

我們來看看這個經典的遞歸階乘:
#include
int factorial(int n)
{
int previous = 0xdeadbeef;
if (n == 0 || n == 1) {
return 1;
}
previous = factorial(n-1);
return n * previous;
}
int main(int argc)
{
int answer = factorial(5);
printf("%d\n", answer);
}
遞歸階乘 - factorial.c
函數呼叫自身的這個觀點在一開始是讓人很難理解的。為了讓這個過程更具體,下圖展示的是當呼叫 factorial(5) 並且達到 n == 1這行程式碼 時,堆疊上 端點的情況:

每次呼叫 factorial 都會產生一個新的 堆疊幀。這些堆疊幀的創建和 銷毀 是使得遞歸版本的階乘慢於其對應的迭代版本的原因。在呼叫返回之前,累積的這些堆疊幀可能會耗盡堆疊空間,進而使你的程式崩潰。
而這些擔憂經常是存在於理論上的。例如,對於每個 factorial 的堆疊幀佔用 16 位元組(這可能取決於堆疊排列以及其它因素)。如果在你的電腦上運行著現代的 x86 的 Linux 內核,一般情況下你擁有 8 GB 的棧空間,因此,factorial 程式中的 n 最多可以達到 512,000 左右。這是一個巨大無比的結果,它將花費8,971,833 位元來表示這個結果,因此,棧空間根本就不是什麼問題:一個極小的整數—— 甚至是一個64 位元的整數—— 在我們的堆疊空間被耗盡之前就早已經溢出了成千上萬次了。
過一會兒我們再去看 CPU 的使用,現在,我們先從位元和位元組回退一步,把遞歸看成一種通用技術。我們的階乘演算法可歸結為:將整數 N、N-1、 … 1 推入到一個棧,然後將它們以相反的順序相乘。實際上我們使用了程式呼叫堆疊來實現這一點,這是它的細節:我們在堆上分配一個堆疊並使用它。雖然呼叫棧具有特殊的特性,但是它也只是另一個資料結構而已,你可以隨意使用。我希望這個示意圖可以讓你明白這一點。
當你將堆疊呼叫視為一種資料結構,有些事情將變得更加清晰明了:將那些整數堆積起來,然後再將它們相乘,這並不是一個好的想法。那是一種有缺陷的實現:就像你拿螺絲起子去釘釘子一樣。相對較合理的是使用一個迭代過程去計算階乘。
但是,螺絲釘太多了,我們只能挑一個。有一個經典的面試題,在迷宮裡有一隻老鼠,你必須幫助這隻老鼠找到一個起司。假設老鼠能夠在迷宮中向左或向右轉。你該怎麼去建模來解決這個問題?
就像現實生活中的許多問題一樣,你可以將這個老鼠找起司的問題簡化為一個圖,一個二叉樹的每個結點代表在迷宮中的一個位置。然後你可以讓老鼠在任何可能的地方都左轉,而當它進入一個死胡同時,再回溯回去,再右轉。這是一個老鼠行走的 迷宮範例:
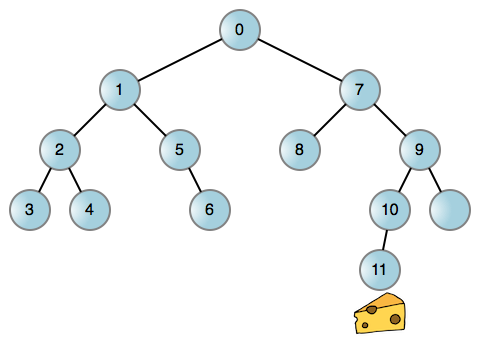
每到邊緣(線)都讓老鼠左轉或右轉到達一個新的位置。如果向哪邊轉都被攔住,表示相關的邊緣不存在。現在,我們來討論一下!這個過程無論你是呼叫堆疊還是其它資料結構,它都離不開一個遞歸的過程。而使用呼叫棧是非常容易的:
#include
#include "maze.h"
int explore(maze_t *node)
{
int found = 0;
if (node == NULL)
{
return 0;
}
if (node->hasCheese){
return 1;// found cheese
}
found = explore(node->left) || explore(node->right);
return found;
}
int main(int argc)
{
int found = explore(&maze);
}
遞歸迷宮解法 下載
當我們在 maze.c:13 中找到起司時,堆疊的情況如下圖所示。你也可以在 GDB 輸出 中看到更詳細的數據,它是使用 指令 收集的數據。

它展示了遞歸的良好表現,因為這是一個適合使用遞歸的問題。而且這並不奇怪:當涉及到演算法時,遞歸是規則,而不是例外。它出現在如下情景中——進行搜尋時、進行遍歷樹和其它資料結構時、進行解析時、需要排序時——它無所不在。正如眾所周知的 pi 或 e,它們在數學中像「神」一樣的存在,因為它們是宇宙萬物的基礎,而遞歸也和它們一樣:只是它存在於計算結構中。
Steven Skienna 的優秀著作 演算法設計指南 的精彩之處在於,他透過 「戰爭故事」 作為手段來詮釋工作,以此來展示解決現實世界中的問題背後的演算法。這是我所知道的拓展你的演算法知識的最佳資源。另一個讀物是 McCarthy 的 關於 LISP 實現的的原創論文。遞歸在語言中既是它的名字也是它的基本原理。這篇論文既可讀又有趣,在工作中能看到大師的作品是件讓人興奮的事。
Back to the maze problem. Although it is difficult to leave recursion here, it does not mean that it must be achieved through the call stack. You can use a string like RRLL to track the turn, and then use this string to determine the mouse's next move. Or you could assign something else to record the entire status of the cheese hunt. You still implement a recursive process, you just need to implement your own data structure.
That seems more complicated because stack calls are more appropriate. Each stack frame records not only the current node, but also the state of the computation on that node (in this case, whether we only let it go to the left, or have tried to go to the right). Therefore, the code has become unimportant. However, sometimes we abandon this excellent algorithm because of fear of overflow and expected performance. That's stupid!
As we can see, the stack space is very large, and other limitations are often encountered before the stack space is exhausted. On the one hand, you can check the size of the problem to ensure that it can be handled safely. The CPU concerns are driven by two widely circulated problematic examples: dumb factorial and the horrific memoryless O(2n) Fibonacci recursion. They are not correct representations of stack recursive algorithms.
In fact stack operations are very fast. Typically, the stack offset to data is very accurate, it is hot data in the cache, and specialized instructions operate on it. At the same time, the overhead associated with using your own data structures allocated on the heap is significant. It is often seen that people write implementation methods that are more complex and have worse performance than stack call recursion. Finally, the performance of modern CPUs is very good, and generally the CPU will not be the performance bottleneck. Be careful when considering sacrificing program simplicity, just as you always consider program performance and the measurement of that performance.
The next article will be the last one in the Exploring Stack series. We will learn about tail calls, closures, and other related concepts. Then, it's time to dive into our old friend, the Linux kernel. Thank you for reading!

以上是軟體開發之遞迴操作的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















