國外的 Luma、Runway,國內的快手可靈、字節即夢、智譜清影…… 你方唱罷我登場。無一例外,它們對標的都是那個傳說中的 Sora。 其實,說起 Sora 全球挑戰者,生數科技的 Vidu 少不了。 早在三個月前,國內外視頻生成領域還一片“沉寂”之時,生數科技突然曝出自家最新視頻大模型Vidu 的宣傳視頻,憑藉其生動逼真、不輸Sora 的效果,驚艷了一眾網友。 就在今天,Vidu 正式上線。無須申請,只要有個信箱,就能上手體驗。 (Vidu官網連結:www.vidu.studio)
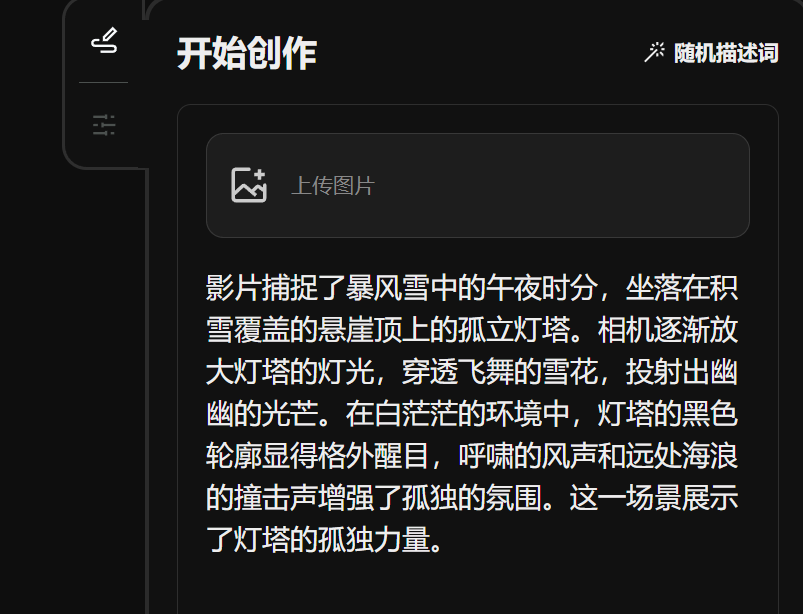
此外,Vidu 的生成效率也賊拉猛,實現了業界最快的推理速度,僅需30 秒就能生成一段4 秒鏡頭。 接下來,我們就奉上最新的一手評測,看看這款「國產 Sora」的實力究竟如何。 不僅延續了今年4 月份展示的高動態性、高逼真度、高一致性等優勢,還新增了動漫風格、文字與特效畫面生成、角色一致性等特色能力。 主打一個:別人有的功能,我要有,別人沒有的功能,我也要有。 現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 有現階段,Vidu 是現階段,Vidu兩大核心功能:文生影片和圖生影片。
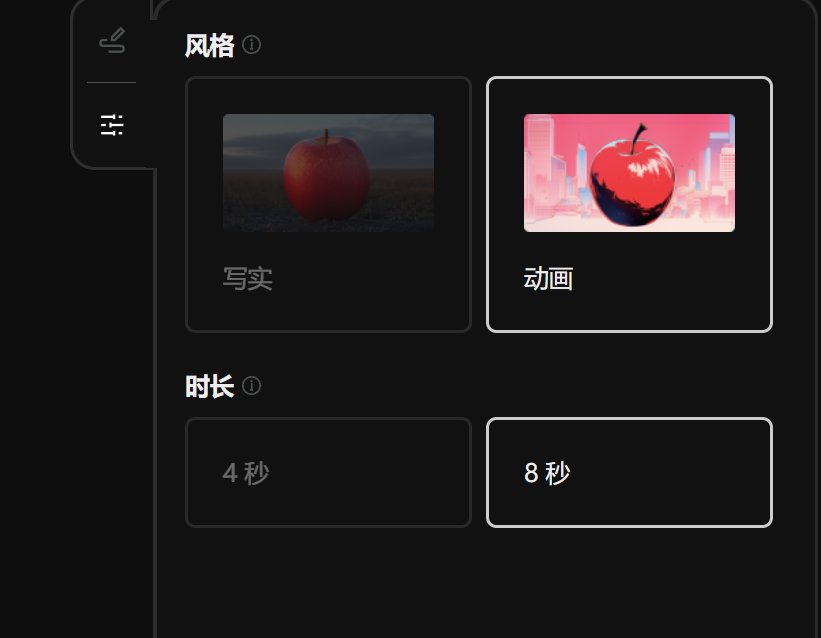
提供 4s 和 8s 兩種長度選擇,解析度最高可達 1080P。風格上,提供寫實和動畫兩大選擇。
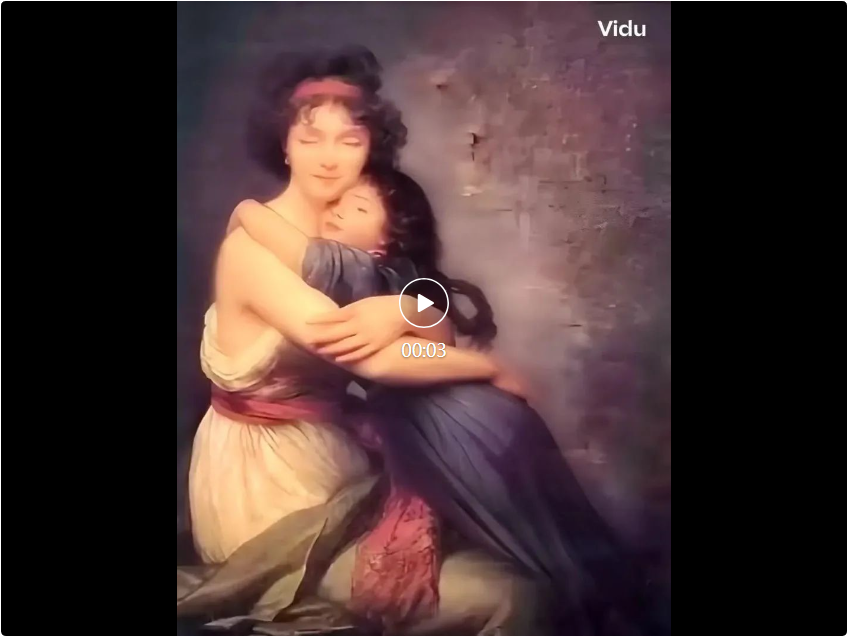
讓歷史重新鮮活起來,是當下最流行的玩法。這是法國畫家伊莉莎白・路易絲・維瑞的名作《畫家與女兒像》。
我們輸入提示字:畫家與女兒像,母女緊緊抱在一起。
產生的高清版本讓人眼前一亮,人物動作幅度很大,連眼神都有變化,但效果挺自然。
提示詞:抱銀鼬的女子麵露微笑。 長達8 秒的影片裡,女子和寵物動作幅度較大,特別是女子的手部撫摸動作,還有身體、臉部變化,但都沒有影響畫面的自然、流暢。 大幅度、精準的動作有助於更好地表現影片情節和人物情緒。不過,動作幅度一旦變大,畫面容易崩壞。因此,有些模型為保證流暢性,會犧牲動幅,而 Vidu 比較好地解決了這個問題。 模擬真實物理世界的運動,還真不錯。例如,復刻類似庫伯力克《2001 太空漫遊》的情景!
提示語:這次只她一人,獨自坐在櫻花深處的鞦韆架上,穿著粉紅的春衫,輕微蕩著鞦韆,幅度很小,像坐搖椅一般,微垂著頭,有點百無聊賴的樣子,緩緩伸足一點一點踢著地上的青草。那櫻花片片飄落在她身上頭上,她也不以手去拂,漸漸積得多了,和她衣裙的顏色相融,遠遠望去彷彿她整個人都是由櫻花砌成似的。 Vidu 語意理解能力不錯,還可以理解提示中一次包含多個鏡頭的片段要求。 比如,畫面中既有海邊小屋的特寫,還有運鏡轉向海面遠眺的遠景,透過鏡頭切換,賦予畫面一種鮮明的敘事感。 提示語:在一個古色古香的海邊小屋裡,陽光沐浴著房間,鏡頭緩慢過渡到一個陽台,俯瞰著寧靜的大海,最後鏡頭定格在漂浮著大海、帆船和倒影般的雲彩。 對於第一人稱、延時攝影等鏡頭語言,Vidu 也能準確理解和表達,使用者只需細化提示詞,即可大幅提升影片的可控性。 提示下與第一人稱視角,一起漫步在我的女友手中,一起帶著女友,手旁的手扶著女友。 Vidu 是一款能夠準確理解並產生一些詞彙的視訊產生器,例如數字。
提示時:一個為一個生日蠟燭,為「上面插著33個蠟燭,233個蠟燭」。 蛋糕上換成「Happy Birthday」的字樣,它也能hold住。
我們選擇動畫模型,直接輸入提示詞即可輸出動畫風格影片。 說實話,這畫風有宮崎駿老爺的味道。 Vidu 讀懂了提示詞,小女孩切菜動作一氣呵成,就是手指和刀具在不經意間仍有變形。
提示詞:動畫風格,一個戴著耳機的小女孩在跳舞。
Vidu 的想像力還挺豐富,自個兒把背景設定為有噴泉的公園,這也讓影片畫面不那麼單調。
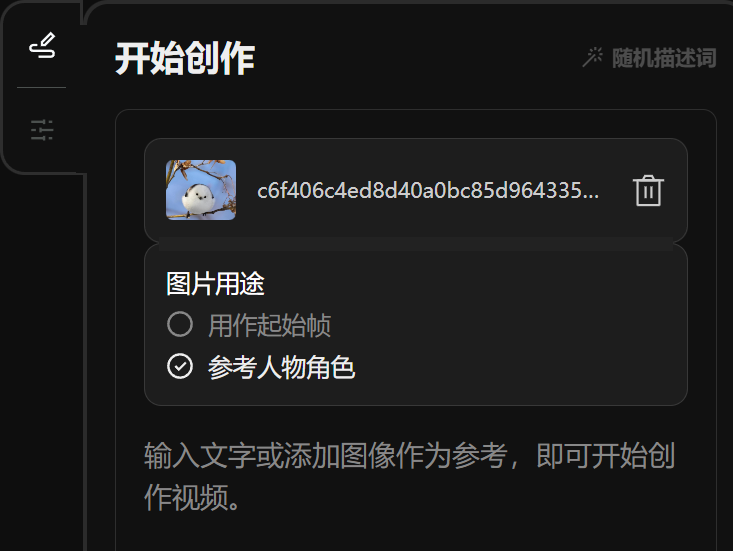
當然,我們還可以上傳一張動漫參考圖片,再輸入提示詞,如此一來,圖片中的動漫人物就能動起來啦。
例如,我們上傳一張蠟筆小新的靜態圖,然後輸入提示詞:蠟筆小新大笑著舉起手裡的小花。圖片用途選擇「用作起始影格」。 我們來瞅瞅效果:再上傳一張呆萌皮卡丘的圖像,輸入提示詞為「皮卡丘開心地蹦起來」。圖片用途選擇「用作起始影格」。
繼續上效果:上傳《海賊王》路飛的圖像,再餵它提示詞:男孩突然哭起來。
效果如下:不得不說, Vidu 的動畫效果相當驚艷,在保持風格一致性的同時,顯著提高了畫面的穩定性和流暢性,沒有出現變形、崩壞或六指狂魔、左右腿不分等「邪門」畫面。 在「圖生視頻」板塊中,除了支援首幀圖上傳,Vidu 這次還上新一項功能- 角色一致性(Charactor To Video)。 所謂角色一致性,就是上傳一個角色圖像,然後可以指定該角色在任意場景中做出任意動作。
提示詞:在一艘宇宙飛船裡,吳京正穿著太空服,對鏡頭揮手。
如果說,首幀圖上傳適合創作場景一致性的視頻,那麼,有了角色一致性功能,從科幻角色到現代劇,演員七十二變,信手拈來。 此外,有了角色一致性功能,一般使用者創作「梗圖」、「表情包」可以燥起來了! 例如讓北美「意難忘」賈斯汀・比伯和賽琳娜再續前緣:
《武林外傳》中佟湘玉和白展堂嗑著瓜子,聊著同福客棧的八卦:
還有《甄嬛傳》皇后只要腦洞夠大,什麼地鐵老人吃手機、鰲拜和韋小寶打啵、容嬤餵紫薇吃雞腿,Vidu 都能整出來。 影片產生過程中,使用者最煩啥?當然是龜速爬行的進度條。 試想,為了一段幾秒的視頻,愣是趴在電腦前等個十分鐘,再慢性子的人也很難不破防。 目前,市面上主流 AI 視訊工具會產生一段約 4 秒的影片片段,通常需要 1 到 5 分鐘,甚至更長。 例如,Runway 最新推出的Gen-3 工具需要1 分鐘來完成5s 視訊生成,可靈需要2-3 分鐘,而Vidu 將這一等待時間縮短至30 秒,速度比業界最快水準的Gen-3 還要再快一倍。
「 Vidu」底層則是基於完全自研的U-ViT 架構,由團隊在2022 年9 月提出,早於Sora 採用的DiT 架構,是全球首個Diffusion 和Transformer 融合的架構。
在DiT 論文發布兩個月前,清華大學的朱軍團隊提交了一篇論文—《All are Worth Words: A ViT Backbone for Diffusion Models》。這篇論文提出了以 Transformer 取代基於 CNN 的 U-Net 的網路架構 U-ViT。這是「Vidu」最重要的技術基礎。
由於不涉及中間的插幀和拼接等多步驟的處理,文本到視頻的轉換是直接且連續的,“Vidu” 的作品感官上更加一鏡到底,視頻從頭到尾連續生成,沒有插幀痕跡。除了底層架構上的創新,「Vidu」也復用了生數科技過往累積下的工程化經驗與能力。 生數科技曾稱,從圖任務的統一到融合視頻能力,“Vidu”可被視為一款通用視覺模型,能夠支持生成更加多樣化、較長時長的影片內容。他們也透露,「Vidu」還在加速迭代提升。面向未來,「Vidu」靈活的模型架構也將能夠相容於更廣泛的多模態能力。 生數科技成立於2023 年3 月,核心成員來自清華大學人工智慧研究院,致力於自主研發世界領先的可控多模態通用大模型。自 2023 年成立以來,團隊已獲得螞蟻集團、啟明創投、BV 百度創投、位元組錦秋基金等多家知名產業機構的認可,完成數億元融資。據悉,生數科技是目前國內在多模態大模型賽道估值最高的創業團隊。 公司首席科學家由清華人工智慧研究院副院長朱軍擔任;CEO 唐家渝本碩就讀於清華大學計算機系,是THUNLP 組成員;CTO 鮑凡是清華大學計算機系博士生、朱軍教授的課題組成員,長期關注擴散模型領域研究,U-ViT 和UniDiffuser 兩項工作均是由他主導完成的。 今年 1 月,生數科技旗下視覺創意設計平台 PixWeaver 上線了短視頻生成功能,支援 4 秒高美學性的短視頻內容。 2 月Sora 推出後,生數科技內部成立攻堅小組,加快了原本視頻方向的研發進度,不到一個月的時間,內部就實現了8 秒的視頻生成,緊接著4 月份就突破了16 秒生成,生成品質與時長全方面取得突破。 如果說4 月份的模型發布展示了Vidu 在視頻生成能力上的領先,這次正式發布的產品則展示了Vidu 在商業化方面的精心佈局。生數科技目前採取模型層和應用層兩條路走路的模式。 一方面,建構覆蓋文字、影像、影片、3D 模型等多模態能力的底層通用大模型,面向 B 端提供模型服務能力。 另一方面,以影像產生、影片產生等場景打造垂類應用,依照訂閱等形式收費,應用方向主要是遊戲製作、影視後製等內容創作場景。
參考連結:
以上是又一「國產版Sora」全球上線!清華朱軍創業團隊,影片生成僅需30秒的詳細內容。更多資訊請關注PHP中文網其他相關文章!














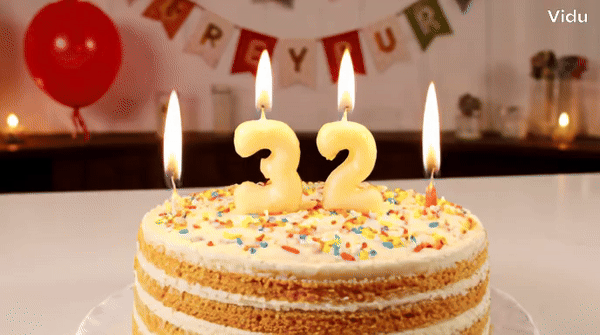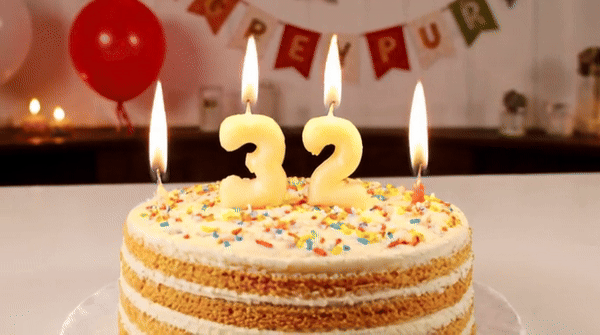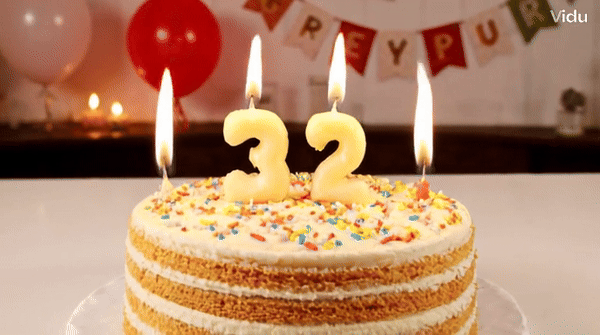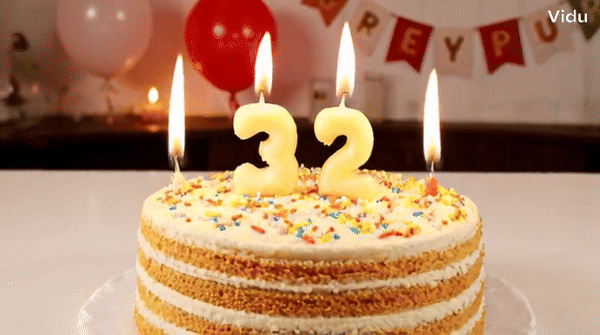
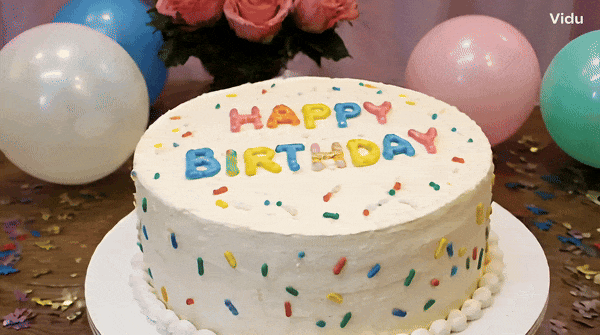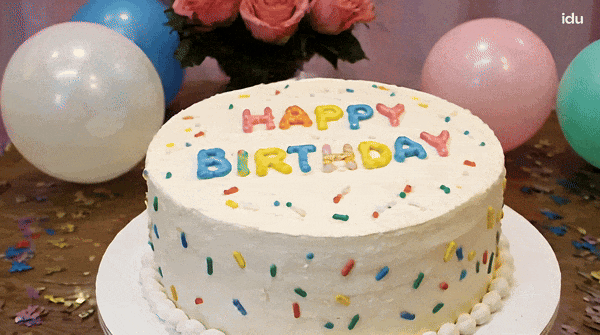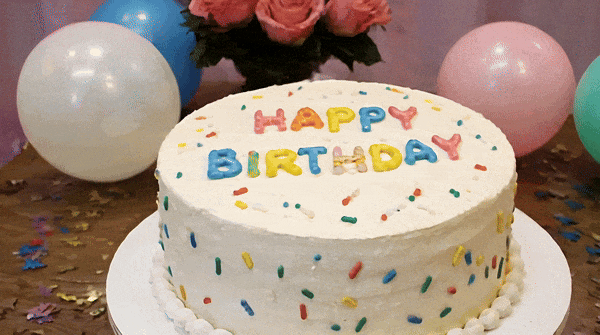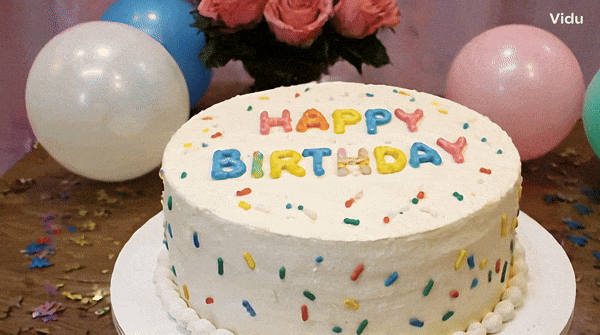
 說實話,這畫風有宮崎駿老爺的味道。 Vidu 讀懂了提示詞,小女孩切菜動作一氣呵成,就是手指和刀具在不經意間仍有變形。
說實話,這畫風有宮崎駿老爺的味道。 Vidu 讀懂了提示詞,小女孩切菜動作一氣呵成,就是手指和刀具在不經意間仍有變形。  Vidu 的想像力還挺豐富,自個兒把背景設定為有噴泉的公園,這也讓影片畫面不那麼單調。
Vidu 的想像力還挺豐富,自個兒把背景設定為有噴泉的公園,這也讓影片畫面不那麼單調。