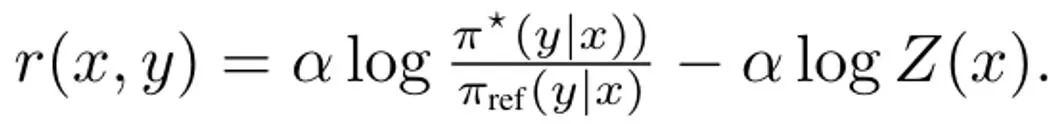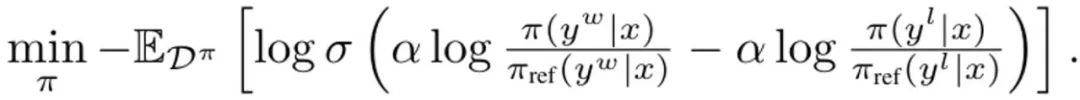養育孩子時,古往今來人們都會談到一種重要方法:以身作則。也就是讓自己成為孩子模仿學習的範例,而不是單純地告訴他們該怎麼做。在訓練大語言模型(LLM)時,我們或許也能採用這樣的方法 —— 向模型示範。
近日,史丹佛大學楊笛一團隊提出了一種新框架 DITTO,可透過少量演示(使用者提供的期望行為範例)將 LLM 與特定設定對齊。這些範例可以從使用者現有的互動日誌中獲取,也能透過直接編輯 LLM 的輸出得到。這樣就可以讓模型針對不同的使用者和任務有效率地理解並對齊使用者偏好。 
- 論文標題:Show, Don't Tell: Aligning Language Models with Demonstrated Feedback
DITTO 可基於少量簡報(少於10)自動建立一個包含大量偏好比較資料的資料集(這個過程被稱為scaffold),其具體做法是預設這一點:相比於原始LLM 及早期迭代版本的輸出,使用者更偏好演示。然後,將示範與模型輸出組成資料對,得到增強資料集。之後便可以使用 DPO 等對齊演算法來更新語言模型。 此外,該團隊還發現,DITTO 可被視為一種在線模仿學習演算法,其中從 LLM 採樣的數據會被用於區分專家行為。從這一角度出發,團隊證明 DITTO 可透過外推實現超越專家的表現。 為了對齊LLM,此前需要使用的各類方法往往需要使用成千上萬對比較數據,而DITTO 僅需使用少量演示就能修改模型的行為。這種低成本的快速適應之所以能實現,主要得益於該團隊的核心見解:可透過簡報輕鬆取得線上比較數據。
語言模型可以視為一個策略(y|y|x) ,這會得到prompt x 和完成結果y 的一個分佈。 RLHF 的目標是訓練 LLM 以最大化一個獎勵函數 r (x, y),其評估的是 prompt - 完成結果對 (x, y) 的品質。通常來說,也會增加一個 KL 散度,以防止更新後的模型偏離基礎語言模型(π_ref)太遠。整體而言,RLHF 方法最佳化的目標為:
這是最大化在 prompt 分佈 p 上的預期獎勵,而 p 則受 α 調節的 KL 限制的影響。通常而言,優化這一目標使用的是形式為{(x, y^w, y^l )} 的比較資料集,其中「獲勝」的完成結果y^w 優於「失敗」的完成結果y ^l,記為y^w ⪰ y^l。 另外,這裡把小型專家示範資料集記為 D_E,並假設這些示範是由專家策略 π_E 產生的,其能最大化預測獎勵。 DITTO 能直接使用語言模型輸出和專家演示來產生比較數據。也就是說,不同於合成資料的生成範式,DITTO 無需在給定任務上已經表現良好的模型。 DITTO 的關鍵見解在於語言模型本身,再加上專家示範,可以得到用於對齊的比較資料集,這樣就無需收集大量成對的偏好資料了。這會得到一個類似對比的目標,其中專家演示是正例。 產生比較。假定我們從專家策略取樣了一個完成結果 y^E ∼ π_E (・|x) 。那麼可以認為,從其它策略 π 採樣的樣本對應的獎勵都低於或等於從 π_E 採樣的樣本的獎勵。基於這個觀察,團隊建構了比較數據 (x, y^E, y^π ),其中 y^E ⪰ y^π。儘管這樣的比較數據源自於策略而非各個樣本,但先前已有研究證明了這種方法的有效性。對 DITTO 來說,一個很自然的做法就是使用這個資料集以及一個現成可用的 RLHF 演算法來最佳化 (1) 式。這樣做能在提升專家回應的機率同時降低目前模型樣本的機率,這不同於標準微調方法 —— 只會做前者。關鍵在於,透過使用來自 π 的樣本,可使用少量演示來建立無邊界的偏好資料集。但是,團隊發現,透過考慮學習過程的時間面,還能做到更好。 從比較到排名。僅使用來自專家和單一策略 π 的比較數據,可能不足以獲得優良性能。這樣做只會降低特定 π 的可能性,導致過擬合問題 —— 這也困擾著少數據情況下的 SFT。團隊提出也可以考慮 RLHF 期間隨時間而學習到的所有策略所產生的數據,這類似於強化學習中的 replay(重播)。 設第一輪迭代時的初始策略為 π_0。透過採樣該策略可得到一個資料集 D_0。然後可以基於此產生一個用於 RLHF 的比較資料集,可記為 D_E ⪰ D_0。使用這些導出的比較數據,可以對 π_0 進行更新而得到 π_1。根據定義,也成立。之後,繼續使用 π_1 產生比較數據,並且 D_E ⪰ D_1。繼續這個過程,不斷使用之前的所有策略來產生越來越多樣化的比較數據。該團隊將這些比較數據稱為「重播比較數據(replay comparisons)」。 儘管這種方法理論上說得通,但如果 D_E 較小,卻可能出現過擬合。但是,如果假設每一輪迭代後策略都會獲得提升,則也可在訓練期間考慮策略之間的比較。有別於與專家的比較,我們並不能保證每一輪迭代之後策略都更好,但該團隊發現模型每次迭代後總體依然是提升的,這可能是因為獎勵建模和(1) 式都是凸的。這樣便可以依照以下的排名來取樣比較數據:
透過加入這些「模型間」和「重播」比較數據,得到的效果是早期樣本(例如D_1 中的樣本)的似然會比後期的(如D_t 中的)壓得更低,從而使隱含的獎勵圖景變得平滑。在實務實作中,該團隊的做法是除了使用與專家的比較數據,也聚合了一些這些模型間比較數據。 一個實踐演算法。在實踐中,DITTO 演算法是一個迭代過程,其由三個簡單的組件構成,如演算法 1 所示。
首先,在專家演示集上執行監督式微調,執行數量有限的梯度步驟。將此設為初始策略π_0. 第二步,採樣比較資料:在訓練過程中,對於D_E 中的N 個演示中的每一個,透過從π_t 採樣M 個完成結果而建立一個新的資料集D_t,然後根據策略(2) 式將它們加到排名中。當從(2) 式取樣比較資料時,每一批B 都由70% 的「線上」比較資料D_E ⪰ D_t、20% 的「重播」比較資料D_E ⪰ D_{i
其中σ 是來自Bradley-Terry 偏好模型的logistic 函數。在每次更新期間,來自 SFT 策略的參考模型都不會更新,以避免偏離初始化太遠。 DITTO 可透過線上模仿學習角度推導出組合專家演示和線上數據來同時學習獎勵函數和策略。具體來說,策略玩家會最大化預期獎勵? (π, r),而獎勵玩家則會最小化在線上資料集D^π 上的損失min_r L (D^π , r) 更具體而言,該團隊的做法是使用(1) 式中的策略目標和標準的獎勵建模損失來實例化該最佳化問題:
推導DITTO,簡化(3) 式的第一步是解決其內部策略最大化問題。幸運的是,團隊基於先前的研究發現策略目標 ?_KL 有一個閉式解,其形式為,其中 Z (x) 用於歸一化分佈的配分函數。值得注意的是,這會在策略和獎勵函數之間建立雙射關係,這可以用於消除內部最佳化。透過重新排列這個解,可將獎勵函數寫成:此外,先前有研究顯示這種重新參數化可以表示任意獎勵函數。於是,透過代入到 (3) 式,可以將變數 r 變成 π,從而得到 DITTO 目標:請注意,類似於 DPO,這裡是隱式地估計獎勵函數。而不同於 DPO 的地方是 DITTO 依賴一個在線的偏好資料集 D^π。 DITTO 表現較好的一個原因是:透過產生比較數據,其使用的數據量遠多於 SFT。另一個原因是在某些情況下,線上模仿學習方法的表現會超過演示者,而 SFT 只能模仿演示。 團隊也進行了實證研究,證明了 DITTO 的有效性。實驗的具體設定請參閱原論文,我們這裡僅關注實驗結果。
平均而言,DITTO 勝過其它所有方法:在 CMCC 上平均勝率為 71.67%,在 CCAT50 上平均勝率為 82.50%;總體平均勝率為 77.09%。在 CCAT50 上,對於所有作者,DITTO 僅在其中一個上沒有全面優勝。在 CMCC 上,對於所有作者,DITTO 全面勝過其中一半基準,之後是 few-shot prompting 贏得 3 成。儘管 SFT 的表現很不錯,但 DITTO 相較於其的平均勝率提升了 11.7%。 整體而言,使用者研究的結果與在靜態基準上的結果一致。 DITTO 在對齊演示的偏好方面優於對比方法,如表2 所示:其中DITTO (72.1% 勝率) > SFT (60.1%) > few-shot (48.1%) > self-prompt (44.2%) > zero- shot (25.0%)。
在使用 DITTO 之前,使用者必須考慮一些前提條件,從他們有多少演示到必須從語言模型中取樣多少負例。該團隊探索了這些決定的影響,並重點關注了 CMCC,因為其覆蓋的任務超過 CCAT。此外,他們還分析了演示與成對回饋的樣本效率。 如圖 2(左)所示,增加 DITTO 的迭代次數通常可以提升效能。
可以看到,當迭代次數從 1 次提升到 4 次,GPT-4 評估的勝率會有 31.5% 的提升。這樣的提升是非單調的 —— 在第 2 次迭代時,表現稍有降低(-3.4%)。這是因為早期的迭代可能會得到雜訊更大的樣本,從而降低效能。另一方面,如圖 2(中)所示,增加負例數量會使 DITTO 效能單調提升。此外,隨著採樣的負例增多,DITTO 效能的變異數會下降。
另外,如表 3 所示,對 DITTO 的消融研究發現,去除其任何組件都會導致表現下降。 例如如果放棄線上方式的迭代式取樣,相較於使用 DITTO,勝率會從 70.1% 降至 57.3%。而如果在線上過程中持續更新 π_ref,則會導致效能大幅下降:從 70.1% 降至 45.8%。該團隊猜想原因是:更新 π_ref 可能會導致過擬合。最後,我們也能從表 3 中看到重播和策略間比較資料的重要性。 DITTO 的一大關鍵優勢是其樣本效率。團隊對此進行了評估,結果見圖 2(右);同樣,這裡報告的是歸一化後的勝率。 首先可以看到,DITTO 的勝率一開始會快速提升。在展示數量從 1 變成 3 時,每次增加都會讓歸一化效能大幅提升(0% → 5% → 11.9%)。 但是,當演示數量進一步增加時,收益增幅降低了(從4 增至7 時為11.9% → 15.39%),這說明隨著演示數量增加,DITTO 的性能會飽和。 另外,團隊猜想,不只展示數量會影響 DITTO 的效能,示範品質也會,但這還留待未來研究。 DITTO 的一個核心假設是樣本效率源自於示範。理論上講,如果使用者心中有一套完美的演示集合,透過標註許多成對的偏好資料也能達到類似的效果。 團隊做了一個近似實驗,使用從指令遵從 Mistral 7B 採樣的輸出,讓一位提供了用戶研究的演示的作者也標註了 500 對偏好數據。 總之,他們建構了一個成對的偏好資料集 D_pref = {(x, y^i , y^j )},其中 y^i ≻ y^j。然後他們計算了採樣自兩個模型的20 對結果的勝率情況—— 其一是使用DITTO 在4 個演示上訓練的,其二是僅使用DPO 在{0...500} 偏好數據對訓練的。
當僅從π_ref 採樣成對偏好數據時,可以觀察到產生的數據對位於演示的分佈外—— 成對的偏好不涉及用戶演示的行為(圖3 中Base policy 的結果,藍色)。即使當他們使用使用者演示對 π_ref 進行微調時,仍然需要超過 500 對偏好數據才能比肩 DITTO 的性能(圖 3 中 Demo-finetuned policy 的結果,橙色)。 以上是只需幾個演示就能對齊大模型,楊笛一團隊提出的DITTO竟然如此高效的詳細內容。更多資訊請關注PHP中文網其他相關文章!




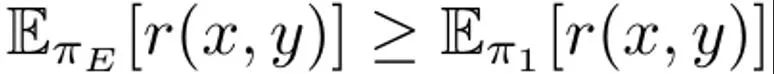 也成立。之後,繼續使用 π_1 產生比較數據,並且 D_E ⪰ D_1。繼續這個過程,不斷使用之前的所有策略來產生越來越多樣化的比較數據。該團隊將這些比較數據稱為「重播比較數據(replay comparisons)」。
也成立。之後,繼續使用 π_1 產生比較數據,並且 D_E ⪰ D_1。繼續這個過程,不斷使用之前的所有策略來產生越來越多樣化的比較數據。該團隊將這些比較數據稱為「重播比較數據(replay comparisons)」。