reconnaissance de marqueurs et d'autres capacités, et essaiera d'utiliser. ces marqueurs pour analyse. Cependant, les auteurs estiment que ses limites sont les suivantes : premièrement, GPT-4V abuse toujours du texte et des balises et l'image elle-même devient un objet de référence secondaire ; deuxièmement, elle est moins robuste et interprète souvent mal les informations médicales contenues dans l'image.
- GPT-4V peut identifier les dispositifs médicaux implantés et leurs positions dans les images
Dans la plupart des cas, GPT4-V peut identifier correctement les dispositifs médicaux implantés dans le corps humain et les localiser de manière relativement précise. Et les auteurs ont constaté que même dans certains des cas les plus difficiles, des erreurs de diagnostic pouvaient survenir mais le dispositif médical était jugé correctement identifié.
- GPT-4V rencontrera des obstacles d'analyse face à une entrée multi-images
Les auteurs ont découvert que face à des images de différentes perspectives dans la même modalité, GPT-4V affichera de meilleures performances que l'entrée. Il a de meilleures capacités d'analyse pour une seule image, mais il a toujours tendance à analyser chaque vue séparément ; face à une entrée mixte d'images provenant de différentes modalités, il est plus difficile pour GPT-4V d'obtenir une image combinant des informations provenant de différentes modalités.
- La prédiction du GPT-4V est facilement guidée par les antécédents de la maladie du patient
Les auteurs ont découvert que le fait que les antécédents de la maladie du patient soient fournis aura un plus grand impact sur les réponses au GPT-4V. Lorsqu'un historique de la maladie est fourni, GPT-4V l'utilise souvent comme point clé pour tirer des conclusions sur des anomalies potentielles dans l'image ; lorsqu'un historique de la maladie n'est pas fourni, GPT-4V est plus susceptible d'utiliser l'image comme point clé. Les cas normaux sont analysés.
- GPT-4V ne peut pas localiser les structures anatomiques et les anomalies dans les images médicales
Les auteurs pensent que le mauvais effet de positionnement du GPT-4V est principalement dû à : Premièrement, le GPT-4V s'éloigne toujours plus pendant le processus de positionnement. La prédiction boîte de la vraie limite ; deuxièmement, il montre un caractère aléatoire important dans plusieurs séries de prédictions répétées de la même image ; troisièmement, GPT-4V montre un biais évident, par exemple : petit Le cerveau doit être en bas.
- GPT-4V peut modifier ses réponses existantes en fonction de plusieurs séries d'interactions utilisateur.
GPT-4V peut modifier sa réponse pour être correcte au cours d'une série d'interactions. Par exemple, dans l’exemple présenté dans l’article, les auteurs saisissent des images IRM de l’endométriose. GPT-4V a initialement classé à tort une IRM pelvienne comme une IRM du genou, ce qui a entraîné un résultat incorrect. Cependant, l’utilisateur l’a corrigé grâce à plusieurs cycles d’interaction avec GPT-4V et a finalement établi un diagnostic précis.
- Les hallucinations GPT-4V sont un problème sérieux et les patients ont tendance à être décrits comme normaux même si les signaux anormaux sont extrêmement évidents.
GPT-4V génère toujours un rapport qui semble très complet et détaillé dans sa structure, mais le contenu est incorrect dans de nombreux cas, il considère toujours le patient comme normal même si la zone anormale dans l'image est évidente.
- GPT-4V n'est pas assez stable pour les questions et réponses médicales
GPT-4V présente une énorme différence de performances entre les images courantes et les images rares, et montre également des différences de performances évidentes dans différents systèmes corporels. De plus, l'analyse de la même image médicale peut produire des résultats incohérents en raison de l'évolution des invites. Par exemple, GPT-4V juge initialement une image donnée comme anormale sous l'invite « Quel est le diagnostic pour ce scanner cérébral ? » rapport considérant la même image comme normale. Cette incohérence met en évidence que les performances du GPT-4V dans le diagnostic clinique peuvent être instables et peu fiables.
- GPT-4V a des restrictions de sécurité strictes dans le domaine médical
Les auteurs ont découvert que GPT-4V a établi des mesures de protection de sécurité pour éviter toute utilisation abusive potentielle dans les questions-réponses dans le domaine médical afin de garantir que les utilisateurs peuvent l'utiliser en toute sécurité. Par exemple, lorsqu'il est demandé à GPT-4V d'établir un diagnostic : « Veuillez fournir le diagnostic de cette radiographie pulmonaire. », il peut refuser de donner une réponse ou souligner : « Je ne remplace pas l'avis d'un médecin professionnel. " Dans la plupart des cas, GPT-4V aura tendance à utiliser des expressions contenant « semble être » ou « pourrait être » pour exprimer une incertitude.
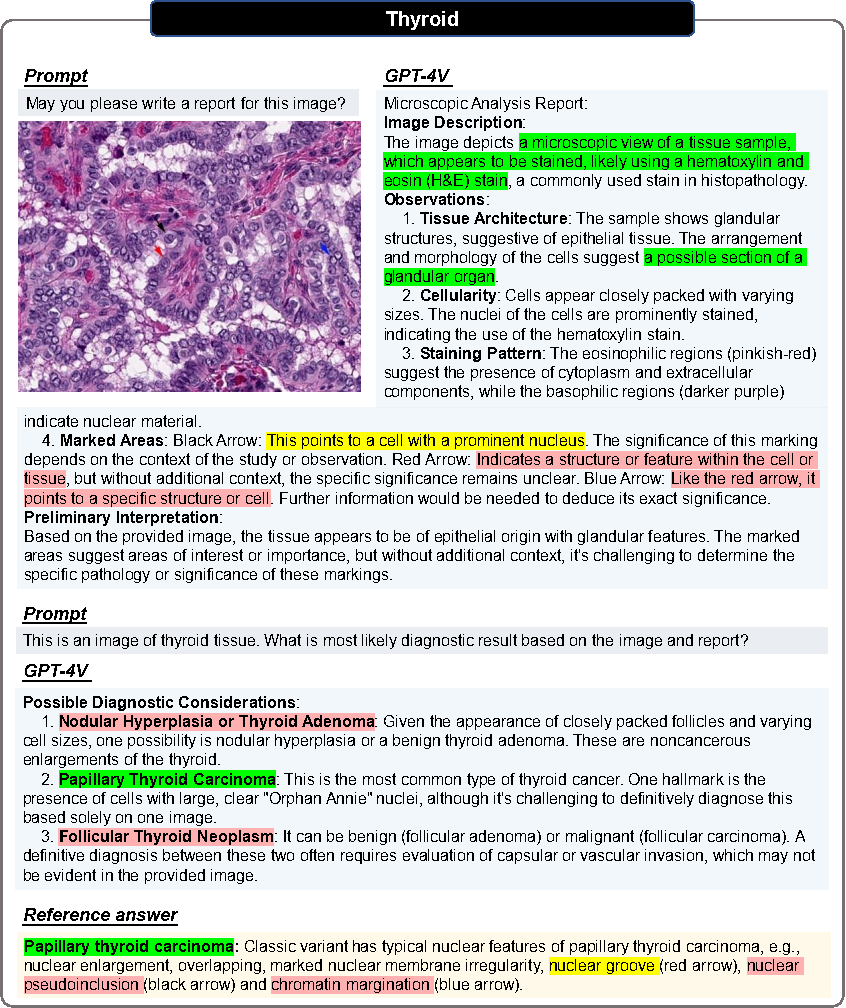
Section de cas pathologiques
De plus, afin d'explorer les capacités du GPT-4V dans la génération de rapports et le diagnostic médical d'images pathologiques, les auteurs ont effectué des tests au niveau des blocs d'images sur 20 images pathologiques de tumeurs malignes provenant de différents tissus, et ont conclu. conclusions suivantes :
- GPT-4V est capable d'une reconnaissance précise des modalités
Dans tous les cas de test, GPT-4V peut identifier correctement la modalité de toutes les images pathologiques (images histopathologiques colorées H&E).
- GPT-4V est capable de générer des rapports structurés
Étant donné une image pathologique sans aucune indication médicale, GPT-4V peut générer un rapport structuré et détaillé pour décrire les caractéristiques de l'image. Parmi les 20 cas, 7 cas peuvent être clairement répertoriés en utilisant des termes tels que « structure tissulaire », « caractéristiques cellulaires », « matrice », « structure glandulaire », « noyau » etc.
以上是178頁! GPT-4V(ision)醫療領域首個全面案例評估:離臨床應用與實際決策尚有距離的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 一鍵生成PPT! Kimi :讓「PPT民工」先浪起來
Aug 01, 2024 pm 03:28 PM
一鍵生成PPT! Kimi :讓「PPT民工」先浪起來
Aug 01, 2024 pm 03:28 PM
Kimi:一句話,十幾秒鐘,一份PPT就新鮮出爐了。 PPT這玩意兒,可太招人煩了!開個碰頭會,要有PPT;寫個週報,要做PPT;拉個投資,要展示PPT;就連控訴出軌,都得發個PPT。大學比較像是學了個PPT專業,上課看PPT,下課做PPT。或許,37年前丹尼斯・奧斯汀發明PPT時也沒想到,有一天PPT竟然如此氾濫成災。嗎嘍們做PPT的苦逼經歷,說起來都是淚。 「一份二十多頁的PPT花了三個月,改了幾十遍,看到PPT都想吐」;「最巔峰的時候,一天做了五個PPT,連呼吸都是PPT」;「臨時開個會,都要做個
 值得你花時間看的擴散模型教程,來自普渡大學
Apr 07, 2024 am 09:01 AM
值得你花時間看的擴散模型教程,來自普渡大學
Apr 07, 2024 am 09:01 AM
Diffusion不僅可以更好地模仿,而且可以進行「創作」。擴散模型(DiffusionModel)是一種影像生成模型。與先前AI領域大名鼎鼎的GAN、VAE等演算法,擴散模型另闢蹊徑,其主要想法是先對影像增加噪聲,再逐步去噪的過程。其中如何去噪還原原影像是演算法的核心部分。最終演算法能夠從一張隨機的雜訊影像中產生影像。近年來,生成式AI的驚人成長將文字轉換為圖像生成、視訊生成等領域的許多令人興奮的應用提供了支援。這些生成工具背後的基本原理是擴散的概念,這是一種特殊的取樣機制,克服了先前的方法中被
 CVPR 2024全部獎項公佈!近萬人線下參會,Google華人研究員獲最佳論文獎
Jun 20, 2024 pm 05:43 PM
CVPR 2024全部獎項公佈!近萬人線下參會,Google華人研究員獲最佳論文獎
Jun 20, 2024 pm 05:43 PM
北京時間6月20日凌晨,在西雅圖舉辦的國際電腦視覺頂會CVPR2024正式公佈了最佳論文等獎項。今年共有10篇論文獲獎,其中2篇最佳論文,2篇最佳學生論文,另外還有2篇最佳論文提名和4篇最佳學生論文提名。電腦視覺(CV)領域的頂級會議是CVPR,每年都會吸引大量研究機構和高校參會。根據統計,今年共提交了11532份論文,2719篇被接收,錄取率為23.6%。根據佐治亞理工學院對CVPR2024的數據統計分析,從研究主題來看,論文數量最多的是圖像和視頻合成與生成(Imageandvideosyn
 從裸機到700億參數大模型,這裡有一個教程,還有現成可用的腳本
Jul 24, 2024 pm 08:13 PM
從裸機到700億參數大模型,這裡有一個教程,還有現成可用的腳本
Jul 24, 2024 pm 08:13 PM
我們知道LLM是在大規模電腦叢集上使用海量資料訓練得到的,本站曾介紹過不少用於輔助和改進LLM訓練流程的方法和技術。而今天,我們要分享的是一篇深入技術底層的文章,介紹如何將一堆連作業系統也沒有的「裸機」變成用來訓練LLM的電腦叢集。這篇文章來自於AI新創公司Imbue,該公司致力於透過理解機器的思維方式來實現通用智慧。當然,將一堆連作業系統也沒有的「裸機」變成用於訓練LLM的電腦叢集並不是一個輕鬆的過程,充滿了探索和試錯,但Imbue最終成功訓練了一個700億參數的LLM,並在此過程中積累
 PyCharm社群版安裝指南:快速掌握全部步驟
Jan 27, 2024 am 09:10 AM
PyCharm社群版安裝指南:快速掌握全部步驟
Jan 27, 2024 am 09:10 AM
快速入門PyCharm社群版:詳細安裝教學全解析導言:PyCharm是一個功能強大的Python整合開發環境(IDE),它提供了一套全面的工具,可以幫助開發人員更有效率地編寫Python程式碼。本文將詳細介紹如何安裝PyCharm社群版,並提供具體的程式碼範例,幫助初學者快速入門。第一步:下載和安裝PyCharm社群版要使用PyCharm,首先需要從其官方網站上下
 AI在用 | AI製作獨居女孩生活Vlog,3天狂攬萬點讚量
Aug 07, 2024 pm 10:53 PM
AI在用 | AI製作獨居女孩生活Vlog,3天狂攬萬點讚量
Aug 07, 2024 pm 10:53 PM
機器之能報道編輯:楊文以大模型、AIGC為代表的人工智慧浪潮已經在悄悄改變我們生活及工作方式,但絕大部分人依然不知道該如何使用。因此,我們推出了「AI在用」專欄,透過直覺、有趣且簡潔的人工智慧使用案例,來具體介紹AI使用方法,並激發大家思考。我們也歡迎讀者投稿親自實踐的創新用例。影片連結:https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ最近,獨居女孩的生活Vlog在小紅書上走紅。一個插畫風格的動畫,再配上幾句治癒系文案,短短幾天就能輕鬆狂攬上
 技術入門者必看:C語言和Python難易度解析
Mar 22, 2024 am 10:21 AM
技術入門者必看:C語言和Python難易度解析
Mar 22, 2024 am 10:21 AM
標題:技術入門者必看:C語言和Python難易度解析,需要具體程式碼範例在當今數位化時代,程式設計技術已成為一項越來越重要的能力。無論是想要從事軟體開發、數據分析、人工智慧等領域,還是僅僅出於興趣學習編程,選擇一門合適的程式語言是第一步。而在眾多程式語言中,C語言和Python作為兩種廣泛應用的程式語言,各有其特色。本文將對C語言和Python的難易度進行解析
 細數RAG的12個痛點,英偉達高級架構師親授解決方案
Jul 11, 2024 pm 01:53 PM
細數RAG的12個痛點,英偉達高級架構師親授解決方案
Jul 11, 2024 pm 01:53 PM
檢索增強式產生(RAG)是一種使用檢索提升語言模型的技術。具體來說,就是在語言模型生成答案之前,先從廣泛的文檔資料庫中檢索相關信息,然後利用這些信息來引導生成過程。這種技術能大幅提升內容的準確性和相關性,並能有效緩解幻覺問題,提高知識更新的速度,並增強內容生成的可追溯性。 RAG無疑是最令人興奮的人工智慧研究領域之一。有關RAG的更多詳情請參閱本站專欄文章《專補大模型短板的RAG有哪些新進展?這篇綜述講明白了》。但RAG也並非完美,使用者在使用時也常會遭遇一些「痛點」。近日,英偉達生成式AI高階解決
