

AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文的主要作者來自香港大學的資料智慧實驗室 (Data Intelligence Lab)。作者中,第一作者任旭濱和第二作者湯嘉斌都是香港大學資料科學院的一年級博士生,指導老師為 Data Intelligence Lab@HKU 的黃超教授。香港大學資料智慧實驗室致力於人工智慧和資料探勘的相關研究,涵蓋大語言模型、圖神經網路、資訊檢索、推薦系統、時空資料探勘等領域。先前的工作包括了通用圖大語言模型 GraphGPT,HiGPT;智慧城市大語言模型 UrbanGPT;可解釋大語言模型推薦演算法 XRec 等。
在資訊爆炸的當今時代,我們如何從浩如煙海的資料中探尋深層的連結呢?
對此,香港大學、聖母大學等機構的專家學者在圖學習與大型語言模型領域的最新綜述中,為我們揭示了答案。
圖,作為描繪現實世界中各種關係的基礎資料結構,其重要性不言而喻。過去的研究已證明,圖神經網路在圖相關的任務中取得了令人矚目的成果。然而,隨著圖數據應用場景複雜度的不斷提升,圖機器學習的瓶頸問題也越凸顯。近期,大型語言模型在自然語言處理領域大放異彩,其出色的語言理解和總結能力備受矚目。正因如此,將大語言模型與圖學習技術融合,以提升圖學習任務的效能,已成為業界新的研究熱點。
這篇綜述針對當前圖學習領域的關鍵技術挑戰,如模型泛化能力、魯棒性,以及復雜圖數據的理解能力等,進行了深入分析,並展望了未來大模型技術在突破這些"未知邊界" 方面的潛力。

論文地址:https://arxiv.org/abs/2405.08011
計畫地址:https://github.com/HKUGDS/AwesomeLLM4,438%實驗室:https://sites.google.com/view/chaoh/home
該綜述深入回顧了最新應用於圖學習中的LLMs,並提出了一種全新的分類方法,依據框架設計對現有技術進行了系統分類。其詳盡剖析了四種不同的演算法設計思路:一是以圖神經網路為前綴,二是以大語言模型為前綴,三是大語言模型與圖集成,四是僅使用大語言模型。針對每一類別,我們都著重介紹了其中的核心技術方法。此外,該綜述也深入探討了各種框架的優點及其局限性,並指明了未來研究的潛在方向。
在電腦科學領域,圖(Graph)是一種重要的非線性資料結構,它由節點集(V)和邊集(E)構成。每條邊連接一對節點,並可能是有向的(具有明確的起點和終點)或無向的(不指定方向)。特別值得一提的是,文字屬性圖(Text-Attributed Graph, TAG)作為圖的特殊形式,為每個節點分配了一個序列化的文本特徵,如句子,這一特性在大型語言模型時代顯得尤為關鍵。文字屬性圖可以規範地表示為由節點集 V、邊集 E 和文字特徵集 T 組成的三元組,即 G* = (V, E, T)。
圖神經網路(Graph Neural Networks, GNNs)是針對圖結構資料設計的深度學習框架。它透過聚合鄰近節點的資訊來更新節點的嵌入表示。具體來說,GNN 的每一層都會透過特定的函數來更新節點嵌入 h,該函數綜合考慮當前節點的嵌入狀態以及週邊節點的嵌入訊息,從而產生下一層的節點嵌入。
大型語言模型(Large Language Models, LLMs)是一種強大的迴歸模型。近期研究顯示,包含數十億參數的語言模型在解決多種自然語言任務時表現卓越,如翻譯、摘要生成和指令執行,因而被稱為大型語言模型。目前,大多數前緣的 LLMs 都基於採用查詢 - 鍵 - 值(QKV)機制的 Transformer 區塊構建,該機制能高效地在詞元序列中整合資訊。根據注意力的應用方向和訓練方式,語言模型可分為兩大類型:
掩碼語言建模(Masked Language Modeling, MLM)是一種廣受歡迎的 LLMs 預訓練目標。它涉及在序列中選擇性地掩蓋特定的詞元,並訓練模型依據週邊上下文預測這些被掩蓋的詞元。為實現精準預測,模型會綜合考慮被掩蓋詞元的前後文環境。
因果語言建模(Causal Language Modeling, CLM)是另一個主流的 LLMs 預訓練目標。它要求模型根據序列中先前的詞元預測下一個詞元。在此過程中,模型僅依據當前詞元之前的上下文來進行準確的預測。
2 圖學習與大語言模型
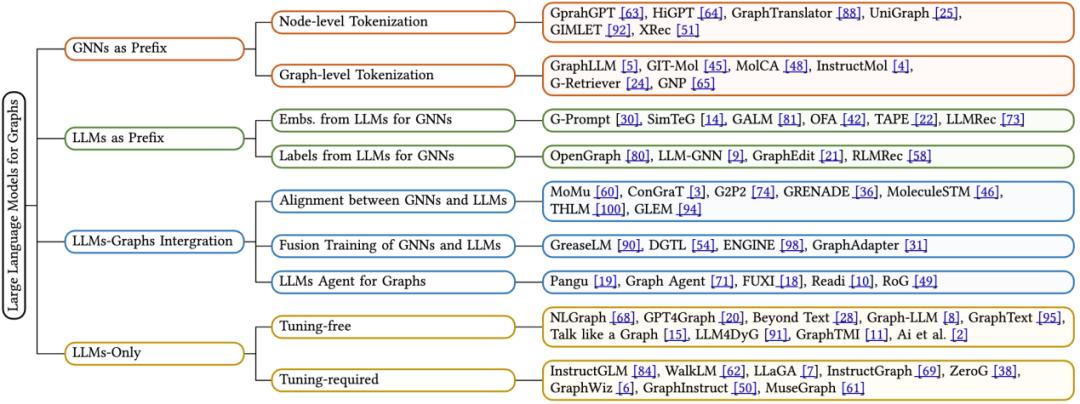
在這篇綜述文章中,作者依據模型的推理流程—— 即圖數據、文本數據的處理方式以及與大型語言模型(LLMs)的互動方式,提出了新的分類方法。具體而言,我們歸納了四種主要的模型架構設計類型,具體如下:
GNNs as Prefix(GNNs 作為前綴):在此類別中,圖神經網路(GNNs)作為首要組件,負責處理圖數據,並為LLMs 提供具有結構感知的標記(如節點級、邊級或圖級標記),以供後續推理使用。
LLMs as Prefix(LLMs 作為前綴):在這一類別中,LLMs 首先處理附帶文字資訊的圖數據,隨後為圖神經網路的訓練提供節點嵌入或產生的標籤。
LLMs-Graphs Integration(LLMs 與圖整合):此類別的方法致力於實現 LLMs 與圖資料之間更為深入的整合,例如透過融合訓練或與 GNNs 的對齊。此外,也建構了基於 LLM 的智能體(agent),以便與圖資訊互動。
LLMs-Only(僅使用 LLMs):此類別設計了實用的提示技巧,將圖結構化資料嵌入到詞元序列中,從而便於 LLMs 進行推斷。同時,部分方法也融合了多模態標記,進一步豐富了模型的處理能力。
2.1 GNNs as Prefix
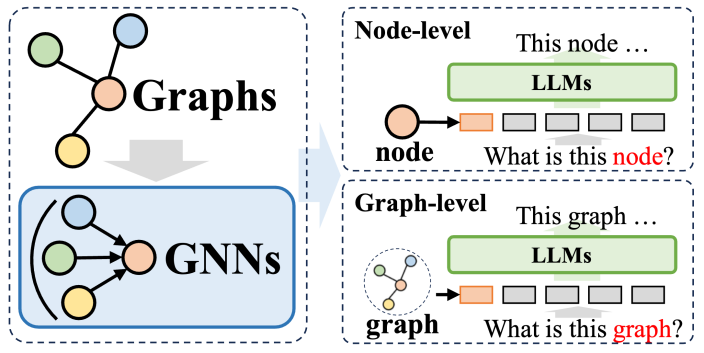
在圖神經網路(GNNs)作為前綴的方法體系中,GNNs 發揮結構編碼圖器的作用,顯著提升了大型語言模型對結構模型(Ms)對結構圖編碼數據的解析能力,從而為多種下游任務帶來益處。這些方法裡,GNNs 主要作為編碼器,負責將複雜的圖資料轉換為包含豐富結構資訊的圖 token 序列,這些序列隨後被輸入到 LLMs 中,與自然語言處理流程相契合。
這些方法大體上可分為兩類:首先是節點級 Token 化,即將圖結構中的每個節點單獨輸入到 LLM 中。這項做法的目的是使 LLM 能夠深入理解細粒度的節點級結構訊息,並準確辨別不同節點間的關聯與差異。其次是圖級 Token 化,它採用特定的池化技術將整個圖壓縮為固定長度的 token 序列,旨在捕捉圖結構的整體高級語義。
對於節點級 Token 化而言,它特別適用於需要建模節點層級精細結構資訊的圖學習任務,如節點分類和連結預測。在這些任務中,模型需要能夠區分不同節點間的細微語意差異。傳統的圖神經網路會根據相鄰節點的資訊為每個節點產生一個獨特的表示,然後基於此進行下游的分類或預測。節點級 Token 化方法能夠最大限度地保留每個節點的特有結構特徵,對下游任務的執行大有裨益。
另一方面,圖級 Token 化則是為了適應那些需要從節點資料中提煉全域資訊的圖級任務。在GNN 作為前綴的框架下,透過各種池化操作,圖級Token 化能夠將眾多節點表示綜合成一個統一的圖表示,這樣不僅能夠捕獲圖的全局語義,還能進一步提升各類下游任務的執行效果。
2.2 LLMs as Prefix
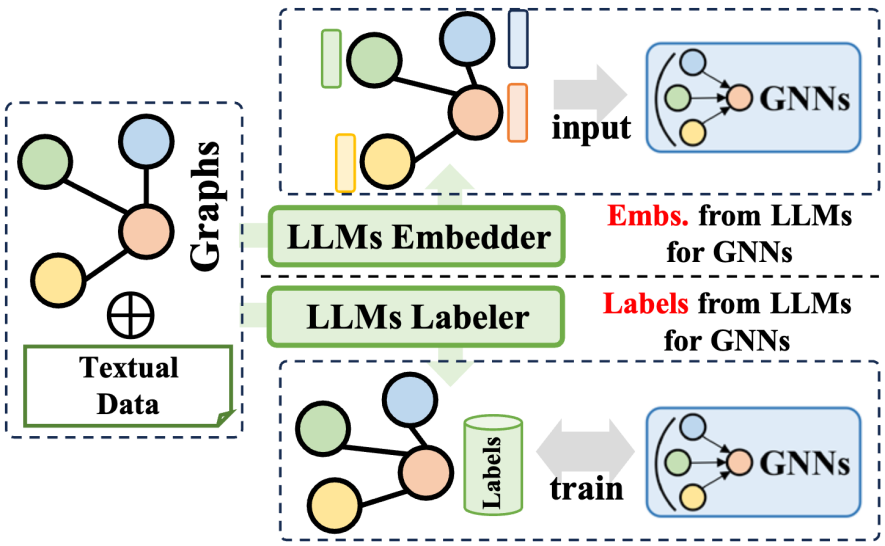
大語言模型(LLMs)前綴法利用大型語言模型產生的豐富資訊來優化圖神經網路(GNNs)的訓練過程。這些資訊涵蓋了文字內容、LLMs 產生的標籤或嵌入等多種數據。根據這些資訊的應用方式,相關技術可分為兩大類:一是利用 LLMs 產生的嵌入來協助 GNNs 的訓練;二是將 LLMs 產生的標籤整合到 GNNs 的訓練流程中。
在利用 LLMs 嵌入方面,GNNs 的推理過程涉及節點嵌入的傳遞與聚合。然而,初始節點嵌入的品質和多樣性在不同領域中差異顯著,例如推薦系統中的 ID 基礎嵌入或引文網絡中的詞袋模型嵌入,可能缺乏清晰度和豐富性。這種嵌入品質的不足有時會限制 GNNs 的性能表現。此外,缺乏通用的節點嵌入設計也影響了 GNNs 在處理不同節點集時的泛化能力。幸運的是,透過借助大型語言模型在語言總結和建模方面的卓越能力,我們可以為 GNNs 產生富有意義和效果的嵌入,從而提升其訓練效果。
在整合 LLMs 標籤方面,另一種策略是將這些標籤作為監督訊號,以增強 GNNs 的訓練效果。值得注意的是,這裡的監督標籤不僅限於傳統的分類標籤,還包括嵌入、圖等多種形式。由 LLMs 產生的資訊並非直接作為 GNNs 的輸入數據,而是構成了更為精細的優化監督訊號,從而幫助 GNNs 在各種圖相關任務上取得更卓越的性能。
2.3 LLMs-Graphs Intergration
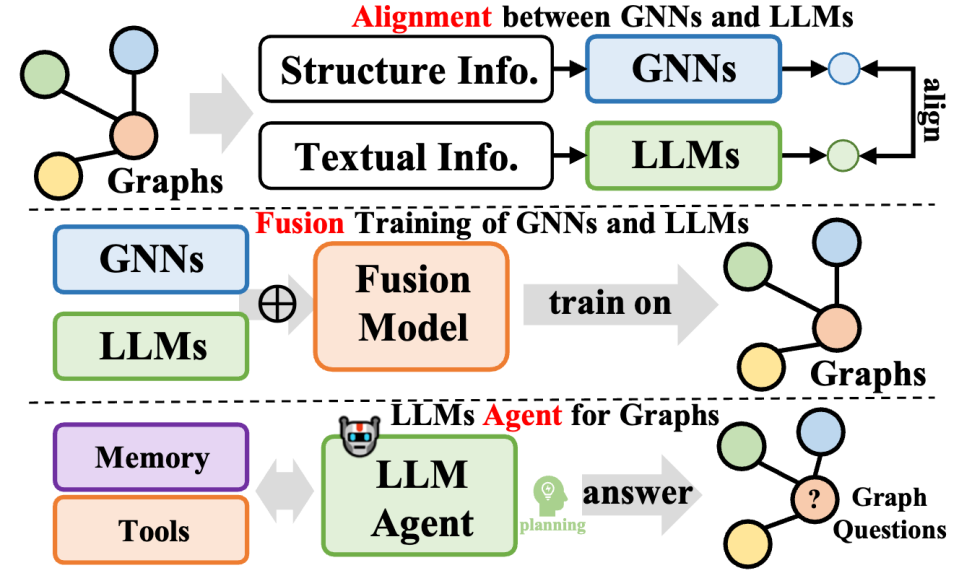
該類方法進一步整合了大型語言模型與圖數據,涵蓋多樣化的方法論,不僅提升了大型語言模型(LLMs)在圖處理任務中的能力,同時也優化了圖神經網路(GNNs)的參數學習。這些方法可歸納為三種:一是GNNs 與LLMs 的融合,旨在實現模型間的深度整合與共同訓練;二是GNNs 與LLMs 之間的對齊,專注於兩種模型在表示或任務層面上的對齊;三是建構基於LLMs 的自主智能體,以規劃和執行圖相關任務。
在 GNNs 與 LLMs 的融合方面,通常 GNNs 專注於處理結構化數據,而 LLMs 則擅長處理文本數據,這導致兩者俱有不同的特徵空間。為了解決這個問題,並促進兩種資料模態對 GNNs 和 LLMs 學習的共同增益,一些方法採用對比學習或期望最大化(EM)迭代訓練等技術,以對齊兩個模型的特徵空間。這種做法提升了圖和文字資訊的建模精確度,從而在各種任務中提高了效能。
關於 GNNs 與 LLMs 的對齊,儘管表示對齊實現了兩個模型的共同優化和嵌入級別的對齊,但在推理階段它們仍是獨立的。為了實現 LLMs 和 GNNs 之間更緊密的集成,一些研究聚焦於設計更深層的模組架構融合,例如將 LLMs 中的變換器層與 GNNs 中的圖神經層結合。透過共同訓練 GNNs 和 LLMs,可以在圖任務中為兩個模組帶來雙向的增益。
最後,在基於LLM 的圖智能體方面,借助LLMs 在指令理解和自我規劃解決問題上的出色能力,新的研究方向是構建基於LLMs 的自主智能體,以處理人類給出的或與研究相關的任務。通常情況下,這樣的智能體包括記憶、知覺和行動三個模組,形成觀察、記憶回憶和行動的循環,用於解決特定任務。在圖論領域,基於 LLMs 的智能體能夠直接與圖資料進行交互,執行如節點分類和連結預測等任務。
2.4 LLMs-Only
該綜述在LLMs-Only 的章節中詳細闡述了直接將大型語言模型(LLMs)應用於各種以圖為導向任務的情況,即所謂的「僅LLMs” 類別。這些方法的目標是讓 LLMs 能夠直接接受圖結構訊息,理解它,並結合這些資訊對各種下游任務進行推理。這些方法主要可以分為兩大類:i)無需微調的方法,旨在設計LLMs 能夠理解的提示,直接促使預訓練的LLMs 執行以圖為導向的任務;ii)需要微調的方法,專注於將圖轉換為特定方式的序列,並透過微調方法對齊圖token 序列和自然語言token 序列。
無需微調的方法:鑑於圖數據獨特的結構特性,出現了兩個關鍵挑戰:一是有效地用自然語言格式構建圖;二是確定大型語言模型(LLMs)是否能夠準確理解以語言形式表示的圖結構。為了解決這些問題,有一部分研究人員開發了無需調整的方法,在純文字空間內對圖進行建模和推理,從而探索預先訓練 LLMs 在增強結構理解方面的潛力。
需要微調的方法:由於使用純文字表達圖結構資訊存在局限性,近期的主流方法是在將圖輸入到大型語言模型(LLMs)時,將圖作為節點token 序列與自然語言token 序列對齊。與前述的GNN 作為前綴的方法不同,需要調整的僅LLM 方法放棄了圖編碼器,轉而採用特定的文本描述來體現圖結構,並且在提示中精心設計了prompts,這在各種下游圖相關任務中取得了有希望的表現。
3 未來的研究方向
該綜述也討論了大型語言模型在圖領域的一些開放問題和潛在的未來研究方向:
多模態圖與大型語言模型(LLMs)的融合。 近期研究顯示,大型語言模型在處理和理解影像、影片等多模態資料方面表現出非凡能力。這項進步為將 LLMs 與包含多種模態特徵的多模態圖資料相結合提供了新的契機。研發能夠處理此類圖資料的多模態 LLMs,將使我們在綜合考慮文本、視覺、聽覺等多種資料類型的基礎上,對圖結構進行更為精確和全面的推理。
提升效率與降低計算成本。 目前,LLMs 的訓練和推理階段涉及的高昂計算成本已成為其發展的重大瓶頸,限制了它們處理包含數百萬節點的大規模圖數據的能力。當嘗試將 LLMs 與圖神經網路(GNNs)結合時,由於兩種強大模型的融合,這項挑戰變得更為嚴峻。因此,亟待發現並實施有效策略,以降低LLMs 和GNNs 的訓練計算成本,這不僅有助於緩解目前面臨的限制,還將進一步拓展LLMs 在圖相關任務中的應用範圍,從而提升它們在數據科學領域的實用價值和影響力。
應對多樣化的圖任務。 目前的研究方法主要集中在傳統的圖相關任務上,例如連結預測和節點分類。但考慮到 LLMs 的強大能力,我們有必要深入探索其在處理更為複雜和生成性任務方面的潛力,如圖生成、圖理解以及基於圖的問題回答等。透過擴展基於 LLM 的方法以涵蓋這些複雜任務,我們將為 LLMs 在不同領域的應用開闢無數新機會。例如,在藥物研發領域,LLMs 可以促進新分子結構的生成;在社交網絡分析領域,它們可以提供對複雜關係模式的深入洞察;在知識圖譜構建方面,LLMs 則有助於創建更加全面且上下文準確的知識庫。
建構使用者友善的圖智能體。 目前,大多數為圖相關任務設計的基於 LLM 的智能體都是針對單一任務量身定制的。這些智能體通常採用單次運行模式,旨在一次解決問題。然而,理想的基於 LLM 的智能體應具備用戶友好性,並且能夠動態地在圖數據中搜尋答案,以響應用戶提出的多樣化開放式問題。為實現這一目標,我們需要開發一個既靈活又穩健的智能體,它能夠與用戶進行迭代交互,並熟練應對圖數據的複雜性,提供準確且相關的答案。這將要求智能體不僅具備高度的適應性,還需展現強大的穩健性。
4 總結
該綜述對圖數據定制的大型語言模型(LLMs)進行了深入探討,並提出了基於模型的推理框架設的分類方法,將不同的模型細緻地劃分為四種各具特色的框架設計。每一種設計都展現出其獨特的優點與限制。不僅如此,該綜述也對這些特性展開了全面的討論,深入探討了每一種框架在應對圖資料處理任務時的潛力和挑戰。此項研究工作旨在為那些熱衷於探索並應用大型語言模型來解決圖相關問題的研究人員提供參考資源,並且希望最終透過這項工作,推動對LLMs 與圖數據結合應用的更深層次理解,進一步催生該領域的技術創新和突破。
以上是KDD 2024|港大黃超團隊深度解析大模型在圖機器學習領域的「未知邊界」的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















