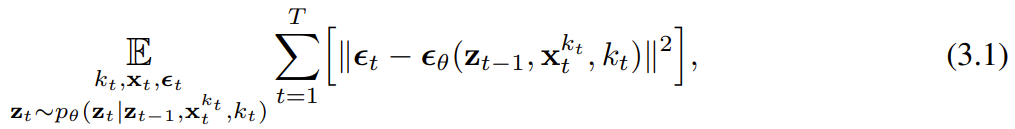當前,採用下一 token 預測範式的自回歸大型語言模型已經風靡全球,同時互聯網上的大量合成圖像和視頻也早已讓我們見識到了擴散模型的強大之處。
近日,MIT CSAIL 的一個研究團隊(一作為MIT 在讀博士陳博遠)成功地將全序列擴散模型與下一token 模型的強大能力統合到了一起,提出了一種訓練和採樣範式:Diffusion Forcing(DF)。
論文標題:Diffusion Forcing:Next-token Prediction Meets Full-Sequence Diffusion
論文地址:https://arxiv.org/pdf/24037. /boyuan.space/diffusion-forcing
代碼位址:https://github.com/buoyancy99/diffusion-forcing
如下所示,擴散強制在一致性和穩定性方面都明顯勝過全序列擴散和教師強制這兩種方法。
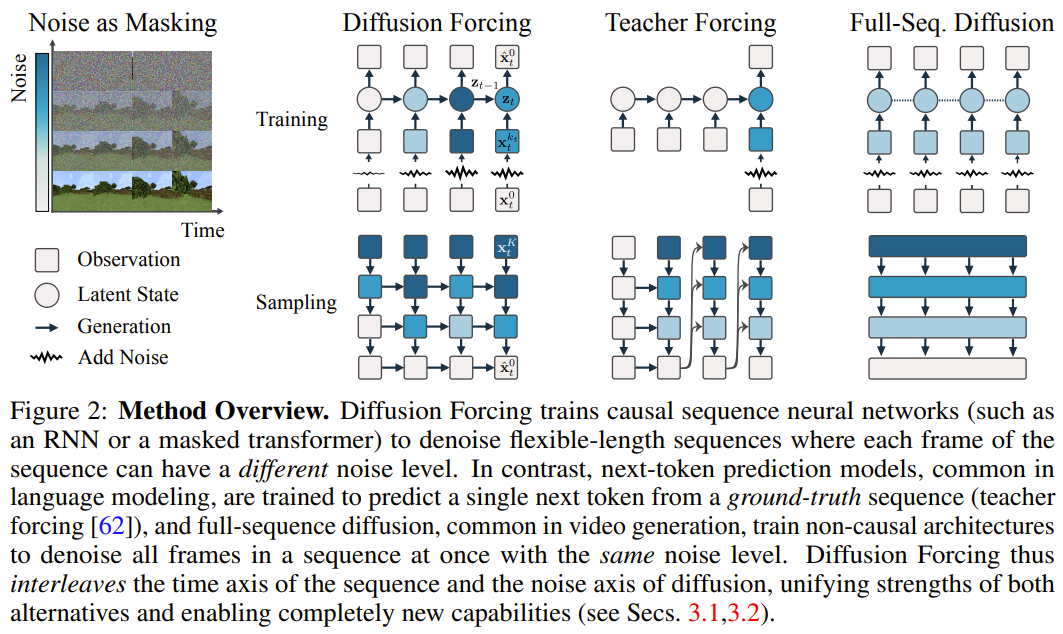
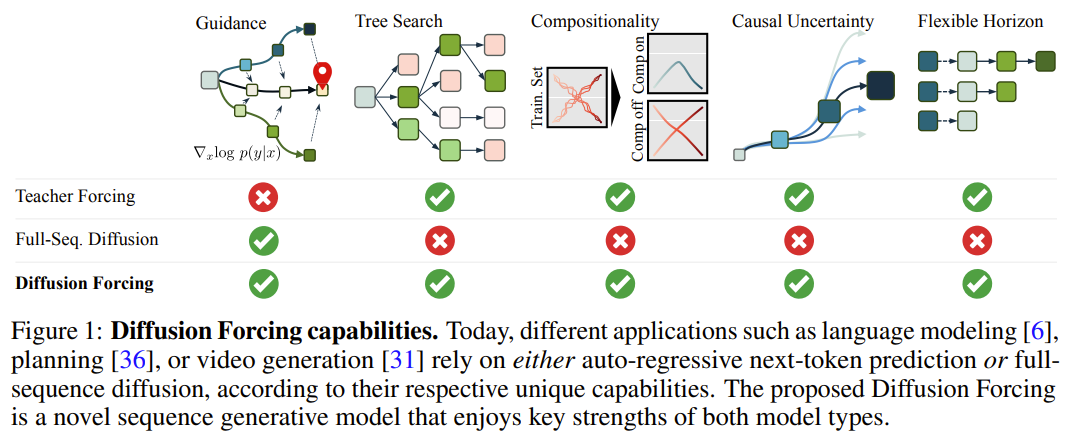
在該框架中,每個token 都關聯了一個隨機的、獨立的噪聲水平,並且可使用共享的下一token 預測模型或下幾token 預測模型根據任意的、獨立的、每token 的方案對token 進行去雜訊。 此方法的研究靈感來自這一觀察:token 加噪聲的過程就是一種形式的部分掩碼過程—— 零噪聲就意味著未對token 加掩碼,而完整噪聲則是完全掩蔽token。因此,DF 可強迫模型學習去除任何可變有雜訊 token 集合的遮罩(圖 2)。 同時,透過將預測方法參數化為多個下一token 預測模型的組合,該系統可以靈活地產生不同長度的序列,並以組合方式泛化到新的軌跡(圖1 )。 該團隊將用於序列生成的 DF 實現成了因果擴散強制(Causal Diffusion Forcing/CDF),其中未來 token 透過一個因果架構依賴於過去 token。他們訓練模型一次性去噪序列的所有 token(其中每個 token 都有獨立的雜訊等級)。 在採樣期間,CDF 會將一個高斯噪聲幀序列逐漸地去噪成潔淨的樣本,其中不同幀在每個去噪步驟可能會有不同的噪聲水平。類似於下一token 預測模型,CDF 可以產生長度可變的序列;不同於下一token 預測,CDF 的表現非常穩定—— 不管是預測接下來的一個token,還是未來的數千token,甚至是連續token。 此外,類似於全序列擴散,它也可接收引導,從而實現高獎勵生成。透過協同利用因果關係、靈活的範圍和可變噪音調度,CDF 能實現一項新功能:蒙特卡羅樹引導(MCTG)。相較於非因果全序列擴散模型,MCTG 能大幅提升高獎勵產生的取樣率。圖 1 給出了這些能力的概況。 。一個透過t 索引的有序集合。那麼,使用教師強制(teacher forcing)訓練下一 token 預測便可被解釋成掩蔽掉時間 t 的每個 token x_t 基於過去 x_{1:t−1} 預測它們。
對於序列,可將此操作描述成:沿時間軸執行遮罩。我們可以將全序列前向擴散(即逐漸向資料
添加雜訊的過程)看作一種部分遮罩(partial masking),這可稱為「沿著雜訊軸執行遮罩)。事實上,在K 步加噪之後,
(大概)就是白噪聲了,不再有任何有關原始數據的信息。這兩個軸的遮罩。的關鍵在於每個token 的噪音水平k_t 會隨時間步驟而變化。因果擴散強制(CDF)。會透過一個循環層根據動態而演化。当获得输入噪声观察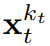 时,就以马尔可夫方式更新该隐藏状态。当 k_t=0 时,这就是贝叶斯过滤中的后验更新;而当 k_t= K(纯噪声、无信息)时,这就等价于建模贝叶斯过滤中的「后验分布」p_θ(z_t | z_{t−1})。给定隐藏状态 z_t,观察模型 p_θ(x_t^0 | z_t) 的目标是预测 x_t;这个单元的输入 - 输出行为与标准的条件扩散模型一样:以条件变量 z_{t−1} 和有噪声 token 为输入,预测无噪声的 x_t=x_t^0,并由此间接地通过仿射重新参数化预测噪声 ε^{k_t}。因此,我们就可以直接使用经典的扩散目标来训练(因果)扩散强制。根据噪声预测结果 ε_θ,可以对上述单元进行参数化。然后,通过最小化以下损失来找到参数 θ:算法 1 给出了伪代码。重点在于,该损失捕获了贝叶斯过滤和条件扩散的关键元素。该团队也进一步重新推断了用于扩散强制的扩散模型训练中的常用技术,详见原论文的附录部分。他们也得出了一个非正式的定理。定理 3.1(非正式)。扩散强制训练流程(算法 1)是在期望对数似然
时,就以马尔可夫方式更新该隐藏状态。当 k_t=0 时,这就是贝叶斯过滤中的后验更新;而当 k_t= K(纯噪声、无信息)时,这就等价于建模贝叶斯过滤中的「后验分布」p_θ(z_t | z_{t−1})。给定隐藏状态 z_t,观察模型 p_θ(x_t^0 | z_t) 的目标是预测 x_t;这个单元的输入 - 输出行为与标准的条件扩散模型一样:以条件变量 z_{t−1} 和有噪声 token 为输入,预测无噪声的 x_t=x_t^0,并由此间接地通过仿射重新参数化预测噪声 ε^{k_t}。因此,我们就可以直接使用经典的扩散目标来训练(因果)扩散强制。根据噪声预测结果 ε_θ,可以对上述单元进行参数化。然后,通过最小化以下损失来找到参数 θ:算法 1 给出了伪代码。重点在于,该损失捕获了贝叶斯过滤和条件扩散的关键元素。该团队也进一步重新推断了用于扩散强制的扩散模型训练中的常用技术,详见原论文的附录部分。他们也得出了一个非正式的定理。定理 3.1(非正式)。扩散强制训练流程(算法 1)是在期望对数似然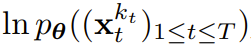 上优化证据下限(ELBO)的重新加权,其中期望值会在噪声水平上平均,而
上优化证据下限(ELBO)的重新加权,其中期望值会在噪声水平上平均,而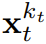 是根据前向过程加噪。此外,在适当条件下,优化 (3.1) 式还可以同时最大化所有噪声水平序列的似然下限。算法 2 描述了采样过程,其定义是:在二维的 M × T 网格 K ∈ [K]^{M×T} 上指定噪声调度;其中列对应于时间步骤 t,m 索引的行则决定了噪声水平。为了生成长度为 T 的整个序列,先将 token x_{1:T} 初始化为白噪声,对应于噪声水平 k = K。然后沿着网格逐行向下迭代,并从左到右逐列去噪,直到噪声水平达到 K。到最后一行 m = 0 时,token 的噪声已清理干净,即噪声水平为 K_{0,t} ≡ 0。
是根据前向过程加噪。此外,在适当条件下,优化 (3.1) 式还可以同时最大化所有噪声水平序列的似然下限。算法 2 描述了采样过程,其定义是:在二维的 M × T 网格 K ∈ [K]^{M×T} 上指定噪声调度;其中列对应于时间步骤 t,m 索引的行则决定了噪声水平。为了生成长度为 T 的整个序列,先将 token x_{1:T} 初始化为白噪声,对应于噪声水平 k = K。然后沿着网格逐行向下迭代,并从左到右逐列去噪,直到噪声水平达到 K。到最后一行 m = 0 时,token 的噪声已清理干净,即噪声水平为 K_{0,t} ≡ 0。
扩散强制的新能力也带来了新的可能性。该团队基于此为序列决策(SDM)设计了一种全新框架,并且将其成功应用到了机器人和自主智能体领域。首先,定义一个马尔可夫决策过程,该过程具有动态 p (s_{t+1}|s_t, a_t)、观察 p (o_t|s_t) 和奖励 p (r_t|s_t, a_t)。这里的目标是训练一个策略 π(a_t|o_{1:t}),使得轨迹 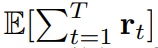 的预期累积奖励最大化。这里分配 token x_t = [a_t, r_t, o_{t+1}]。一条轨迹就是一个序列 x_{1:T},其长度可能是可变的;训练方式则如算法 1 所示。在执行过程的每一步 t,都有一个隐藏状态 z_{t-1} 总结过去的无噪声 token x_{1:t-1}。基于这个隐藏状态,根据算法 2 采样一个规划
的预期累积奖励最大化。这里分配 token x_t = [a_t, r_t, o_{t+1}]。一条轨迹就是一个序列 x_{1:T},其长度可能是可变的;训练方式则如算法 1 所示。在执行过程的每一步 t,都有一个隐藏状态 z_{t-1} 总结过去的无噪声 token x_{1:t-1}。基于这个隐藏状态,根据算法 2 采样一个规划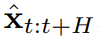 ,其中
,其中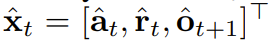 包含预测的动作、奖励和观察。H 是一个前向观察窗口,类似于模型预测控制中的未来预测。在采用了规划的动作之后,环境会得到一个奖励和下一个观察,从而得到下一个 token。其中隐藏状态可以根据后验 p_θ(z_t|z_{t−1}, x_t, 0) 获得更新。该框架既可以作为策略,也可以作为规划器,其优势包括:
包含预测的动作、奖励和观察。H 是一个前向观察窗口,类似于模型预测控制中的未来预测。在采用了规划的动作之后,环境会得到一个奖励和下一个观察,从而得到下一个 token。其中隐藏状态可以根据后验 p_θ(z_t|z_{t−1}, x_t, 0) 获得更新。该框架既可以作为策略,也可以作为规划器,其优势包括:
- 能实现蒙特卡洛树引导(MCTG),从而实现未来不确定性
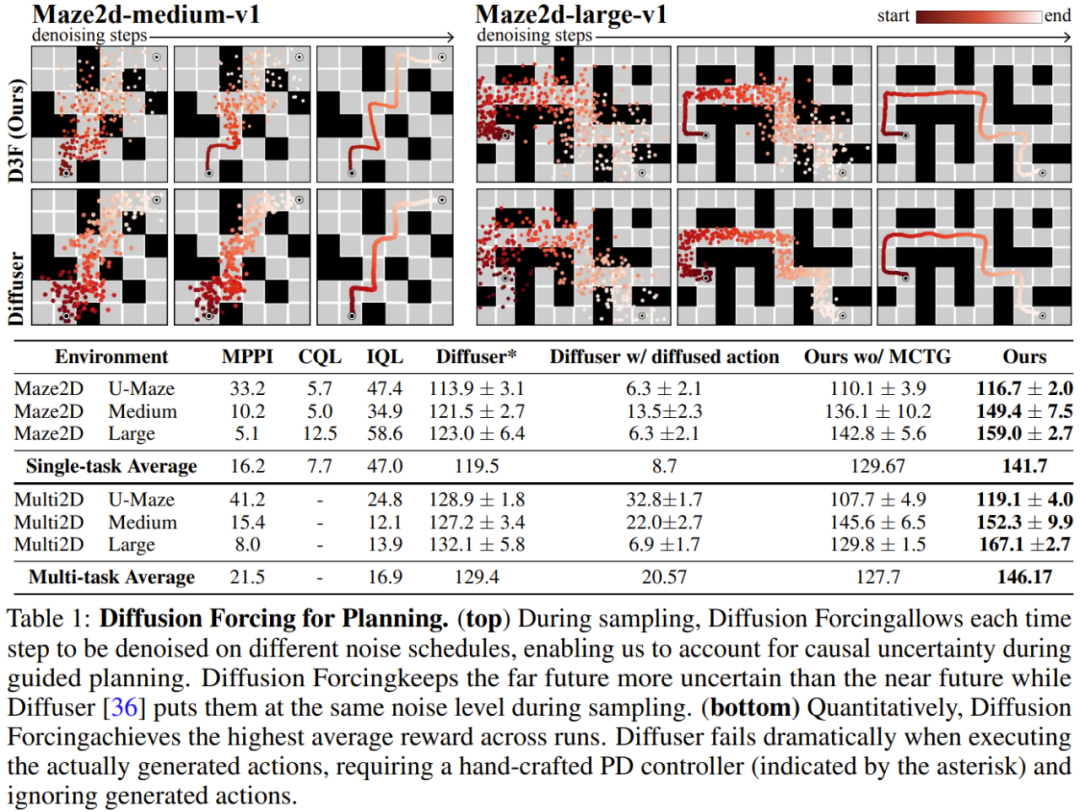
该团队评估了扩散强制作为生成序列模型的优势,其中涉及视频和时间序列预测、规划和模仿学习等多种应用。针对视频生成式建模任务,他们基于 Minecraft 游戏视频和 DMLab 导航为因果扩散强制训练了一个卷积 RNN 实现。可以看到,扩散强制能稳定地展开,甚至能超过其训练范围;而教师强制和全序列扩散基准会很快发散。扩散强制的能力能为决策带来独有的好处。该团队使用一种标准的离线强化学习框架 D4RL 评估了新提出的决策框架。表 1 给出了定性和定量的评估结果。可以看到,扩散强制在全部 6 个环境中都优于 Diffuser 和所有基准。该团队发现,仅需修改采样方案,就可以灵活地组合训练时间观察到的序列的子序列。他们使用一个 2D 轨迹数据集进行了实验:在一个方形平面上,所有轨迹都是始于一角并最终到达对角,形成一种十字形。如上图 1 所示,当不需要组合行为时,可让 DF 保持完整记忆,复制十字形的分布。当需要组合时,可让模型使用 MPC 无记忆地生成更短的规划,从而实现对这个十字形的子轨迹的缝合,得到 V 形轨迹。扩散强制也为真实机器人的视觉运动控制带来了新的机会。模仿学习是一种常用的机器人操控技术,即学习专家演示的观察到动作的映射。但是,缺乏记忆往往会让模仿学习难以完成长范围的任务。DF 不仅能缓解这个短板,还能让模仿学习更稳健。使用记忆进行模仿学习。通过遥控 Franka 机器人,该团队收集了一个视频和动作数据集。如图 4 所示,任务就是利用第三个位置交换苹果和橘子的位置。水果的初始位置是随机的,因此可能的目标状态有两个。此外,当第三个位置有一个水果时,就无法通过当前观察推断出所需结果 —— 策略必须记住初始配置才能决定移动哪个水果。不同于常用的行为克隆方法,DF 可以自然地将记忆整合进自己的隐藏状态中。结果发现,DF 能实现 80% 的成功率,而扩散策略(当前最佳的无记忆模仿学习算法)却失败了。 此外,DF 还能更稳健地应对噪声并助益机器人预训练。对于多变量时间序列预测任务,该团队的研究表明 DF 足以与之前的扩散模型和基于 Transformer 的模型媲美。
此外,DF 还能更稳健地应对噪声并助益机器人预训练。对于多变量时间序列预测任务,该团队的研究表明 DF 足以与之前的扩散模型和基于 Transformer 的模型媲美。以上是無限生成視頻,還能規劃決策,擴散強制整合下一token預測與全序列擴散的詳細內容。更多資訊請關注PHP中文網其他相關文章!