

隨著大模型的落地按下加速鍵,文生圖無疑是最火熱的應用方向之一。
自從 Stable Diffusion 誕生以來,海內外的文生圖大模型層出不窮,一時有「神仙打架」之感。短短幾個月,「最強 AI 畫師」的稱號幾次易主。每一次技術迭代,都不斷刷新著AI影像生成品質和速度的上限。
於是現在,我們輸入幾個文字就能得到任何想要的畫面。無論是專業級的商業海報,還是超寫實畫風的寫真照片,AI 製圖的逼真程度已經讓我們嘆為觀止。甚至 AI 贏下了 2023 年度的索尼世界攝影獎。在大獎公佈之前,這張「照片」已經在倫敦薩默賽特宮進行展覽——如果作者不公開說明,可能沒有人會發現這張照片實際出自 AI 之手。

Eldagse和他的AI生成中使用「恆電工」的基礎來製作時讓牠付出的離婚技巧。 第六期的《AIGC體驗派》就邀請到了豆包文生圖技術專家李亮、NVIDIA 解決方案架構師趙一嘉,為我們深入剖析了文生圖模型出圖更美、更快、更懂用戶心意背後的技術鏈路。
直播開始,李亮首先詳細拆解了近期國產大模型「頂流」—— 位元組跳動豆包大模型在文生圖模型方面的技術升級。
李亮表示,豆包團隊想解決的問題主要包含三個面向:一是如何實現更強的圖文匹配來滿足用戶的想法設計;第二個是如何產生更具美感的圖像來提供更極致的使用者體驗;第三個是如何更快速地出圖來滿足超大規模的服務呼叫。 在圖文配對方面,豆包團隊從資料入手,對海量圖文資料做精細篩選,最終入庫了千億量級的高品質影像。此外,團隊還專門訓練了一個多模態大語言模型進行 recapiton 任務。這個模型將更全面、客觀地描述圖片中影像的物理關係。有了高品質高細節的圖文對數據之後,想要更好地發揮出模型的實力,還需要提昇文本理解模組的能力。團隊採用原生雙語大語言模型作為文字編碼器,顯著提升了模型理解中文的能力,因此,面對「唐代」、「元宵節」等國風元素,豆包・文生圖模型也展現出了更加深刻的理解力。 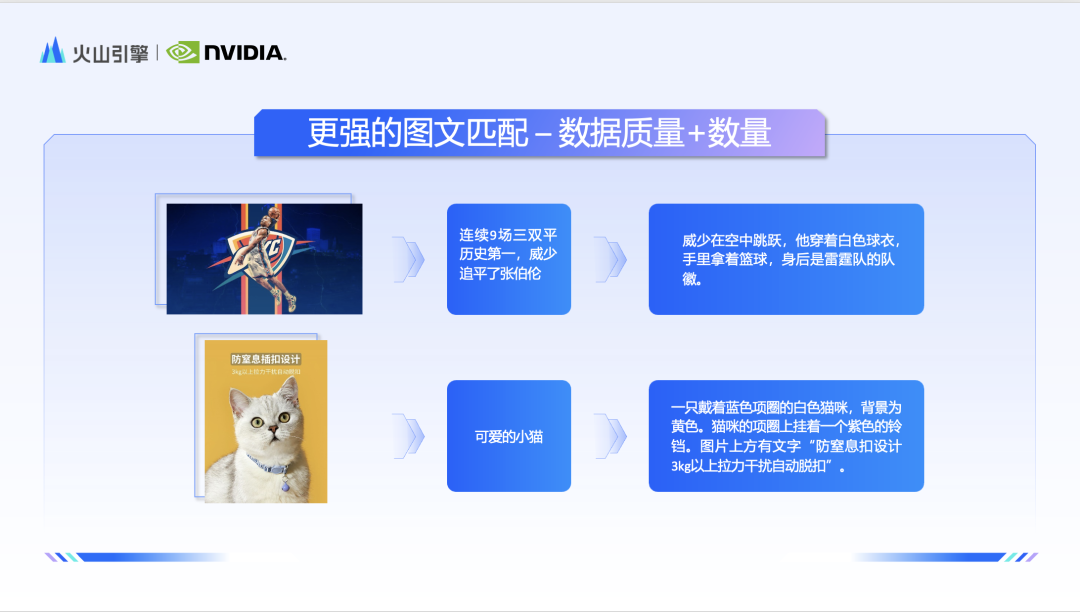
對於Diffsuion 模型架構,豆包團隊也注入了獨門秘籍,他們UNet 進行了有效地scaling,透過增加參數量,豆包・文生圖模型進一步地提升了圖像文本對的理解和高保真的生成能力。 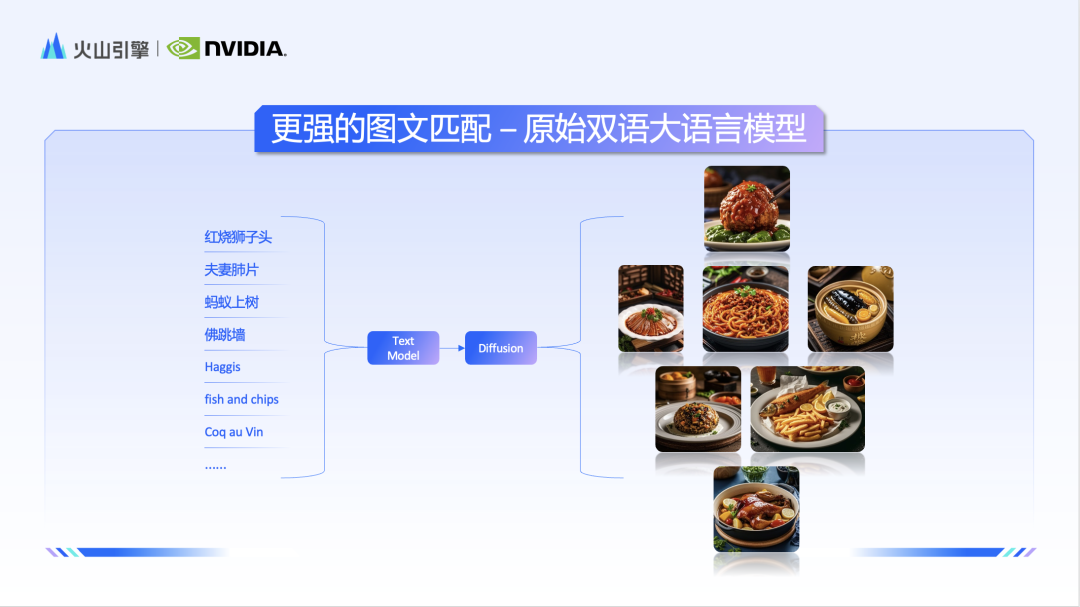
針對用戶直觀感受最明顯的美學風格,豆包團隊引入了專業的美學指導,也時刻關注用戶和大眾美學的偏好。同時,團隊也在數據和模型架構上下了一番功夫。很多時候,用戶得到的圖像和demo 展示的效果對比好比“買家秀”和“賣家秀”,實際上是給出的prompt 對於模型來說不夠詳細和明確,而豆包·文生圖模型引入了一個「Rephraser」,在遵循使用者原始意圖的同時,為提示詞增加更多的細節描述,所有使用者也將因此體驗到更完美的生成效果。 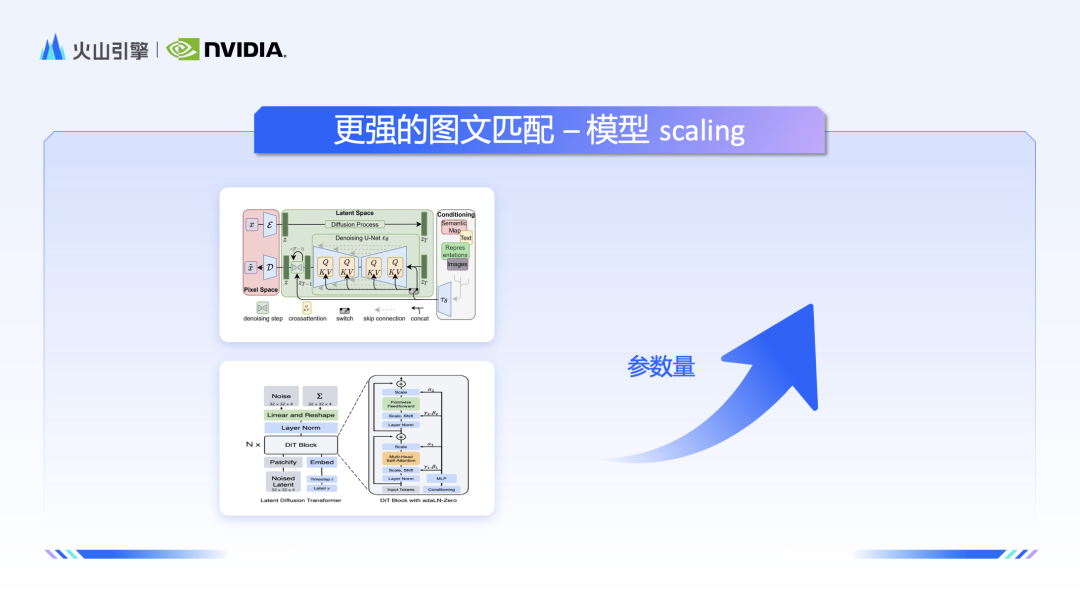
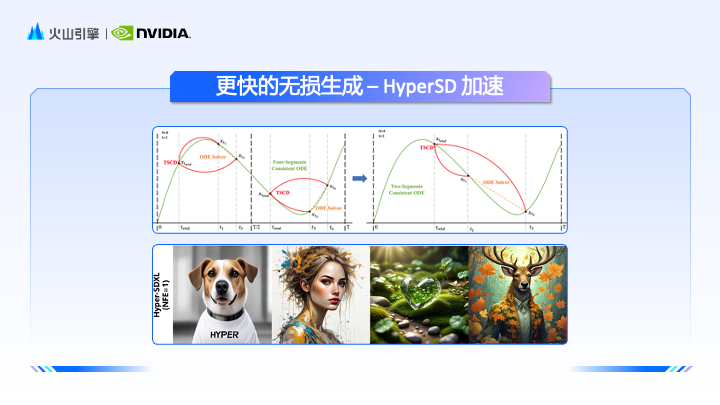
為了讓模型出圖速度更快,每張圖消耗的成本更低,豆包團隊在模型的蒸餾方式上也給出了新的解題思路,一項代表性的成果是Hyber- SD,這是一種新穎的擴散模型蒸餾框架,可在壓縮去雜訊步數的同時保持接近無損的性能。 
Next, NVIDIA solution architect Zhao Yijia started from the underlying technology and explained the two most mainstream Unet-based SD and DIT model architectures of Vincent Graph and their corresponding characteristics, and introduced NVIDIA's Tensorrt, Tensorrt- How tools such as LLM, Triton, and Nemo Megatron provide support for deploying models and help large models reason more efficiently.
Zhao Yijia first shared a detailed explanation of the principles behind the model behind Stable Diffusion, and elaborated on the working principles of key components such as Clip, VAE and Unet. As Sora became popular, it also became popular with the DiT (Diffusion Transformer) architecture behind it. Zhao Yijia further made a comprehensive comparison of the advantages of SD and DiT from three aspects: model structure, characteristics and computing power consumption.
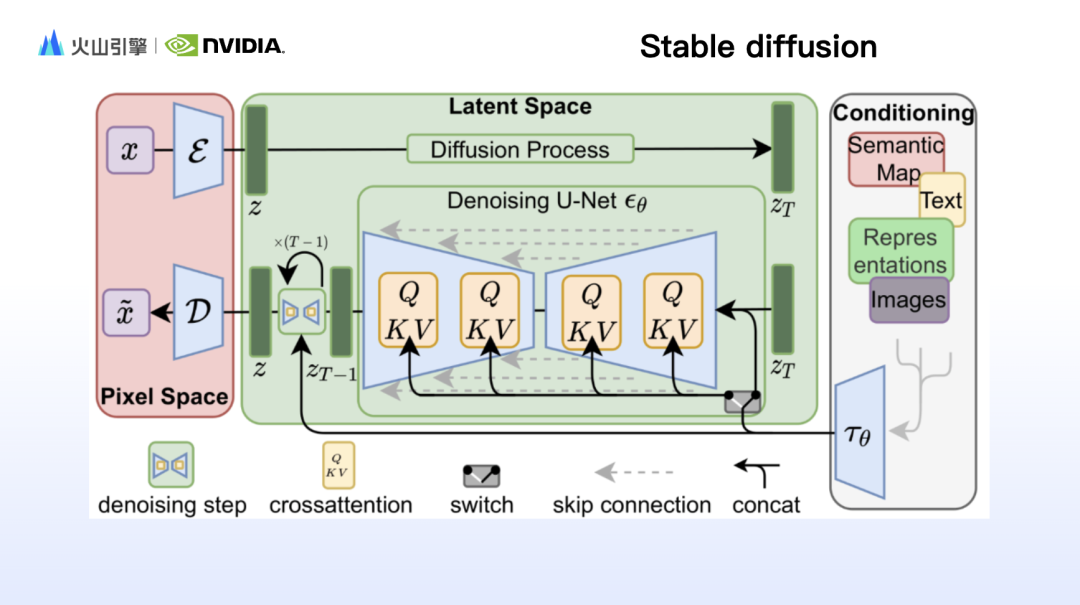
When using Stable diffusion to generate images, you often feel that the content of the prompt words is presented in the generated results, but the image is not what you want. This is because Stable diffusion based on text rendering is not good at controlling images. details, such as composition, movement, facial features, spatial relationships, etc. Therefore, based on the working principle of Stable diffusion, researchers have designed many control modules to make up for the shortcomings of Stable diffusion. Zhao Yijia added the representative IP-adapter and ControlNet. 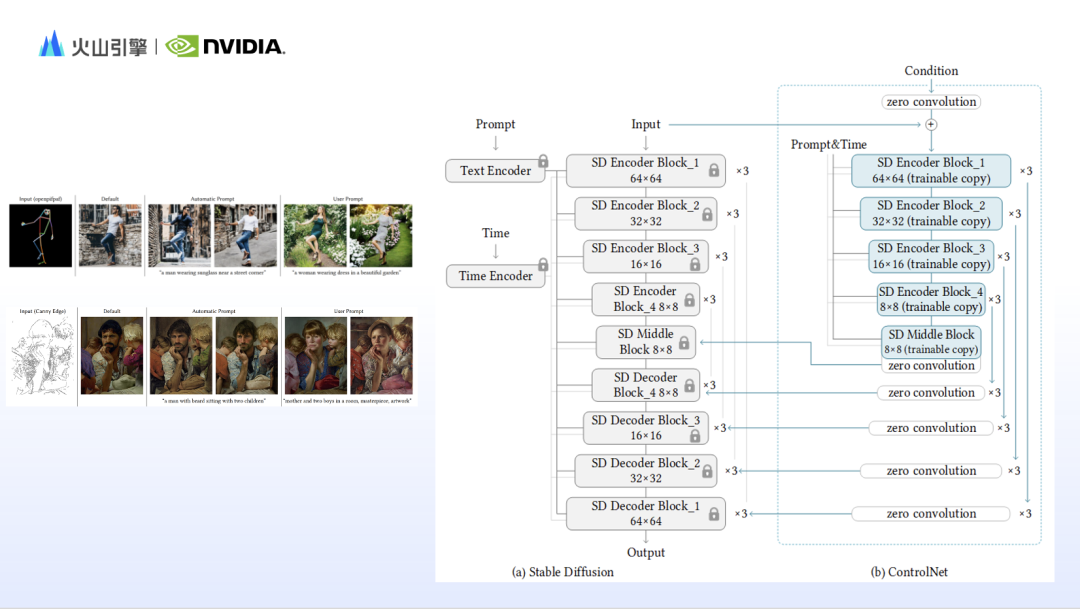
If we want to speed up the inference speed of the computationally demanding Vincent graph model, NVIDIA's technical support plays a key role. Zhao Yijia introduced Nvidia TensorRT and TensorRT-LLM tools, which optimize the inference process of image and text generation models through high-performance convolution, efficient scheduling and distributed deployment technologies. At the same time, NVIDIA's Ada, Hopper and the upcoming BlackWell hardware architecture already support FP8 training and inference, which will bring a smoother experience to model training.

After six wonderful live broadcasts, the "AIGC Experience Party" jointly launched by Volcano Engine, NVIDIA, this site and CMO CLUB has come to a successful conclusion. Through these six episodes, I believe everyone has a deeper understanding of how AIGC changes from "interesting" to "useful". We also look forward to the "AIGC Experience School" not only staying in the discussion of the program, but also accelerating the process of intelligent upgrading in the marketing field in practice.
Review address of all six issues of "AIGC Experience School": https://vtizr.xetlk.com/s/7CjTy
以上是AI出圖更快、更美、更懂你心意,高美感文生圖模型修了哪些技術秘籍?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















