KAN 在符號表示中領先,但 MLP 仍是多面手。
多層感知器 (Multi-Layer Perceptrons,MLP) ,也被稱為全連接前饋神經網絡,是當今深度學習模型的基本組成部分。 MLP 的重要性無論如何強調都不為過,因為它是機器學習中用於逼近非線性函數的預設方法。 然而,MLP 也存在某些局限性,例如難以解釋學習到的表示,以及難以靈活地擴展網絡規模。 KAN(Kolmogorov–Arnold Networks)的出現,為傳統 MLP 提供了創新的替代方案。此方法在準確性和可解釋性方面優於 MLP,而且,它能以非常少的參數量勝過以更大參數量運行的 MLP。 那麼,問題來了,KAN 、MLP 到底該選哪一種?有人支持 MLP,因為 KAN 只是一個普通的 MLP,根本替代不了,但也有人則認為 KAN 更勝一籌,而目前對兩者的比較也是局限在不同參數或 FLOP 下進行的,實驗結果並不公平。 為了探討 KAN 的潛力,有必要在公平的設定下全面比較 KAN 和 MLP 了。 為此,來自新加坡國立大學的研究者在控制了KAN 和MLP 的參數或FLOP 的情況下,在不同領域的任務中對它們進行訓練和評估,包括符號公式表示、機器學習、電腦視覺、NLP 和音訊處理。在這些公平的設定下,他們發現 KAN 僅在符號公式表示任務中優於 MLP,而 MLP 通常在其他任務中優於 KAN。
- 論文地址:https://arxiv.org/pdf/2407.16674
- 專案標題連結:https://github.com/yu-rp/K MLP: A Fairer Comparison
作者進一步發現,
KAN 在符號公式表示方面的優勢源於其使用的B - 樣條激活函數
。最初,MLP 的整體性能落後於 KAN,但在用 B - 樣條代替 MLP 的激活函數後,其性能達到甚至超過了 KAN。但是,B - 樣條無法進一步提高 MLP 在其他任務(如電腦視覺)上的表現。 作者也發現,
KAN 在連續學習任務中的表現其實並不比 MLP 好
。最初的 KAN 論文使用一系列一維函數比較了 KAN 和 MLP 在連續學習任務中的表現,其中每個後續函數都是前一個函數沿數軸的平移。而本文比較了 KAN 和 MLP 在更標準的類遞增持續學習設定中的表現。在固定的訓練迭代條件下,他們發現 KAN 的遺忘問題比 MLP 更嚴重
KAN、MLP 簡單介紹
KAN 有兩個分支,第一個分支是B 樣條分支,另一個分支是shortcut 分支,即非線性活化與線性變換連接在一起。在官方實作中,shortcut 分支是 SiLU 函數,後面跟著線性變換。令 x 表示一個樣本的特徵向量。那麼,KAN 樣條分支的前向方程式可以寫成:
在原始 KAN 架構中,樣條函數被選為 B 樣條函數。每個 B 樣條函數的參數與其他網路參數一起學習。
對應的,單層 MLP 的前向方程式可以表示為:
該公式與 KAN 中的 B 樣條分支公式具有相同的形式,只是在非線性函數中有所不同。因此,拋開原論文對 KAN 結構的解讀,KAN 也可以看作是一種全連接層。
因而,KAN 和普通 MLP 的差異主要有兩點:
活化函數不同。通常MLP 中的激活函數包括ReLU、GELU 等,沒有可學習的參數,對所有輸入元素都是統一的,而在KAN 中,激活函數是樣條函數,有可學習的參數,並且對於每個輸入元素都是不一樣的。 - 線性和非線性運算的順序。一般に、研究者は MLP を最初に線形変換を実行し、次に非線形変換を実行するものとして概念化しますが、KAN は実際に最初に非線形変換を実行し、次に線形変換を実行します。しかし、ある程度までは、MLP の全結合層を最初は非線形、次に線形として記述することも可能です。
この研究は、KAN と MLP を比較することにより、両者の違いは主に活性化関数であると考えています。したがって、彼らは、活性化関数の違いにより、KAN と MLP が異なるタスクに適しており、その結果、2 つのモデル間に機能的な違いが生じるという仮説を立てました。この仮説を検証するために、研究者らはさまざまなタスクで KAN と MLP のパフォーマンスを比較し、各モデルが適しているタスクを説明しました。公平な比較を保証するために、この研究ではまず、KAN と MLP のパラメータ数と FLOP を計算する式を導き出します。実験プロセスでは、同じ数のパラメータまたは FLOP を制御して、KAN と MLP のパフォーマンスを比較します。的KanとMLPのパラメータ数とFLOP内の制御パラメータ数 


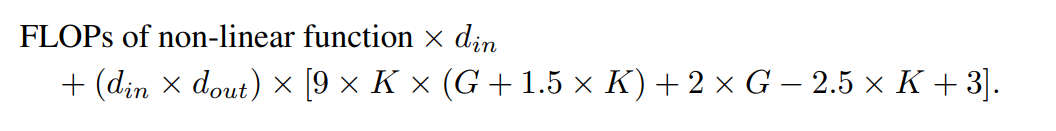

 🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜 🎜 🎜🎜🎜🎜🎜🎜、ショートカット ウェイト、B サイズのウェイト、バイアス用語。学習可能なパラメーターの総数は次のとおりです: 🎜🎜🎜🎜🎜 ここで、d_in と d_out はニューラル ネットワーク層の入力次元と出力次元を表し、K はスプラインの次数を表し、公式 nn.Module のパラメーター k に対応します。 KANLayer。スプライン関数の多項式基底の次数です。 G はスプライン間隔の数を表し、公式の nn.Module KANLayer の num パラメータに対応します。充填前の B スプラインの間隔の数です。埋める前は、制御点の数 - 1 に等しくなります。充填後は、(K +G) 個の有効なコントロール ポイントが存在するはずです。 🎜🎜🎜🎜🎜これに対応して、MLP 層の学習可能なパラメータは次のとおりです: 🎜🎜🎜🎜🎜🎜MLP の 🎜🎜🎜🎜🎜🎜KAN と FLOP🎜🎜🎜🎜🎜🎜 著者の評価では、あらゆる算術演算の FLOP は 1 であると見なされます。ブール演算の FLOP は 0 とみなされます。 De Boor-Cox アルゴリズムの 0 次演算は、浮動小数点演算を必要としない一連のブール演算に変換できます。したがって、理論的には FLOP は 0 です。これは、演算のためにブール データを浮動小数点データに変換する公式の KAN 実装とは異なります。 🎜🎜🎜🎜🎜 筆者の評価では、1つのサンプルに対してFLOPを計算しています。公式 KAN コードで De Boor-Cox 反復公式を使用して実装された B スプライン FLOP は次のとおりです: 🎜🎜🎜🎜🎜 ショートカット パスの FLOP と 2 つの分岐をマージした FLOP を合わせた、KAN 層の合計 FLOP対応して、MLP 層の FLOP は次のようになります。 🎜🎜🎜🎜🎜 同じ入力次元と出力次元を持つ KAN 層と MLP 層の FLOP の差は、次のように表すことができます。 🎜🎜🎜🎜 🎜MLP も最初に非線形演算を実行する場合、先頭項はゼロになります。 🎜🎜🎜🎜🎜🎜 実験 🎜🎜🎜🎜🎜🎜 著者の目標は、パラメータまたは FLOP の数が等しい場合の KAN と MLP のパフォーマンスの違いを比較することです。この実験は、機械学習、コンピューター ビジョン、自然言語処理、音声処理、記号式表現などの複数の分野をカバーしています。すべての実験は Adam オプティマイザーを使用し、すべて RTX3090 GPU で実行されました。 🎜🎜🎜🎜🎜🎜パフォーマンスの比較🎜🎜🎜🎜🎜🎜機械学習。著者らは、1 つまたは 2 つの隠れ層を持つ KAN と MLP を使用して 8 つの機械学習データセットに対して実験を実施し、各データセットの特性に基づいてニューラル ネットワークの入力次元と出力次元を調整しました。 🎜🎜🎜🎜🎜MLPの場合、隠れ層の幅は32、64、128、256、512、または1024に設定され、活性化関数としてGELUまたはReLUが使用され、MLPでは正規化層が使用されます。 KAN の場合、隠れ層の幅は 2、4、8、または 16、B-スプライン メッシュの数は 3、5、10、または 20、B-スプライン次数は 2、3、または 5 です。Since the original KAN architecture does not include a normalization layer, in order to balance the possible advantages of the normalization layer in MLP, the author expanded the value range of the KAN spline function. All experiments were conducted for 20 rounds of training, and the best accuracy achieved on the test set during the training process was recorded, as shown in Figures 2 and 3. On machine learning datasets, MLP usually maintains an advantage. In their experiments on eight datasets, MLP outperformed KAN on six of them. However, they also observed that on one dataset, the performance of MLP and KAN was almost equivalent, while on the other dataset, KAN performed better than MLP. Overall, MLP still has general advantages on machine learning datasets. Computer Vision. The authors conducted experiments on 8 computer vision datasets. They used KANs and MLPs with one or two hidden layers, adjusting the input and output dimensions of the neural network depending on the dataset. In computer vision data sets, the processing bias introduced by KAN ’s spline function has no effect, and its performance is always inferior to MLP with the same number of parameters or FLOPs. Audio and natural language processing. The authors conducted experiments on 2 audio classification and 2 text classification datasets. They used KAN and MLP with one to two hidden layers and adjusted the input and output dimensions of the neural network according to the characteristics of the data set. On both audio datasets, MLP outperforms KAN. In the text classification task, MLP maintains its advantage on the AG News dataset. However, on the CoLA dataset, there is no significant difference in performance between MLP and KAN. KAN seems to have an advantage on the CoLA dataset when the number of control parameters is the same. However, since KAN's splines require higher FLOP, this advantage is not consistently evident in experiments with controlled FLOP. When controlling for FLOP, MLP appears to be superior. Therefore, There is no clear answer as to which model is better on the CoLA dataset. Overall, MLP is still the better choice in both audio and text tasks. symbol formula representation. The authors compared the differences between KAN and MLP on eight symbolic formula representation tasks. They used KAN and MLP with one to four hidden layers, adjusting the input and output dimensions of the neural network according to the data set. KAN outperforms MLP on 7 out of 8 datasets while controlling the number of parameters. When controlling for FLOP, KAN performs roughly on par with MLP, outperforming MLP on two datasets, and inferior to MLP on the other due to the additional computational complexity introduced by splines. Overall, KAN outperforms MLP in the symbolic formula representation task.
🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜 🎜 🎜🎜🎜🎜🎜🎜、ショートカット ウェイト、B サイズのウェイト、バイアス用語。学習可能なパラメーターの総数は次のとおりです: 🎜🎜🎜🎜🎜 ここで、d_in と d_out はニューラル ネットワーク層の入力次元と出力次元を表し、K はスプラインの次数を表し、公式 nn.Module のパラメーター k に対応します。 KANLayer。スプライン関数の多項式基底の次数です。 G はスプライン間隔の数を表し、公式の nn.Module KANLayer の num パラメータに対応します。充填前の B スプラインの間隔の数です。埋める前は、制御点の数 - 1 に等しくなります。充填後は、(K +G) 個の有効なコントロール ポイントが存在するはずです。 🎜🎜🎜🎜🎜これに対応して、MLP 層の学習可能なパラメータは次のとおりです: 🎜🎜🎜🎜🎜🎜MLP の 🎜🎜🎜🎜🎜🎜KAN と FLOP🎜🎜🎜🎜🎜🎜 著者の評価では、あらゆる算術演算の FLOP は 1 であると見なされます。ブール演算の FLOP は 0 とみなされます。 De Boor-Cox アルゴリズムの 0 次演算は、浮動小数点演算を必要としない一連のブール演算に変換できます。したがって、理論的には FLOP は 0 です。これは、演算のためにブール データを浮動小数点データに変換する公式の KAN 実装とは異なります。 🎜🎜🎜🎜🎜 筆者の評価では、1つのサンプルに対してFLOPを計算しています。公式 KAN コードで De Boor-Cox 反復公式を使用して実装された B スプライン FLOP は次のとおりです: 🎜🎜🎜🎜🎜 ショートカット パスの FLOP と 2 つの分岐をマージした FLOP を合わせた、KAN 層の合計 FLOP対応して、MLP 層の FLOP は次のようになります。 🎜🎜🎜🎜🎜 同じ入力次元と出力次元を持つ KAN 層と MLP 層の FLOP の差は、次のように表すことができます。 🎜🎜🎜🎜 🎜MLP も最初に非線形演算を実行する場合、先頭項はゼロになります。 🎜🎜🎜🎜🎜🎜 実験 🎜🎜🎜🎜🎜🎜 著者の目標は、パラメータまたは FLOP の数が等しい場合の KAN と MLP のパフォーマンスの違いを比較することです。この実験は、機械学習、コンピューター ビジョン、自然言語処理、音声処理、記号式表現などの複数の分野をカバーしています。すべての実験は Adam オプティマイザーを使用し、すべて RTX3090 GPU で実行されました。 🎜🎜🎜🎜🎜🎜パフォーマンスの比較🎜🎜🎜🎜🎜🎜機械学習。著者らは、1 つまたは 2 つの隠れ層を持つ KAN と MLP を使用して 8 つの機械学習データセットに対して実験を実施し、各データセットの特性に基づいてニューラル ネットワークの入力次元と出力次元を調整しました。 🎜🎜🎜🎜🎜MLPの場合、隠れ層の幅は32、64、128、256、512、または1024に設定され、活性化関数としてGELUまたはReLUが使用され、MLPでは正規化層が使用されます。 KAN の場合、隠れ層の幅は 2、4、8、または 16、B-スプライン メッシュの数は 3、5、10、または 20、B-スプライン次数は 2、3、または 5 です。Since the original KAN architecture does not include a normalization layer, in order to balance the possible advantages of the normalization layer in MLP, the author expanded the value range of the KAN spline function. All experiments were conducted for 20 rounds of training, and the best accuracy achieved on the test set during the training process was recorded, as shown in Figures 2 and 3. On machine learning datasets, MLP usually maintains an advantage. In their experiments on eight datasets, MLP outperformed KAN on six of them. However, they also observed that on one dataset, the performance of MLP and KAN was almost equivalent, while on the other dataset, KAN performed better than MLP. Overall, MLP still has general advantages on machine learning datasets. Computer Vision. The authors conducted experiments on 8 computer vision datasets. They used KANs and MLPs with one or two hidden layers, adjusting the input and output dimensions of the neural network depending on the dataset. In computer vision data sets, the processing bias introduced by KAN ’s spline function has no effect, and its performance is always inferior to MLP with the same number of parameters or FLOPs. Audio and natural language processing. The authors conducted experiments on 2 audio classification and 2 text classification datasets. They used KAN and MLP with one to two hidden layers and adjusted the input and output dimensions of the neural network according to the characteristics of the data set. On both audio datasets, MLP outperforms KAN. In the text classification task, MLP maintains its advantage on the AG News dataset. However, on the CoLA dataset, there is no significant difference in performance between MLP and KAN. KAN seems to have an advantage on the CoLA dataset when the number of control parameters is the same. However, since KAN's splines require higher FLOP, this advantage is not consistently evident in experiments with controlled FLOP. When controlling for FLOP, MLP appears to be superior. Therefore, There is no clear answer as to which model is better on the CoLA dataset. Overall, MLP is still the better choice in both audio and text tasks. symbol formula representation. The authors compared the differences between KAN and MLP on eight symbolic formula representation tasks. They used KAN and MLP with one to four hidden layers, adjusting the input and output dimensions of the neural network according to the data set. KAN outperforms MLP on 7 out of 8 datasets while controlling the number of parameters. When controlling for FLOP, KAN performs roughly on par with MLP, outperforming MLP on two datasets, and inferior to MLP on the other due to the additional computational complexity introduced by splines. Overall, KAN outperforms MLP in the symbolic formula representation task. 以上是反轉了?在一場新較量中,號稱替代MLP的KAN只贏一局的詳細內容。更多資訊請關注PHP中文網其他相關文章!

































