

GoogleAI拿下IMO奧數銀牌,數學推理模型AlphaProof面世,強化學習 is so back

對 AI 來說,奧數不再是問題了。
本週四,Google DeepMind 的人工智慧完成了一項壯舉:用 AI 做出了今年國際數學奧林匹克競賽 IMO 的真題,並且距拿金牌僅一步之遙。

上週剛結束的 IMO 競賽共有六道賽題,涉及代數、組合學、幾何和數論。谷歌提出的混合 AI 系統做對了四道,獲得 28 分,達到了銀牌水準。
本月初,UCLA 終身教授陶哲軒剛剛宣傳了百萬美元獎金的 AI 數學奧林匹克競賽(AIMO 進步獎),沒想到 7 月還沒過,AI 的做題水平就進步到了這種水平。
IMO 上同步做題,做對了最難題
IMO 是歷史最悠久、規模最大、最負盛名的青年數學家競賽,自 1959 年以來每年舉辦一次。近來,IMO 競賽也被廣泛認為是機器學習領域的重大挑戰,成為衡量人工智慧系統高階數學推理能力的理想基準。
在今年的 IMO 競賽上,由 DeepMind 團隊研發的 AlphaProof 和 AlphaGeometry 2 共同實現了里程碑式的突破。
其中,AlphaProof 是一種用於形式化數學推理的強化學習系統,而 AlphaGeometry 2 是 DeepMind 幾何求解系統 AlphaGeometry 的改進版本。
這項突破顯示具有先進數學推理能力的通用人工智慧 (AGI) 有潛力開啟科學技術新領域。
那麼,DeepMind 的 AI 系統是如何參加 IMO 競賽的呢?
簡單來說,首先這些數學問題被手動翻譯成形式化的數學語言,以便 AI 系統理解。在正式比賽中,人類參賽者分兩節(兩天)提交答案,每節限時 4.5 小時。 AlphaProof+AlphaGeometry 2 組合成的 AI 系統在幾分鐘內就解決了一個問題,但花了三天時間來解決其他問題。雖然如果嚴格按照規則來說的話,DeepMind 的系統超時了。有人推測,這裡面可能涉及大量的暴力破解。

谷歌表示,AlphaProof 透過確定答案並證明其正確性解決了兩道代數問題和一道數論問題。其中包括本次競賽中最難的問題,在今年的 IMO 上只有五位參賽者解決了。而 AlphaGeometry 2 證明了一個幾何問題。
AI 給出的解:https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/imo-2024-solutions/index.html
IMO 金牌得主、菲爾茲獎得主Timothy Gowers和兩屆IMO 金牌得主、IMO 2024 問題選擇委員會主席Joseph Myers 博士根據IMO 評分規則,對該組合系統給出的解決方案進行了評分。
六個問題中的每一個問題滿分 7 分,總分最高 42 分。 DeepMind 的系統最終得分為 28 分,意味著解決的 4 個問題都獲得了滿分——相當於銀牌類別的最高分。今年的金牌門檻為 29 分,正式比賽的 609 名選手中有 58 人獲得了金牌。
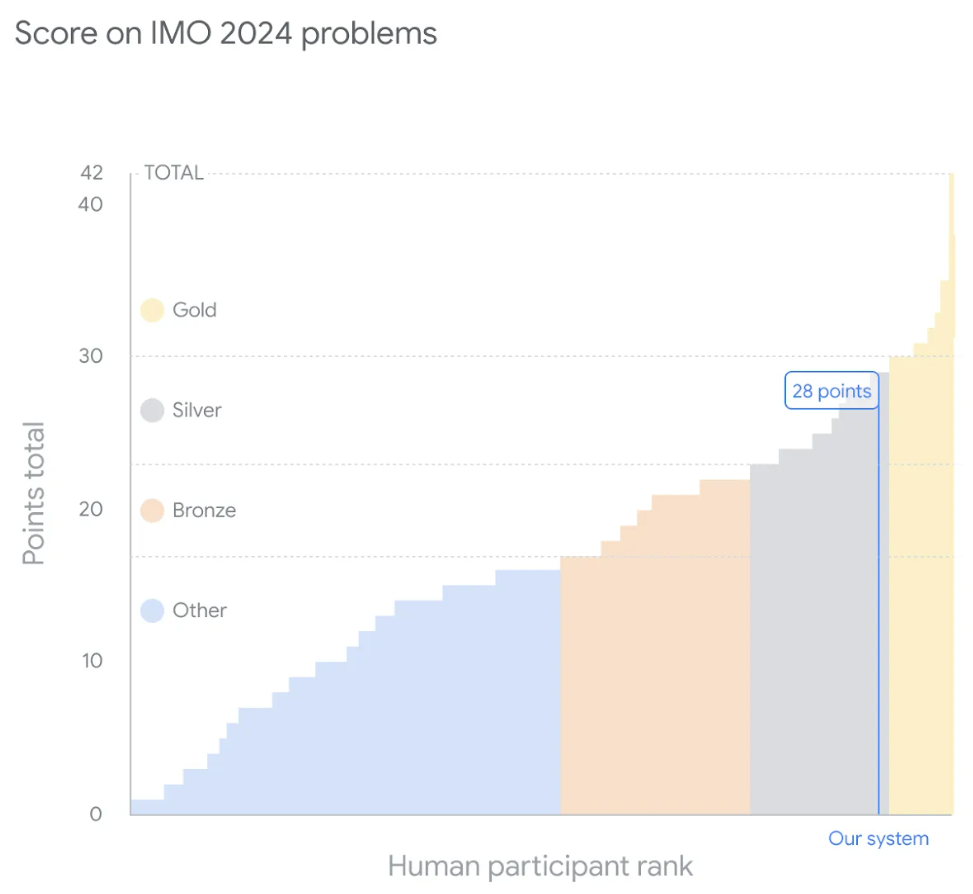
該圖顯示了谷歌 DeepMind 的人工智慧系統在 IMO 2024 上相對於人類競爭對手的表現。在總分為 42 分的情況下,該系統獲得了 28 分,達到了與比賽銀牌得主相同的水平。另外,今年 29 分是能拿金牌的。
AlphaProof:一種形式化推理方法
在谷歌使用的混合 AI 系統中,AlphaProofan 來證明數學語言
在谷歌使用的混合 AI 系統中,AlphaProofan 來證明數學語言它結合了預訓練語言模型與 AlphaZero 強化學習演算法。
其中,形式語言為形式化地驗證數學推理證明的正確性,提供了重要優勢。在此之前,這在機器學習中的使用一直受限,因為人工編寫資料數量非常有限。
相較之下,基於自然語言的方法儘管可以存取更多量級的數據,但會產生看似合理而不正確的中間推理步驟與解法。
谷歌 DeepMind 透過微調 Gemini 模型自動將自然語言問題陳述翻譯為形式陳述,在這兩個互補領域之間建立了一座橋樑,從而創建了一個包含不同難度形式問題的大型庫。
🎜給到數學問題,AlphaProof 會產生候選解題方案,然後透過搜尋 Lean 中可能的證明步驟來證明它們。找到並驗證的每個證明方案,都用來強化 AlphaProof 的語言模型,增強其解決後續更具挑戰性問題的能力。 🎜Untuk melatih AlphaProof, Google DeepMind telah membuktikan atau menafikan berjuta-juta masalah matematik yang merangkumi pelbagai kesukaran dan topik dalam minggu-minggu menjelang pertandingan IMO. Gelung latihan juga digunakan semasa pertandingan untuk mengukuhkan bukti varian masalah persaingan yang dijana sendiri sehingga penyelesaian lengkap ditemui.
 Infografik proses latihan pembelajaran pengukuhan AlphaProof: Kira-kira satu juta masalah matematik tidak formal diterjemahkan ke dalam bahasa matematik formal oleh rangkaian formal. Penyelesai kemudian mencari rangkaian untuk bukti atau penolakan masalah, secara beransur-ansur melatih dirinya sendiri untuk menyelesaikan masalah yang lebih mencabar melalui algoritma AlphaZero.
Infografik proses latihan pembelajaran pengukuhan AlphaProof: Kira-kira satu juta masalah matematik tidak formal diterjemahkan ke dalam bahasa matematik formal oleh rangkaian formal. Penyelesai kemudian mencari rangkaian untuk bukti atau penolakan masalah, secara beransur-ansur melatih dirinya sendiri untuk menyelesaikan masalah yang lebih mencabar melalui algoritma AlphaZero.
AlphaGeometry 2 yang lebih kompetitif
AlphaGeometry 2 ialah versi AI matematik AlphaGeometry yang dipertingkatkan dengan ketara yang dipaparkan dalam majalah Nature tahun ini. Ia adalah sistem hibrid neuro-simbolik di mana model bahasa adalah berdasarkan Gemini dan dilatih dari awal pada urutan magnitud lebih banyak data sintetik daripada pendahulunya. Ini membantu model menyelesaikan masalah geometri yang lebih mencabar, termasuk masalah pergerakan objek dan persamaan sudut, perkadaran atau jarak.
AlphaGeometry 2 menggunakan enjin simbolik yang dua urutan magnitud lebih pantas daripada generasi sebelumnya. Apabila masalah baharu dihadapi, mekanisme perkongsian pengetahuan baharu membolehkan gabungan lanjutan pepohon carian berbeza untuk menyelesaikan masalah yang lebih kompleks.
Sebelum pertandingan tahun ini, AlphaGeometry 2 boleh menyelesaikan 83% daripada semua masalah geometri IMO sejarah sejak 25 tahun lalu, berbanding kadar penyelesaian 53% pendahulunya. Dalam IMO 2024, AlphaGeometry 2 menyelesaikan Masalah 4 dalam masa 19 saat selepas menerima pemformalannya.
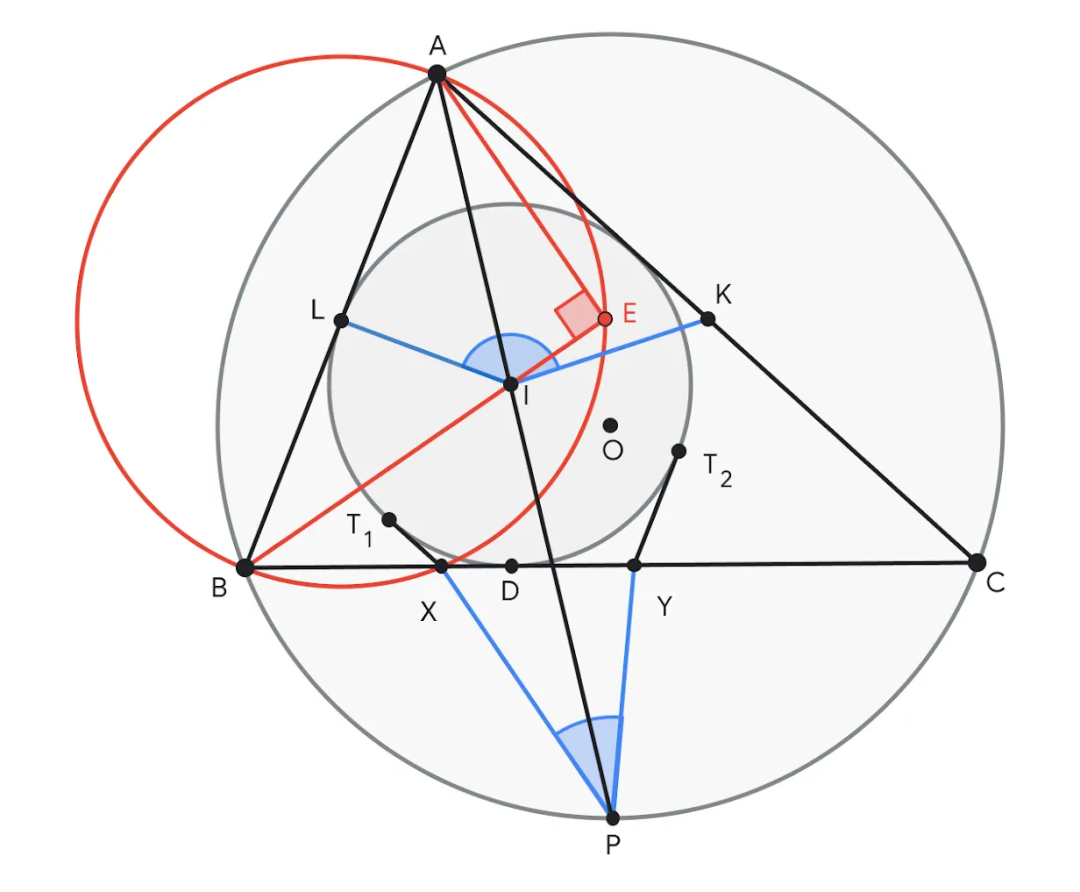
Contoh soalan 4, meminta untuk membuktikan bahawa jumlah ∠KIL dan ∠XPY adalah sama dengan 180°. AlphaGeometry 2 bercadang untuk membina titik E pada garis BI supaya ∠AEB = 90°. Titik E membantu memberi makna kepada titik tengah L segmen garis AB dengan itu mewujudkan banyak pasangan segi tiga yang serupa seperti ABE ~ YBI dan ALE ~ IPC untuk membuktikan kesimpulannya.
Google DeepMind juga melaporkan bahawa sebagai sebahagian daripada kerja IMO, para penyelidik juga sedang bereksperimen dengan sistem penaakulan bahasa semula jadi yang terkini berdasarkan Gemini, dengan harapan untuk mencapai keupayaan menyelesaikan masalah yang lebih maju. Sistem ini tidak memerlukan terjemahan soalan ke dalam bahasa formal dan boleh digabungkan dengan sistem AI yang lain. Dalam ujian soalan pertandingan IMO tahun ini, ia "menunjukkan potensi besar."
Google terus meneroka kaedah AI untuk memajukan penaakulan matematik dan merancang untuk mengeluarkan lebih banyak butiran teknikal tentang AlphaProof tidak lama lagi.
Kami teruja dengan masa depan di mana ahli matematik akan menggunakan alatan AI untuk meneroka hipotesis, mencuba cara baharu yang berani untuk menyelesaikan masalah yang telah lama wujud, dan dengan cepat menyelesaikan elemen bukti yang memakan masa—dan sistem AI seperti Gemini akan merevolusikan matematik dan penaakulan yang lebih luas aspek menjadi lebih berkuasa.
Pasukan penyelidik
Google berkata bahawa penyelidikan baharu itu disokong oleh International Mathematical Olympiad Organization Selain itu:
Pembangunan AlphaProof diketuai oleh Thomas Hubert, Rishi Mehta dan Laurent Sartran, termasuk Hussain Masoom; Aja Huang, Miklós Z. Horváth, Tom Zahavy, Vivek Veeriah, Eric Wieser, Jessica Yung, Lei Yu, Yannick Schroecker, Julian Schrittwieser, Ottavia Bertolli, Borja Ibarz, Edward Lockhart, Edward Hughes, Mark Rowland dan Grace Margand.
Antaranya, Aja Huang, Julian Schrittwieser, Yannick Schroecker dan ahli lain juga merupakan ahli teras kertas AlphaGo 8 tahun lalu (2016). Lapan tahun lalu, AlphaGo mereka, berdasarkan pembelajaran pengukuhan, menjadi terkenal. Lapan tahun kemudian, pembelajaran pengukuhan kembali bersinar dengan AlphaProof. Seseorang mengeluh dalam kalangan rakan-rakan: RL sangat kembali!

AlphaGeometry 2 dan kerja inferens bahasa semula jadi diketuai oleh Thang Luong. Pembangunan AlphaGeometry 2 diketuai oleh Trieu Trinh dan Yuri Chervonyi, dengan sumbangan penting daripada Mirek Olšák, Xiaomeng Yang, Hoang Nguyen, Junehyuk Jung, Dawsen Hwang dan Marcelo Menegali.
Selain itu, David Silver, Quoc Le, Hassabis dan Pushmeet Kohli bertanggungjawab untuk menyelaras dan mengurus keseluruhan projek.
Kandungan rujukan:
https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/
以上是GoogleAI拿下IMO奧數銀牌,數學推理模型AlphaProof面世,強化學習 is so back的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 突破傳統缺陷檢測的界限,\'Defect Spectrum\'首次實現超高精度豐富語意的工業缺陷檢測。
Jul 26, 2024 pm 05:38 PM
突破傳統缺陷檢測的界限,\'Defect Spectrum\'首次實現超高精度豐富語意的工業缺陷檢測。
Jul 26, 2024 pm 05:38 PM
在現代製造業中,精準的缺陷檢測不僅是確保產品品質的關鍵,更是提升生產效率的核心。然而,現有的缺陷檢測資料集常常缺乏實際應用所需的精確度和語意豐富性,導致模型無法辨識特定的缺陷類別或位置。為了解決這個難題,由香港科技大學廣州和思謀科技組成的頂尖研究團隊,創新地開發了「DefectSpectrum」資料集,為工業缺陷提供了詳盡、語義豐富的大規模標註。如表一所示,相較於其他工業資料集,「DefectSpectrum」資料集提供了最多的缺陷標註(5438張缺陷樣本),最細緻的缺陷分類(125個缺陷類別
 數百萬晶體資料訓練,解決晶體學相位問題,深度學習方法PhAI登Science
Aug 08, 2024 pm 09:22 PM
數百萬晶體資料訓練,解決晶體學相位問題,深度學習方法PhAI登Science
Aug 08, 2024 pm 09:22 PM
編輯|KX時至今日,晶體學所測定的結構細節和精度,從簡單的金屬到大型膜蛋白,是任何其他方法都無法比擬的。然而,最大的挑戰——所謂的相位問題,仍然是從實驗確定的振幅中檢索相位資訊。丹麥哥本哈根大學研究人員,開發了一種解決晶體相問題的深度學習方法PhAI,利用數百萬人工晶體結構及其相應的合成衍射數據訓練的深度學習神經網絡,可以產生準確的電子密度圖。研究表明,這種基於深度學習的從頭算結構解決方案方法,可以以僅2埃的分辨率解決相位問題,該分辨率僅相當於原子分辨率可用數據的10%到20%,而傳統的從頭算方
 英偉達對話模式ChatQA進化到2.0版本,上下文長度提到128K
Jul 26, 2024 am 08:40 AM
英偉達對話模式ChatQA進化到2.0版本,上下文長度提到128K
Jul 26, 2024 am 08:40 AM
開放LLM社群正是百花齊放、競相爭鳴的時代,你能看到Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1等許多表現優良的模型。但是,相較於以GPT-4-Turbo為代表的專有大模型,開放模型在許多領域仍有明顯差距。在通用模型之外,也有一些專精關鍵領域的開放模型已被開發出來,例如用於程式設計和數學的DeepSeek-Coder-V2、用於視覺-語言任務的InternVL
 GoogleAI拿下IMO奧數銀牌,數學推理模型AlphaProof面世,強化學習 is so back
Jul 26, 2024 pm 02:40 PM
GoogleAI拿下IMO奧數銀牌,數學推理模型AlphaProof面世,強化學習 is so back
Jul 26, 2024 pm 02:40 PM
對AI來說,奧數不再是問題了。本週四,GoogleDeepMind的人工智慧完成了一項壯舉:用AI做出了今年國際數學奧林匹克競賽IMO的真題,並且距拿金牌僅一步之遙。上週剛結束的IMO競賽共有六道賽題,涉及代數、組合學、幾何和數論。谷歌提出的混合AI系統做對了四道,獲得28分,達到了銀牌水準。本月初,UCLA終身教授陶哲軒剛剛宣傳了百萬美元獎金的AI數學奧林匹克競賽(AIMO進步獎),沒想到7月還沒過,AI的做題水平就進步到了這種水平。 IMO上同步做題,做對了最難題IMO是歷史最悠久、規模最大、最負
 PRO | 為什麼基於 MoE 的大模型更值得關注?
Aug 07, 2024 pm 07:08 PM
PRO | 為什麼基於 MoE 的大模型更值得關注?
Aug 07, 2024 pm 07:08 PM
2023年,幾乎AI的每個領域都在以前所未有的速度進化,同時,AI也不斷地推動著具身智慧、自動駕駛等關鍵賽道的技術邊界。在多模態趨勢下,Transformer作為AI大模型主流架構的局面是否會撼動?為何探索基於MoE(專家混合)架構的大模型成為業界新趨勢?大型視覺模型(LVM)能否成為通用視覺的新突破? ……我們從過去的半年發布的2023年本站PRO會員通訊中,挑選了10份針對以上領域技術趨勢、產業變革進行深入剖析的專題解讀,助您在新的一年裡為大展宏圖做好準備。本篇解讀來自2023年Week50
 為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
編輯|ScienceAI問答(QA)資料集在推動自然語言處理(NLP)研究中發揮著至關重要的作用。高品質QA資料集不僅可以用於微調模型,也可以有效評估大語言模型(LLM)的能力,尤其是針對科學知識的理解和推理能力。儘管目前已有許多科學QA數據集,涵蓋了醫學、化學、生物等領域,但這些數據集仍有一些不足之處。其一,資料形式較為單一,大多數為多項選擇題(multiple-choicequestions),它們易於進行評估,但限制了模型的答案選擇範圍,無法充分測試模型的科學問題解答能力。相比之下,開放式問答
 準確率達60.8%,浙大基於Transformer的化學逆合成預測模型,登Nature子刊
Aug 06, 2024 pm 07:34 PM
準確率達60.8%,浙大基於Transformer的化學逆合成預測模型,登Nature子刊
Aug 06, 2024 pm 07:34 PM
編輯|KX逆合成是藥物發現和有機合成中的關鍵任務,AI越來越多地用於加快這一過程。現有AI方法性能不盡人意,多樣性有限。在實踐中,化學反應通常會引起局部分子變化,反應物和產物之間存在很大重疊。受此啟發,浙江大學侯廷軍團隊提出將單步逆合成預測重新定義為分子串編輯任務,迭代細化目標分子串以產生前驅化合物。並提出了基於編輯的逆合成模型EditRetro,該模型可以實現高品質和多樣化的預測。大量實驗表明,模型在標準基準資料集USPTO-50 K上取得了出色的性能,top-1準確率達到60.8%。
 Nature觀點,人工智慧在醫學上的測試一片混亂,該怎麼做?
Aug 22, 2024 pm 04:37 PM
Nature觀點,人工智慧在醫學上的測試一片混亂,該怎麼做?
Aug 22, 2024 pm 04:37 PM
編輯|ScienceAI基於有限的臨床數據,數百種醫療演算法已被批准。科學家們正在討論由誰來測試這些工具,以及如何最好地進行測試。 DevinSingh在急診室目睹了一名兒科患者因長時間等待救治而心臟驟停,這促使他探索AI在縮短等待時間中的應用。 Singh利用了SickKids急診室的分診數據,與同事們建立了一系列AI模型,用於提供潛在診斷和推薦測試。一項研究表明,這些模型可以加快22.3%的就診速度,將每位需要進行醫學檢查的患者的結果處理速度加快近3小時。然而,人工智慧演算法在研究中的成功只是驗證此
