AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
單元測試是軟體開發流程中的關鍵環節,主要用於🎜>單元測試是軟體開發流程中的關鍵環節,主要用於驗證軟體中的最小可測試單元,函數或模組是否如預期運作。單元測試的目標是確保每個獨立的程式碼片段都能正確執行其功能,對於提高軟體品質和開發效率具有重要意義。 然而,大模型本身無力為複雜待測函數(環複雜度大於 10)產生高覆蓋率的測試範例集。為了解決這個痛點,北京大學李戈教授團隊提出一種全新的提升測試案例覆蓋率的方法,該方法借助程序分片思想(Method Slicing),將複雜待測函數依據語義拆解為若干簡單片段,進而讓大模型為各個簡單片段分別產生測試範例。產生單一測試範例時,大模型只需分析原待測函數的片段,分析難度減小,產生覆蓋該片段的單元測試難度隨之減少。由此推廣,提升整體測試範例集程式碼覆蓋率。 相關論文《HITS: High-coverage LLM-based Unit Test Generation via Method Slicing》近期被ASE 2024(at the 39th IEEE/ACM International Conference Software on Automated Software Engineering )頂會接受。 
論文網址:https://www.arxiv.org/pdf/2408.11324
程序分片指將一個程序依據語意劃分為若干解決問題的階段。程序是對一個問題解決方案的形式化表述。一個問題解決方案通常包含多個步驟,每個步驟對應著程式中的一片(slice)程式碼。如下圖所示,一個色塊對應著一片程式碼,也對應著一個問題解決的步驟。
HITS 要求大模型分別為每個程式碼片設計可以有效率地覆蓋它的單元測試程式碼。以上圖為例,當我們得到如圖的分片後,HITS 要求大模型為 Slice 1(綠色),Slice 2(藍色),Slice 3(紅色)分別產生測試範例。為 Slice 1 產生的測試範例要盡可能覆蓋 Slice 1,不用考慮 Slice 2 和 Slice 3,其餘程式碼片同理。 HITS 起效的原因有二。其一,大模型要考慮涵蓋的程式碼量降低。以上圖為例,為 Slice 3 產生測試範例,只需考慮 Slice 3 中的條件分支。要覆寫 Slice 3 中的某些條件分支,只需在 Slice 1 和 Slice 2 中找尋一條執行路徑即可,無需考慮該執行路徑對 Slice 1 和 Slice 2 覆蓋率的影響。其二,依據語意(問題解決步驟)分割的程式碼片有助於大模型掌握程式碼執行中間狀態。為順序靠後的程式碼區塊產生測試範例,需要考慮先前程式碼對程式狀態的改變。由於程式碼區塊依據實際問題解決步驟分割,因此可以用自然語言對先前程式碼區塊的操作進行描述(如上圖註釋部分)。由於目前大語言模型多為自然語言與程式語言混合訓練產物,良好的自然語言概括可幫助大模型更精準掌握程式碼對程式狀態的改變。 HITS 使用大模型進行程式分片。問題的解決步驟通常為帶有程式設計師主觀色彩的自然語言表述,因而可以直接利用自然語言處理能力超群的大模型。具體而言,HITS 使用上下文學習方法(In-context learning) 呼叫大模型。團隊利用過往在真實場景實踐的經驗,手工編寫若干程序分片樣例,經若干次調整後使大模型對程序分片的效果達到了研究團隊的預期。 給定要覆蓋的程式碼片段,要產生對應測試範例,需經歷以下3 個步驟:1. 對片段的輸入進行分析;2. 構造prompt 指示大模型產生初始測試樣例;3. 使用規則後處理和大模型self-debug 調整測試範例使之可以正確運作。 對片段的輸入進行分析,指提取要覆蓋的片段所接受的一切外部輸入,以備後續 prompt 使用。外部輸入,指該片段所應用到的先前片段定義的局部變量,待測方法的形參,片段內調用的方法以及外部變量。外部輸入的值直接決定了要覆蓋的片段的執行情況,因此將該資訊提取出來提示給大模型有助於有針對性地設計測試樣例。研究團隊在實驗中發現大模型擁有良好的提取外部輸入的能力,因此在 HITS 中由大模型來完成該任務。 接下來,HITS 建構思維鏈(Chain-of-thought)形式的 prompt 引導大模型產生測試範例。推理步驟如下。第一步,給定外部輸入,分析要滿足待覆蓋代碼片內的各種條件分支的排列組合,外部輸入都分別需要滿足哪些性質,如:組合1,字符串a 需要包含字符'x',整數變數i 需要非負;組合2,字串a 需要非空,整數變數i 需要為質數。第二步,對上一個步驟中的每一種組合,分析相對應的待測程式碼執行時所處環境的性質,包括但不限於實參的特性,全域變數的設定。第三步,為每一種組合產生一個測試範例。研究團隊為每一步手動建立了範例,以便於大模型能夠正確理解並執行指令。 最後,HITS 透過後處理和 self-debug 使大模型產生的測試樣本得以正確運作。大模型產生的測試範例往往難以直接使用,會出現各式各樣的編譯錯誤和來自於錯誤編寫測試範例所導致的執行時間錯誤。研究團隊根據自身觀察及已有論文的總結,設計了若干規則和常見錯誤的修復案例。首先嘗試依據規則修復。如果規則無法修復,則使用大模型 self-debug 的功能進行修復,在 prompt 中提供了常見錯誤的修復案例以供大模型參考。 
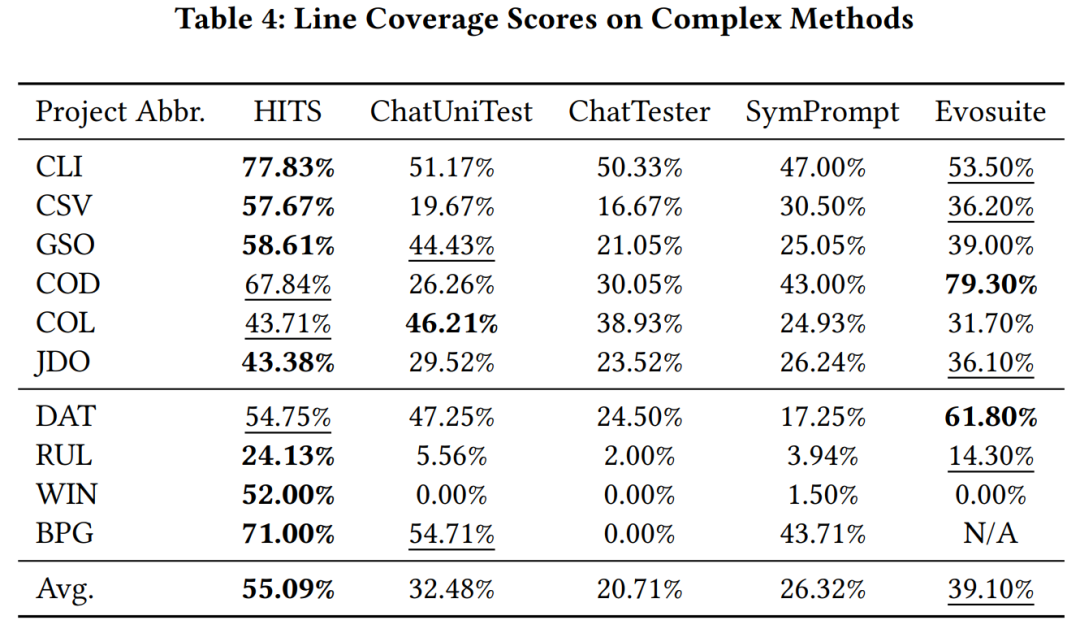
The overall illustration of Hits Experimental verification The research team uses gpt-3.5-turbo as the large model called by HITS, and compares HITS on complex functions (cyclocomplexity greater than 10) in Java projects that have been learned by large models and those that have not been learned. Other large model-based unit testing methods and code coverage with evosuite. Experimental results show that HITS has significant performance improvements compared with the compared methods.


How to analyze the sample and display the slice method of how Improve code coverage. As shown in the picture.
In this case, the test sample generated by the baseline method failed to fully cover the red code fragment in Slice 2. However, because HITS focused on Slice 2, it analyzed the external variables it referenced and captured the property that "if you want to cover the red code fragment, the variable 'arguments' needs to be non-empty", and built a test sample based on this property. Successfully achieved coverage of red area codes.
Improve unit test coverage, enhance system reliability and stability, and thereby improve software quality. HITS uses program sharding experiments to prove that this technology can not only greatly improve the code coverage of the overall test sample set, but also has a simple and direct implementation method. In the future, it is expected to help teams discover and correct development errors earlier in real-life scenario practice, improving Software delivery quality.
以上是北大李戈团队提出大模型单测生成新方法,显著提升代码测试覆盖率的詳細內容。更多資訊請關注PHP中文網其他相關文章!























