深度學習架構有很多,但近些年最成功的莫過於Transformer,其已經在多個應用領域確立了自己的主導地位。 如此成功的一大關鍵推動力是注意力機制,這能讓基於 Transformer 的模型專注於與輸入序列相關的部分,實現更好的上下文理解。但是,注意力機制的缺點是計算開銷大,會隨著輸入規模而二次成長,也因此難以處理非常長的文字。 好在前段時間誕生了一種頗具潛力的新架構:結構化的狀態空間序列模型(SSM)。該架構能有效率地捕捉序列資料中的複雜依賴關係,並由此成為 Transformer 的一大強勁對手。 這類模型的設計靈感來自經典的狀態空間模型 —— 我們可以將其視為循環神經網路和卷積神經網路的融合模型。它們可使用循環或卷積運算進行高效地計算,從而讓計算開銷隨序列長度而線性或近線性地變化,由此大幅降低計算成本。 更具體而言,SSM 最成功的變體之一Mamba 的建模能力已經可以比肩Transformer,同時還能維持隨序列長度的線性可擴展性。 Mamba 首先引入了一個簡單卻有效選擇機制,其可根據輸入對SSM 進行重新參數化,從而可讓模型在濾除不相關資訊的同時無限期地保留必要和相關的數據。然後,Mamba 還包含硬體感知型演算法,可使用掃描(scan)而非卷積來循環計算模型,這在 A100 GPU 上能讓運算速度提升 3 倍。 如圖1 所示,憑藉強大的建模複雜長序列資料的能力和近乎線性的可擴展性,Mamba 已經崛起成為一種基礎模型,並有望變革電腦視覺、自然語言處理和醫療等多個研究和應用領域。 
因此,研究和應用 Mamba 的文獻迅速增長,讓人目不暇接,一篇全面的綜述報告必定大有裨益。近日,香港理工大學的研究團隊在 arXiv 上發布了他們的貢獻。
- 論文地址:https://arxiv.org /pdf/2408.01129
這份綜述報告從多個角度對Mamba 進行了總結,既能幫助初學者學習Mamba 的基礎工作機制,也能助力經驗豐富的實務者了解最新進展。 Mamba 是一個熱門研究方向,也因此有多個團隊都在嘗試撰寫綜述報告,除了本文介紹的這篇,還有另一些關注狀態空間模型或視覺Mamba 的綜述,詳情請參閱相應論文:
Mamba-360: Survey of state space models as transformer alternative for long sequence modelling: Methods, appivgesations, and sequence modelling: Methods, appivges, and sequence modar4Xlen, appivges. :2404.16112
-
State space model for new-generation network alternative to transformers: A survey. arXiv:2404.09516
-
A survey on vision mamba: Models, applications and challenges. arXiv:2404.18861
Mamba 集中了循環神經網路(RNN)的循環框架、Transformer 的並行計算和注意力機制、狀態空間模型(SSM)的線性特性。因此,為了透徹地理解 Mamba,就必須先理解這三種架構。 循環神經網路(RNN)具有保留內部記憶的能力,因此很擅長處理序列資料。 具體來說,在每個離散時間步驟k,標準RNN 在處理一個向量時會連同前一時間步驟的隱藏狀態一起處理,之後輸出另一個向量並更新隱藏狀態。這個隱藏狀態就可作為 RNN 的記憶,其能保留過去已見過的輸入的資訊。這種動態記憶讓 RNN 可處理不同長度的序列。 也就是說,RNN 是一種非線性的循環模型,可透過使用儲存在隱藏狀態中歷史知識來有效地捕捉時間模式。 Transformer 的自註意力機制有助於捕捉輸入之中的全域依賴。其實現方式是基於每個位置相對於其它位置的重要程度為它們分配權重。更具體而言,首先對原始輸入進行線性變換,將輸入向量的序列 x 轉換成三類向量:查詢 Q、鍵 K 和值 V。 然後計算歸一化的注意力分數 S 併計算注意力權重。 除了可以執行單一注意力函數,我們還可以執行多頭注意力。這讓模型可以捕捉不同類型的關係,並從多個視角理解輸入序列。多頭注意力會使用多組自註意力模組並行地處理輸入序列。其中每個頭都獨立運作,執行的計算與標準自註意力機制一樣。 之後,將每個頭的注意力權重匯聚組合,得到值向量的加權和。這個聚合步驟可讓模型使用來自多個頭的資訊並擷取輸入序列中的多種不同模式和關係。 狀態空間模型(SSM)是一種傳統的數學框架,可用於描述系統隨時間變化的動態行為。近年來,人們已將 SSM 廣泛應用於控制論、機器人和經濟學等多個不同領域。 究其核心,SSM 是透過一組名為「狀態」的隱藏變數來體現系統的行為,使其能有效捕捉時間資料的依賴關係。不同於 RNN,SSM 是一種具有關聯(associative)屬性的線性模型。具體來說,經典的狀態空間模型會建構兩個關鍵方程式(狀態方程式和觀察方程式),以透過一個N 維的隱藏狀態h (t) 建模當前時間t 時輸入x 與輸出y 之間的關係。
- 為了滿足機器學習的需求,SSM 必需經歷一個離散化過程- 將連續參數轉變成離散參數。通常來說,離散化方法的目標是將連續時間劃分為具有盡可能相等積分面積的 K 個離散區間。為了實現這一目標,SSM 採用的最具代表性的解決方案之一是Zero-Order Hold(ZOH),其假設區間Δ = [?_{?−1}, ?_? ] 上的函數值保持不變。離散 SSM 與循環神經網路結構相似,因此離散 SSM 能比基於 Transformer 的模型更有效率地執行推理過程。
RNN、Transformer 和SSM 之間的關係
圖2 展示了RNN、Transformer 和SSM 的計算演算法.
一方面,常規 RNN 的運作是基於一種非線性的循環框架,其中每個計算都僅依賴先前的隱藏狀態和當前輸入。 儘管這種形式可讓RNN 在自迴歸推理時快速產生輸出,但它也讓RNN 難以充分利用GPU 的平行運算能力,導致模型訓練速度變慢。 另一方面,Transformer 架構是在多個「查詢- 鍵」對上並行執行矩陣乘法,而矩陣乘法可以高效地分配給硬體資源,從而更快地訓練基於注意力的模型。但是,如果要讓基於 Transformer 的模型產生回應或預測,則推理過程會非常耗時。 不同於僅支援一類計算的RNN 和Transformer,離散SSM 彈性很高;得益於其線性性質,它既能支援循環計算,也可支援卷積計算。這種特性讓 SSM 不僅能達到高效推理,也能達到並行訓練。但是,需要指出,最常規的 SSM 是時不變的,也就是說其 A、B、C 和 Δ 與模型輸入 x 無關。這會限制其上下文感知型建模的能力,導致 SSM 在選擇性複製等一些特定任務上表現不佳。 Mamba-1:使用硬體感知型演算法的選擇式狀態空間模型Mamba-1 基於結構化狀態空間模型引入了三大創新技術,即基於高階多項式投影算子(HiPPO)的記憶體初始化、選擇機制和硬體感知型計算。如圖 3 所示。這些技術的目標是提升 SSM 的長程線性時間序列建模能力。
具體來說,其中的初始化策略可建立一個連貫的隱藏狀態矩陣,以有效地促進長程記憶。 然後,選擇機制讓 SSM 有能力獲得可感知內容的表徵。 最後,為了提升訓練效率,Mamba 還包含兩種硬體感知型計算演算法:Parallel Associative Scan(平行關聯掃描)和 Memory Recomputation(記憶體重新計算)。 Transformer 啟發了多種不同技術的發展,如參數高效型微調、災難性遺忘緩解、模型量化。為了讓狀態空間模型也能受益於這些原本為 Transformer 開發的技術,Mamba-2 引進了一個新框架:結構化狀態空間對偶(SSD)。這個框架在理論上將 SSM 和不同形式的注意力連接到了一起。 本質上講,SSD 表明,Transformer 使用的注意力機制和 SSM 中使用的線性時不變系統都可被視為半可分離的矩陣變換。 此外,Albert Gu 和 Tri Dao 也證明選擇式 SSM 等價於使用一種半可分離掩碼矩陣實現的結構化線性注意力機制。 Mamba-2 基於 SSD 設計了一種能更有效率使用硬體的計算方法,這要用到一種區塊分解矩陣乘法演算法。 具體來說,透過這種矩陣變換將狀態空間模型視為半可分離矩陣,Mamba-2 能將此計算分解為矩陣區塊,其中對角線塊表示塊內計算。而非對角塊則表示透過 SSM 的隱藏狀態分解的區塊間計算。此方法可讓 Mamba-2 的訓練速度超過 Mamba-1 的平行關聯掃描的 2-8 倍,同時效能還能媲美 Transformer。 下面來看看Mamba-1 和Mamba-2 的塊設計。圖 4 比較了這兩種架構。
Mamba-1 的設計是以 SSM 為中心,其中選擇式 SSM 層的任務是執行從輸入序列 X 到 Y 的對應。在這種設計中,經過了初始的創建 X 的線性投射之後,會使用 (A, B, C) 的線性投射。然後,輸入 token 和狀態矩陣會透過選擇式 SSM 單元,利用平行關聯掃描,從而得到輸出 Y。之後,Mamba-1 採用了一個 skip 連接,以鼓勵特徵復用和緩解常在模型訓練過程中發生的性能下降問題。最後,透過交錯地堆疊此模組與標準歸一化和殘差連接,便可建構出 Mamba 模型。 至於 Mamba-2,則是引入了 SSD 層來創建從 [X, A, B, C] 到 Y 的映射。其實現方式是在區塊的起點處使用單一投射來同時處理 [X, A, B, C],這類似於標準注意力架構以並行方式產生 Q、K、V 投射的方式。 也就是說,透過移除序列線性投射,Mamba-2 區塊是在 Mamba-1 區塊的基礎上進行了簡化。這能讓 SSD 結構的計算速度超過 Mamba-1 的平行選擇式掃描。此外,為了提升訓練穩定性,Mamba-2 在 skip 連線之後也加入了一個歸一化層。 狀態空間模型與近空間模型與猛迅猛來發展已成為了一大極具潛力的基礎模型骨幹網路選擇。儘管 Mamba 在自然語言處理任務上表現不俗,但也仍具有一些難題,例如記憶遺失、難以泛化到不同任務、在複雜模式方面的表現不如基於 Transformer 的語言模型。為了解決這些難題,研究社群為 Mamba 架構提出了許多改進方案。現有的研究主要集中在修改區塊設計、掃描模式和記憶管理。表 1 分類總結了相關研究。
Mamba 區塊的設計與結構對Mamba有很大的影響,也因此這成為了一大研究熱點。
如圖5 所示,基於建構新Mamba 模組的不同方法,現有研究可以分為三類:
- 整合方法:將Mamba 區塊與其它模型整合在一起,實現效果與效率的平衡;
- 替換方法:用Mamba 區塊取代其它模型框架中的主要層;
- 🎜>內的一大關鍵元件,其目標是解決由選擇機制導致的運算問題、提升訓練過程速度、降低記憶體需求。其實現方式是利用時變的 SSM 的線性性質來在硬體層級上設計核融合和重新計算。但是,Mamba 的單向序列建模範式不利於全面學習多樣化的數據,例如影像和影片。
為緩解這一問題,一些研究者探索了新的高效掃描方法,以提升 Mamba 模型的性能以及促進其訓練過程。如圖6 所示,在發展掃描模式方面,現有的研究成果可分為兩類:
展平式掃描方法:以展平的視角看待token 序列,並基於此處理模型輸入;
立體式掃描方法:跨維度、通道或尺度掃描模型輸入,這又可進一步分為三類別:分層掃描、時空掃描、混合掃描。
記憶管理
類似RN🎜>類似於RNN,在狀態在空間模型內,隱藏狀態的記憶有效地儲存了先前步驟的訊息,因此對SSM 的整體表現有著至關重要的影響。儘管 Mamba 引入了基於 HiPPO 的方法來進行記憶初始化,但管理 SSM 單元中的記憶仍然難度很大,其中包括在層之前轉移隱藏資訊以及實現無損記憶壓縮。
為此,一些開創性研究提出了一些不同的解決方案,包括記憶的初始化、壓縮和連接。
讓Mamba 適應多樣化的資料
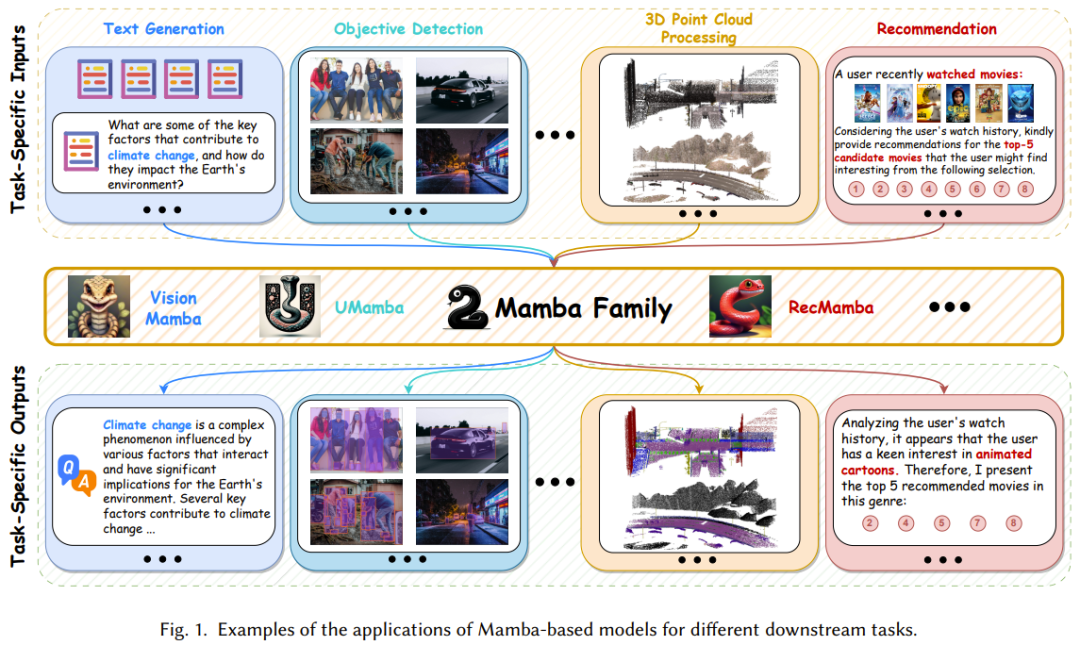
Mamba 架構是選擇式狀態模型的一種擴展,其具備循環模型的基本特性,因而非常適合作為處理文字、時間序列、語音等序列資料的通用基礎模型。 不僅如此,近期一些開創性研究更是擴展了Mamba 架構的應用場景,使其不僅能處理序列數據,還能用於影像和圖譜等領域,如圖7 所示。 這些研究的目標是既充分利用 Mamba 能獲得長程依賴關係的優秀能力,也讓其發揮學習和推理過程中的效率優勢。表 2 簡單總結了這些研究成果。
序列資料是指以特定順序收集和整理的數據,其中資料點的順序具有重要意義。這份綜述報告全面總結了 Mamba 在多種序列資料上的應用,包括自然語言、視訊、時間序列、語音和人體運動資料。詳見原論文。 不同於序列資料,非序列資料並不遵循序列資料,非序列資料並不遵循序列資料特定的順序。其數據點可以任意順序進行組織而不會對數據的含義造成顯著影響。對於專門設計用於擷取資料中時間依賴關係的循環模型(RNN 和 SSM 等)來說,這種缺乏固有順序的資料會很難處理。 令人驚訝的是,近期的一些研究成功讓Mamba(代表性的SSM)實現了對非序列資料的高效處理,包括影像、圖譜和點雲端數據。 為了提升AI 的感知和場景理解能力,可以整合多個模態的數據,例如語言(序列數據)和圖像(非序列數據)。這樣的整合能提供非常有價值且補充性的資訊。 近段時間來,多模態大型語言模型(MLLM)是最受關注的研究熱點;這類模型繼承了大型語言模型(LLM)的強大能力,包括強大的語言表達和邏輯推理能力。儘管Transformer 已經成為該領域的主導方法,但Mamba 也正在崛起成為一大強勁競爭者,其在對齊混合源數據和實現序列長度的線性複雜度擴展方面表現出色,這使Mamba 有望在多模態學習方面替代Transformer。 以下介紹基於 Mamba 的模型的一些值得注意的應用。團隊將這些應用分為了以下類別:自然語言處理、電腦視覺、語音分析、藥物發現、推薦系統以及機器人和自主系統。 Mamba 雖然已經在一些領域取得了出色表現,但整體而言,Mamba 研究仍處於起步階段,前方仍有一些挑戰有待克服。當然,這些挑戰同時也是機會。
- 如何充分實現硬體感知型計算,以盡可能利用GPU 和TPU 等硬件,提升模型效率;
- 如何提升Mamba 模型的可信度,這需要安全和穩健性、公平性、可解釋性以及隱私方面的進一步研究;
- 如何將Transformer 領域的新技術用於Mamba,如參數高效型微調、災難性遺忘緩解、檢索增強式生成(RAG)。
以上是一文看懂Mamba,Transformer最強競爭者的詳細內容。更多資訊請關注PHP中文網其他相關文章!


 RNN、Transformer 和SSM 之間的關係
RNN、Transformer 和SSM 之間的關係 Mamba-1 基於結構化狀態空間模型引入了三大創新技術,即基於高階多項式投影算子(HiPPO)的記憶體初始化、選擇機制和硬體感知型計算。如圖 3 所示。這些技術的目標是提升 SSM 的長程線性時間序列建模能力。
Mamba-1 基於結構化狀態空間模型引入了三大創新技術,即基於高階多項式投影算子(HiPPO)的記憶體初始化、選擇機制和硬體感知型計算。如圖 3 所示。這些技術的目標是提升 SSM 的長程線性時間序列建模能力。 



























