
本週學術界矚目的焦點,無疑是在泰國曼谷舉行的 ACL 2024 頂會。這場盛會吸引了全球許多傑出的研究者,大家匯聚一堂,共同探討並分享最新學術成果。
官方公佈的數據顯示,本屆ACL 共收到近5000 篇論文投稿,其中940 篇被主會錄用,168 篇工作入選大會口頭報告(Oral),錄取率低於3.4%,這一當中,位元組跳動共有5 篇成果中選Oral。
在8 月14 日下午的Paper Awards 環節,位元組跳動旗下成果《G-DIG: Towards Gradient-based DIverse and high-quality Instruction Data Selection for Machine Translation》被主辦單位宣入選Outstanding Paper(1/35)。

回溯ACL 2021,位元組跳動曾經摘下唯一一篇最佳論文桂冠,是ACL 成立59 年以來,中國科學家團隊第2 次摘得最高獎項! 為深入探討今年的前沿研究成果,我們刻意邀請字節跳動論文的核心工作者解讀分享。
8 月 20 日下週二 19:00-21:00,「位元組跳動 ACL 2024 前沿論文分享會」線上開播!豆包大語言模型研究團隊負責人王明軒,將攜手字節跳動多位研究員
黃志超、鄭在翔、李朝偉、張欣勃、及Outstanding Paper 神秘嘉賓,分享ACL 部分精彩中選成果,研究方向涉及自然語言處理、語音處理、多模態學習、大模型推理等領域,歡迎預約! 活動議程


 >
>論文地址:https://arxiv.org/pdf/2309.00169 RepCodec:一種用於語音離散化的語音表示編解碼器
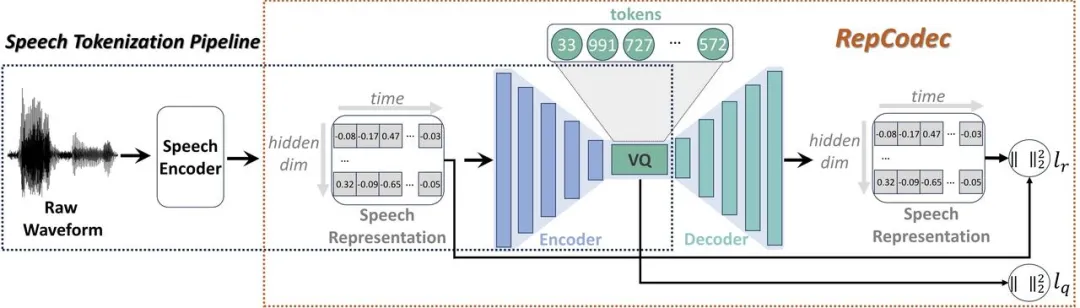 Framework of RepCodec
Framework of RepCodec
DINOISER:透過噪音操弄增強的擴散條件序列產生模型 DINOISER:透過噪音操弄增強的擴散條件序列產生模型 論文地址:https://arxiv.org/pdf/2302.10025

透過減少冗餘加速視覺條件語言產生的訓練 論文地址:https:/ /arxiv.org/pdf/2310.03291
 StreamVoice:即時零樣本語音轉換的可流式情境感知語言建模
StreamVoice:即時零樣本語音轉換的可流式情境感知語言建模
論文地址:https://arxiv.org/pdf/2401.11053 🎜>在該工作中,我們提出StreamVoice,一個新的基於串流LM 的零樣本語音轉換模型,實現針對任意說話者和輸入語音的即時轉換。具體來說,為了實現流式能力,StreamVoice 使用上下文感知的完全因果 LM 以及時序無關的聲學預測器,同時自回歸過程中交替處理語義和聲學特徵消除了對完整源語音的依賴。流式零樣本語音轉換(streaming zero-shot voice conversion)是指能即時將輸入語音轉換成任意說話者的語音,且僅需要該說話者一句語音作為參考,且無需額外的模型更新。現有的零樣本語音轉換方法通常是為離線系統設計,難以滿足即時語音轉換應用對於串流能力的需求。近期基於語言模型(language model, LM)的方法在零樣本語音生成(包括轉換)上展現出卓越的性能,但是需要整句處理而局限於離線場景。

G-DIG:致力於基於梯度的機器翻譯多樣化和高品質指令資料選擇 論文地址:https://arxiv.org/pdf/2405.12915

影響函數和一個小型高品質種子資料集,選擇對模型產生有益影響的訓練範例作為高品質範例。此外,為了增強訓練資料的多樣性,我們透過對它們的梯度進行聚類和重新採樣,最大程度地增加它們對模型影響的多樣性。在 WMT22 和 FLORES 翻譯任務上的大量實驗證明了我們方法的優越性,深入的分析進一步驗證了其有效性和通用性。

GroundingGPT:語言增強的 論文地址:https://arxiv.org/pdf/2401.06071 多模態大語言模型在不同模態的各種任務中都展現出了出色的性能。然而先前的模型主要強調捕捉多模態輸入的全局訊息,因此這些模型缺乏有效理解輸入資料中細節的能力,在需要對輸入細緻理解的任務中表現不佳,同時這些模型大多存在嚴重的幻覺問題,限制了其廣泛使用。 為了解決這個問題,增強多模態大模型在更廣泛任務中的通用性,我們提出了GroundingGPT,一種能夠實現對圖片、視頻、音頻不同粒度理解的多模態模型。我們提出的模型除了捕捉全域資訊外,還擅長處理需要更精細理解的任務,例如模型能夠精確定位影像中的特定區域或影片中的特定時刻。為了實現這一目標,我們設計了多樣化的資料集建構流程,從而建構了一個多模態、多粒度的訓練資料集。在多個公開 benchmark 上的實驗證明了我們模型的通用性和有效性。
 ReFT:基於強化微調的推理
ReFT:基於強化微調的推理
論文地址:https:// arxiv.org/pdf/2401.08967 Comparison between SFT and ReFT on the presence of CoT alternatives 一種常見的增強大型語言模型(LLMs)推理能力的方法是使用思維鏈(CoT)標註數據進行有監督微調(SFT)。然而,這種方法並沒有表現出足夠強的泛化能力,因為訓練僅依賴給定的 CoT 資料。具體地,在數學問題的相關資料集中,訓練資料中每個問題通常只有一條標註的推理路徑。對於演算法來說,如果能針對一個問題學習多種標註的推理路徑,會有更強的泛化能力。 為解決這個挑戰,以數學問題為例,我們提出了一種簡單而有效的方法,稱為強化微調(Reinforced Fine-Tuning,ReFT),以增強 LLMs 推理時的泛化能力。 ReFT 首先使用SFT 對模型進行預熱,然後採用線上強化學習(在該工作中具體是PPO 演算法)進行最佳化,即對給定的問題自動採樣大量的推理路徑,根據真實答案獲取獎勵,以進一步微調模型。 在GSM8K、MathQA 和SVAMP 資料集上的大量實驗表明,ReFT 顯著優於SFT,並且透過結合多數投票和重新排序等策略,可以進一步提升模型性能。值得注意的是,這裡 ReFT 僅依賴與 SFT 相同的訓練問題,而不依賴額外或增強的訓練問題。這顯示 ReFT 具有優越的泛化能力。 期待你的互動提問
直播時間:2024 年8 月20 日(週二) 19:00-21:00 直播平台:微信視訊號碼【豆包大模型團隊】、小紅書號【豆包研究員】 歡迎你填寫問卷告訴我們,關於ACL 2024 論文你感興趣的問題,線上和多位研究員暢聊! 豆包大模型團隊持續熱招中,歡迎點擊此鏈接,了解團隊招募相關資訊。
以上是1篇Outstanding、5篇Oral!位元組跳動今年ACL這麼猛? 來直播間聊聊!的詳細內容。更多資訊請關注PHP中文網其他相關文章!























