

AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
文章作者皆為來自劍橋大學語言技術實驗室,一為三年級博士生劉胤,導師為教授Nigel Collier 和Ehsan Shareghi。他的研究興趣是大模型和文本評估,數據生成等。共同一作為二年級博士生週涵,導師為教授 Anna Korhonen 和 Ivan Vulić,他的研究興趣是高效大模型。
大模型展現出了卓越的指令跟隨和任務泛化的能力,這種獨特的能力源自 LLMs 在訓練中使用了指令跟隨數據以及人類反饋強化學習(RLHF)。在 RLHF 訓練範式中,獎勵模型根據排名比較資料與人類偏好對齊。這增強了 LLMs 與人類價值觀的對齊,從而產生更好地幫助人類並遵守人類價值觀的回應。
近日,第一屆大模型頂會COLM 剛剛公佈接收結果,其中一項高分工作分析了LLM 作為文本評估器時難以避免和糾正的分數偏見問題,並提出了將評估問題轉換成偏好排序問題,從而設計了PairS 演算法,一個可以從成對偏好(pairwise preference)中搜尋和排序的演算法。透過利用不確定性和 LLM 傳遞性(transitivity)的假設,PairS 可以給出高效,準確的偏好排序,並在多個測試集上展現出和人類判斷更高的一致性。

論文連結: https://arxiv.org/abs/2403.16950
論文標題: Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators
Github 地址: https://github.com/cambridgeltl/PairS
用大模型評估有什麼問題?
最近大量的工作展示了 LLMs 在評估文本質量上的出色表現,形成了一種無需參考的生成任務評估新範式,避免了昂貴的人類標註成本。然而,LLM 評估器(evaluator)對提示(prompt)設計高度敏感,甚至會受到多種偏見的影響,包括位置偏見、冗長偏見和上下文偏見。這些偏見阻礙了 LLM 評估器的公平和可信,導致與人類判斷的不一致和不對齊。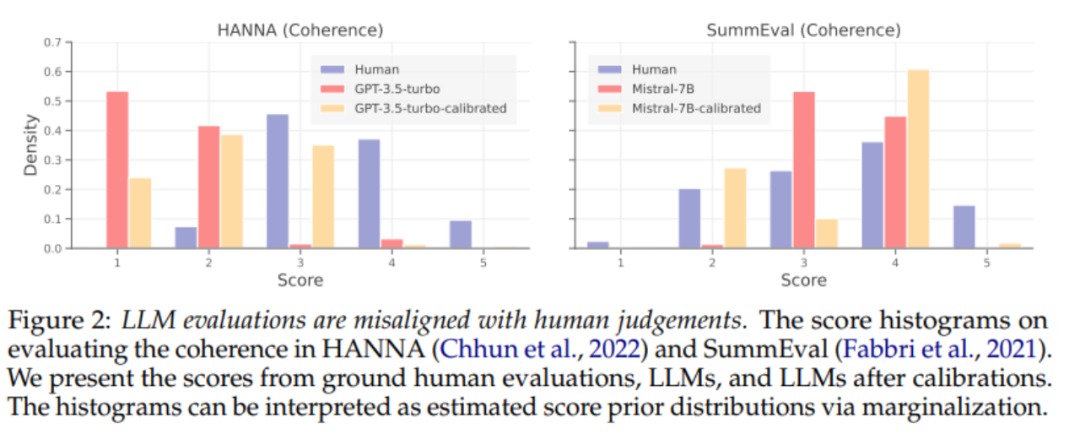

RLHF 帶來的啟發
如下圖1 所示,受到RLHF 中透過偏好對獎勵模型進行對齊的資料啟發,我們認為LLM 評估器可以透過產生偏好排序(preference ranking)來得到更和人類對齊的預測。最近已有一些工作開始透過讓 LLM 進行成對比較(pairwise comparison)來得到偏好排序。然而,評估偏好排序的複雜性和可擴展性在很大程度上被忽視了。它們忽略了傳遞性假設(transitivity assumption),使得比較次數的複雜度為 O (N^2),讓評估過程變得昂貴且可行。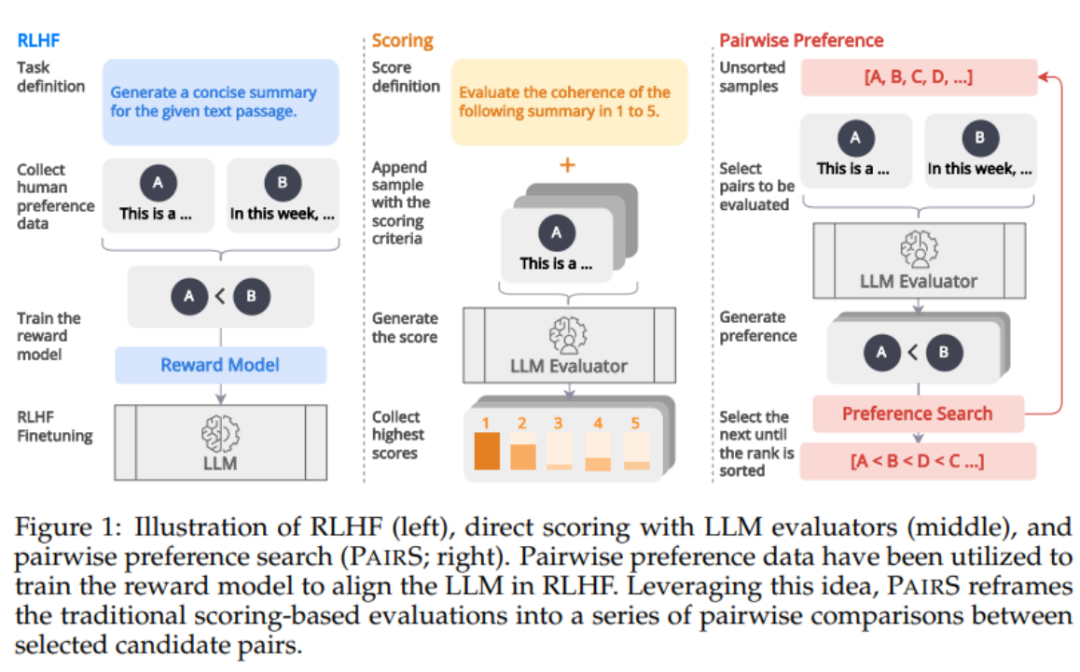
PairS:高效偏好搜尋演算法
在本工作中,我們提出了兩種成對偏好搜尋演算法(PairS-greedy 和PairS-beam)。 PairS-greedy 是基於完全的傳遞性假設和合併排序(merge sort)的演算法,只需要透過 O (NlogN) 的複雜度就可以獲得全局的偏好排序。傳遞性假設是指,例如 3 個候選項,LLM 總是有如果 A≻B 以及 B≻C,則 A≻C。在這個假設下我們可以直接用傳統的排序演算法從成對偏好中獲得偏好排序。
但 LLM 並不具有完美的傳遞性,所以我們又設計了 PairS-beam 演算法。在較寬鬆傳遞性假設下,我們推導並化簡了偏好排序的似然函數(likelihood function)。 PairS-beam 在合併排序演算法的每一次的合併操作(merge operation)中按似然值做集束搜索,並通過偏好的不確定性(uncertainty)來減枝成對比較的空間的搜索方法。 PairS-beam 可以調整對比複雜度和排序質量, 高效的給出偏好排序的最大似然估計(MLE)。在下圖 3 中我們展示了一個 PairS-beam 如何做合併操作的範例。
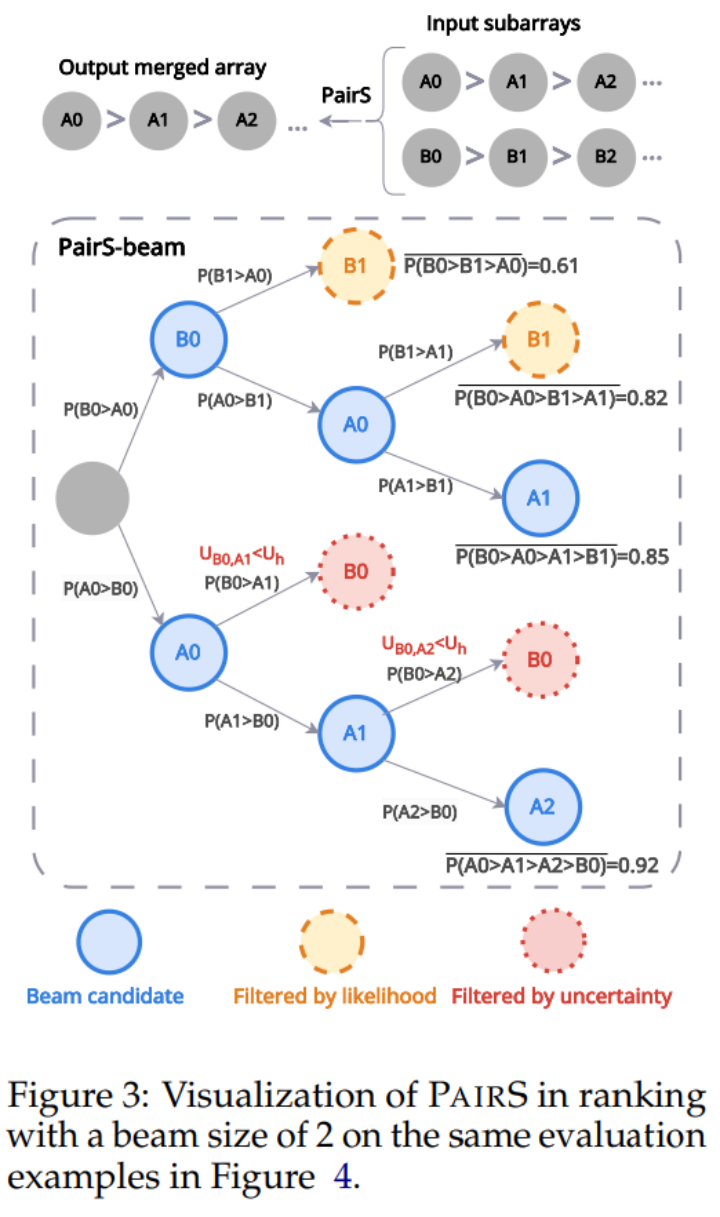
實驗結果
我們在多個代表性的資料集上進行了測試,包括閉合式產生的縮寫任務NewsRoom 和SummEval,和開放式的故事生成任務HANNA,並對比了多個LLM 單點評估的基線方法,包括無監督的direct scoring, G-Eval, GPTScore 和有監督訓練過的UniEval 以及BARTScore。如下表 1 所示,PairS 在每個任務上和他們相比都有著和人類評分更高的一致性。 GPT-4-turbo 更是能達到 SOTA 的效果。
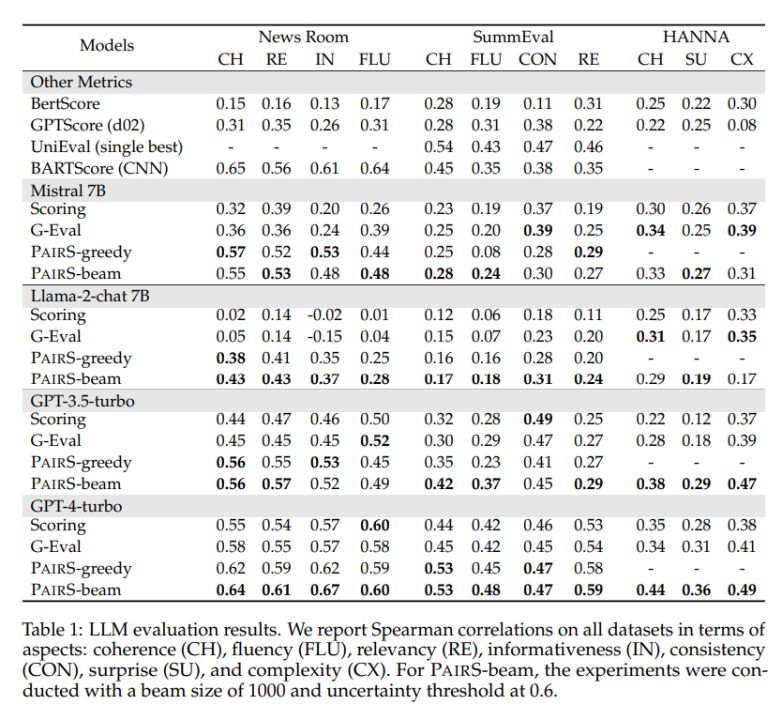
在文章中,我們也比較了兩種偏好排序的基準方法,win rate 和 ELO rating。 PairS 可以只用約 30% 的對比次數就能達到他們同樣品質的偏好排序。論文還提供了更多關於如何使用成對偏好來量化計算 LLM 評估器的傳遞性,以及成對評估器如何在校準中受益的見解。
更多研究細節,可參考原論文。
以上是首屆大模型頂會COLM 高分論文:偏好搜尋演算法PairS,讓大模型進行文字評估更有效率的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















