

編輯| ScienceAI
近日,上海交通大學、上海AI Lab、中國移動等機構的聯合研究團隊,在arXiv 預印平台上發布文章《Towards Evaluating and Building Versatile Large Language Models for Medicine》,從數據、測評、模型多個角度全面分析討論了臨床醫學大語言模型應用。
文中所涉及的所有資料和程式碼、模型都已開源。

概覽
近年來,大型語言模型(LLM)取得了顯著的進展,並在醫療領域取得了一定成果。這些模型在醫學多項選擇問答(MCQA)基準測試中展現出高效的能力,並且 UMLS 等專業考試中達到或超過專家水平。 然而,LLM 距離實際臨床場景中的應用仍然有相當長的距離。其主要問題,集中在模型在處理基本醫學知識方面的不足,如在解讀ICD 編碼、預測臨床程序以及解析電子健康記錄(EHR)數據方面的誤差。
這些問題指向了一個關鍵:目前的評估基準主要關注醫學考試選擇題,而不能充分反映 LLM 在真實臨床情境中的應用。 本研究提出了一項新的評估基準MedS-Bench,該基準不僅包括多項選擇題,還涵蓋了臨床報告摘要、治療建議、診斷和命名實體識別等11 項高級臨床任務。 研究團隊透過此基準對多個主流的醫療模型進行了評估,發現即便是使用了few-shot prompting,最先進模型,例如,GPT-4,Claude 等,在處理這些複雜的臨床任務時也面臨困難。
為解決這個問題,受到Super-NaturalInstructions 的啟發,研究團隊建立了首個全面的醫學指令微調資料集MedS-Ins,該資料集整合了來自考試、臨床文本、學術論文、醫學知識庫及日常對話的58 個生物醫學文本資料集,包含超過1,350 萬個樣本,涵蓋了122 個臨床任務。 在此基礎上,研究團隊對開源醫學語言模型進行指令調整,探討了 in-context learning 環境下的模型效果。 該工作中開發的醫學大語言模型——MMedIns-Llama 3,在多種臨床任務中的表現超過了現有的領先閉源模型,如 GPT-4 和 Claude-3.5。 MedS-Ins 的構建極大的促進了醫學大語言模型在實際臨床場景的中的能力,使其應用範圍遠超在線聊天或多項選擇問答的限制。 相信這項進展不僅推動了醫學語言模型的發展,也為未來臨床實踐中的人工智慧應用提供了新的可能性。測試基準資料集(MedS-Bench)
為了評估各種LLM 在臨床應用中的能力,研究團隊開發了MedS -Bench,這是一個超越傳統選擇題的綜合醫學基準。如下圖所示,MedS-Bench 源自 39 個現有資料集,涵蓋 11 個類別,總共包含 52 個任務。 在 MedS-Bench 中,資料被重新格式化為指令微調的結構。此外,每條任務都配有人工標註的任務定義。涉及的11 個類別分別是:選擇題解答(MCQA)、文本摘要(Text Summarization)、資訊擷取(Information Extraction)、解釋與推理(Explanation and Rationale)、命名實體辨識(NER) 、診斷(Diagnosis)、治療計畫規劃(Treatment Planning)、臨床結果預測(Clinical Outcome Prediction)、文本分類(Text Classification)、事實驗證(Fact Verification)和自然語言推理(NLI)。
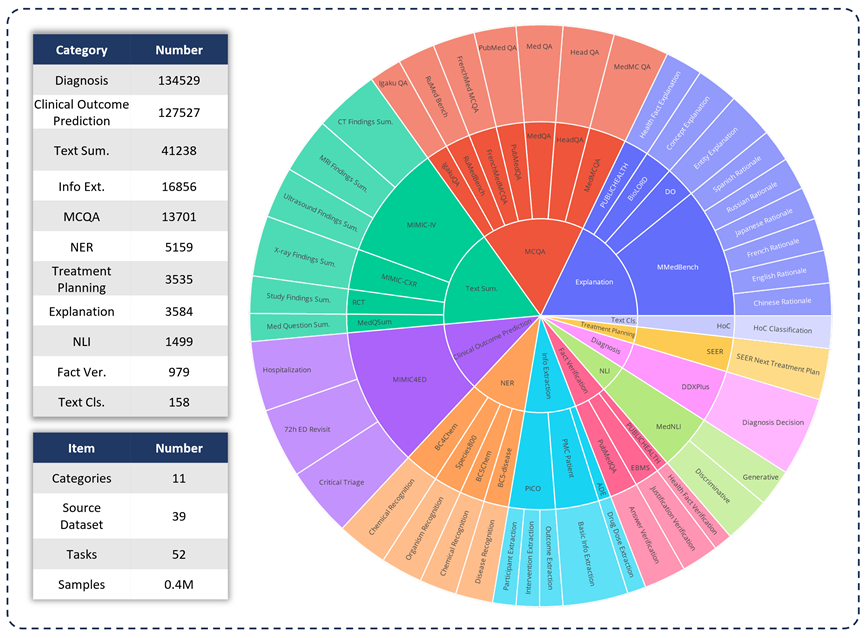
除了定義這些任務類別,研究團隊還對 MedS-Bench 文本長度進行了詳細的統計,並區分了 LLM 處理不同任務所需的能力,如下表所示。 LLM 處理任務所需的能力被分為兩類:(i)根據模型內部知識進行推理;(ii) 從提供的上下文中檢索事實。
廣義上講,前者涉及的任務需要從大規模預訓練中獲取編碼在模型權重中的知識,而後者涉及的任務則需要從所提供的上下文中提取信息,如總結或信息提取。如表 1 所示,總共有八類任務要求模型從模型中呼叫知識,而其餘三類任務則要求從給定上下文中檢索事實。
表 1:所用測試任務的詳細統計資料。

指令微調資料集(MedS-Ins)
此外,研究團隊還開源了指令微調資料集MedS-Ins。此資料集涵蓋 5 個不同的文字來源和 19 個任務類別,共 122 個不同的臨床任務。下圖總結了 MedS-Ins的構造流程以及統計資料。
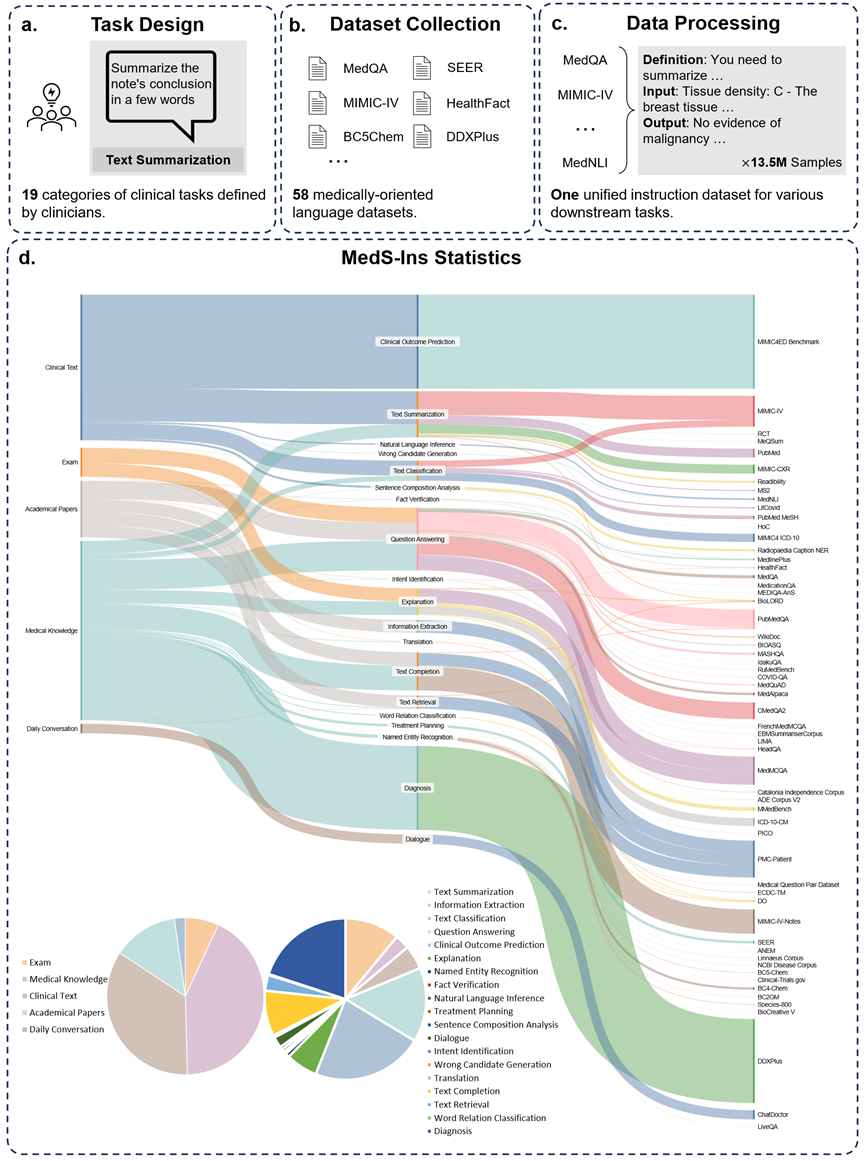
文字來源
本文提出的指令微調資料集由五個不同來源的樣本組成:考試、臨床文本、學術論文、醫學知識庫和日常對話。
考試:此類別包含來自不同國家醫學考試試題的數據。它涵蓋了從基本醫學常識到複雜臨床手續廣泛的醫學知識。考試題目是了解和評估醫學教育程度的重要手段,然而值得注意的是,考試的高度標準化往往導致其案例與真實世界的臨床任務相比過於簡化。資料集中 7% 的資料來自考試。
臨床文本:此類別文本在常規臨床實踐中產生,包括醫院和臨床中心的診斷、治療和預防過程。這類文本包括電子健康記錄 (EHR)、放射報告、化驗結果、追蹤指導和用藥建議等。這些文本是疾病診斷和患者管理所不可或缺的,因此準確的分析和理解對於 LLM 的有效臨床應用至關重要。資料集中 35% 的資料來自臨床文本。
學術論文:此類別資料源自醫學研究論文,涵蓋了醫學研究領域的最新發現和進展。由於學術論文便於獲取和結構化組織,從學術論文中提取數據相對簡單。這些數據有助於模型掌握最前沿的醫學研究訊息,引導模型更好地理解當代醫學的發展。資料集中有 13% 的資料來自學術論文。
醫學知識庫:此類別資料由組織良好的綜合醫學知識組成,包括醫學百科全書、知識圖譜和醫學術語詞彙表。這些數據構成了醫學知識庫的核心,為醫學教育和 LLM 在臨床實踐中的應用提供了支持。資料集中 43% 的資料來自醫學知識。
日常對話:此類別資料指的是醫師與病患之間產生的日常諮詢、主要來自線上平台和其他互動場景。這些數據反映了醫護人員與病患之間的真實互動、在了解病患需求、提升整體醫療服務體驗方面發揮著至關重要的作用。資料集中有 2% 的資料來自日常對話。
任務種類
除了對文本涉及領域進行分類外,研究團隊對MedS-Ins 中樣本的任務類別進行進一步細分:確定了19 個任務類別,每個類別都代表了醫學大語言模型應具備的關鍵能力。透過建構此指令微調資料集並相應微調模型,使大語言模型具備處理醫療應用所需的多種能力,具體如圖 2 所示。
MedS-Ins 中的 19 個任務類別包括但不限於 MedS-Bench 基準中的 11 個類別。額外的任務類別涵蓋了醫學領域所必需的一系列語言和分析任務,包括意圖識別、翻譯、單字關係分類、文本檢索、句子成分分析、錯誤候選詞生成、對話和文本補齊,而MCQA 則擴展為一般的問答。任務類別的多樣性—從普通問答和對話到各種下游臨床任務,保證了對醫療應用的全面理解。
量化對比
研究團隊廣泛地測試了現存六大主流模型(MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4 and Claude-3.5)在每種任務類型上的表現,首先討論各種現有LLM 的效能,然後與提出的最終模型MMedIns-Llama 3 進行比較。在本文中,所有結果都是使用 3-shot Prompt 得出的。除了在 MCQA 任務中使用了 zero-shot Prompt,以便與先前的研究保持一致。由於 GPT-4 和 Claude 3.5 等閉源模型會產生費用,受限於成本,實驗中僅對每個任務抽樣 50-100 個測試案例,全面的測試量化結果如表 2-8 所示。
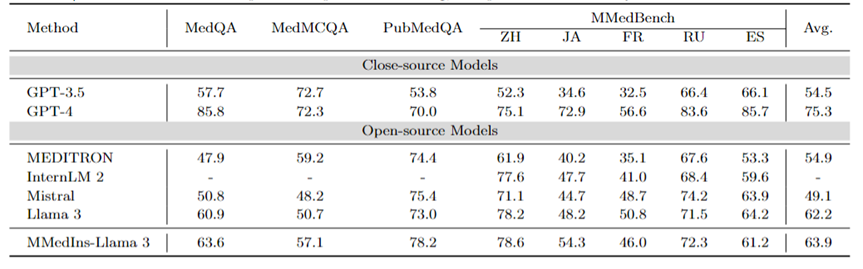
多語言多選題問答:表 2 以「Accuracy」展示了廣泛使用的 MCQA 基準上的評估結果。在這些多選題問答資料集上,現有的大語言模型都表現出了非常高的準確率,例如,在MedQA 上,GPT-4 可以達到85.8 分,幾乎可以與人類專家相媲美,而Llama 3 也能以60.9 分通過考試。同樣,在英語以外的語言方面,LLM 在 MMedBench 上的多重選擇準確率也表現出優異的成績。
結果表明,由於多選題在現有研究中已被廣泛考慮,不同的 LLM 可能已針對此類任務進行了專門優化,從而獲得了較高的性能。因此,有必要建立一個更全面的基準、 以進一步推動 LLM 向臨床應用發展。
表2:選擇題上的量化結果,各項指標以選擇準確率ACC來衡量。
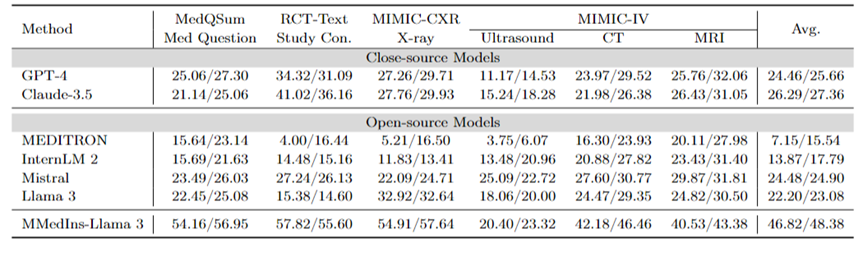
文本總結:表 3 以 “BLEU/ROUGE ”分數的形式報告了不同語言模型在文本總結任務上的表現。測試涵蓋了多種報告類型,包括 X 光、CT、MRI、超音波和其他醫療問題。實驗結果表明,GPT-4 和 Claude-3.5 等閉源大語言模型的表現優於所有開源大語言模型。
在開源模型中,Mistral 的結果最好,BLEU/ROUGE 分別為 24.48/24.90,Llama 3 緊跟在後,為 22.20/23.08。
本文提出的MMedIns-Llama 3 是在特定醫療教學資料集(MedS-Ins)上訓練出來的,其表現明顯優於其他模型,包括先進的閉源模型GPT-4 和Claude- 3.5,平均得分達46.82/48.38。
表 3:文本總結任務上的量化結果。
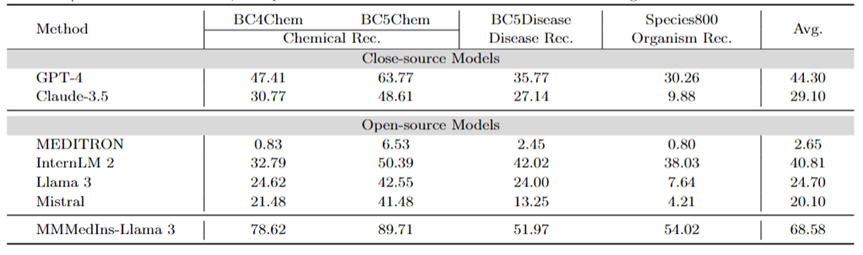
資訊擷取:表 4 以「Accuracy」展示了不同模型資訊擷取的效能。 InternLM 2 在這項任務中表現優異,平均得分為 81.58,GPT-4 和 Claude-3.5 等閉源模型的平均得分分別為 77.49 分和 78.86 分,優於所有其他開源模型。
對單一任務結果的分析表明,與專業的醫療數據相比,大多數大語言模型在提取病人基本資訊等不太複雜的醫療資訊方面表現更好。例如,在從 PMC 患者中提取基本資訊方面,大多數大語言模型的得分都在 90 分以上,其中 Claude-3.5 的得分最高,達到 98.02 分。相較之下,PICO 中臨床結果提取任務的表現則相對較差。本文提出的模型 MMedIns-Llama 3 整體表現最佳,平均得分 83.18,超過 InternLM 2 模型 1.6 分。
表 4:資訊擷取任務上的量化結果,各項指標以準確度(ACC)進行衡量。 「Ext.」表示Extraction,「Info.」表示 Information。
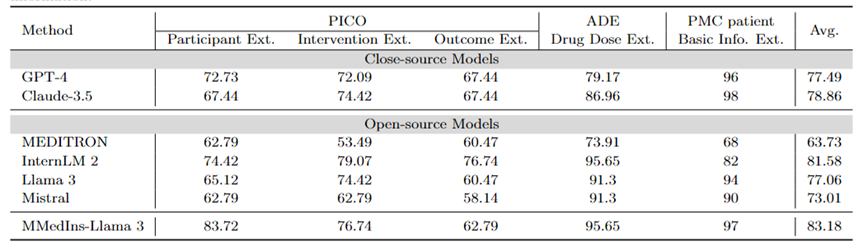
醫學概念解釋:表5 以「BLEU/ROUGE 」分數的形式展示了不同模型醫學概念解釋能力,GPT-4,Llama 3和Mistral 在這項任務中表現良好。
対照的に、Claude-3.5、InternLM 2、MEDITRON のスコアは比較的低いです。 MEDITRON のパフォーマンスが比較的低いのは、そのトレーニング コーパスが学術論文やガイドラインに重点を置いているため、医学的概念を説明する能力が欠けていることが原因である可能性があります。
最終モデル MMedIns-Llama 3 は、すべての概念説明タスクにおいて他のモデルよりも大幅に優れたパフォーマンスを発揮します。
表 5: 医学概念の説明に関する定量的結果、各指標は BLEU-1/ROUGE-1 によって測定されます。
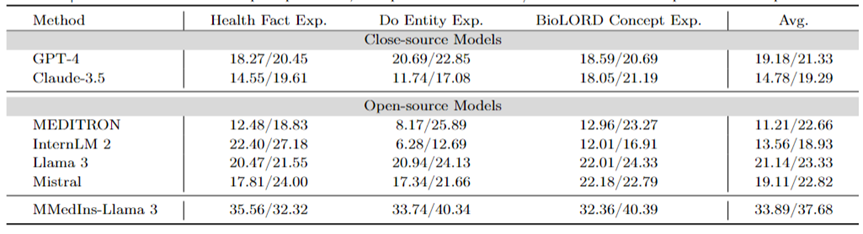
アトリビューション分析 (根拠): 表 6 は、アトリビューション分析タスクにおける各モデルのパフォーマンスを「BLEU/ROUGE」スコアの形式で評価します。 MMedBench データセットを使用して、6 つの言語におけるさまざまなモデルのパフォーマンス、推論機能を比較しました。
テストされたモデルの中で、クローズドソース モデルの Claude-3.5 が最も強力なパフォーマンスを示し、平均スコアは 46.03/37.65 でした。この優れたパフォーマンスは、多くの汎用 LLM で特に強化されている COT の生成とタスクの類似性によるものと考えられます。
オープンソース モデルの中で、Mistral と InternLM 2 は同等のパフォーマンスを示し、平均スコアはそれぞれ 37.61/31.55 と 30.03/26.44 でした。特に、MMedBench データセットのアトリビューション分析部分では主に GPT-4 を使用してビルドを生成するため、GPT-4 がこの評価から除外されました。これにより、テストのバイアスが生じ、不公平な比較につながる可能性があります。
概念説明タスクのパフォーマンスと一致して、最終モデル MMedIns-Llama 3 も全体として最高のパフォーマンスを示し、すべての言語の平均スコアは 47.17/34.96 でした。この優れたパフォーマンスは、選択された基本言語モデル (MMed-Llama 3) が元々複数の言語用に開発されたという事実によるものと考えられます。したがって、命令チューニングが明示的に多言語データをターゲットにしていない場合でも、最終モデルは依然として複数言語の他のモデルよりも優れたパフォーマンスを発揮します。
表 6: アトリビューション分析の定量的結果 (根拠)。各指標は BLEU-1/ROUGE-1 によって測定されます。元のデータは GPT-4 の生成結果に基づいて構築されており、公平性バイアスがあるため、GPT-4 は比較されません。
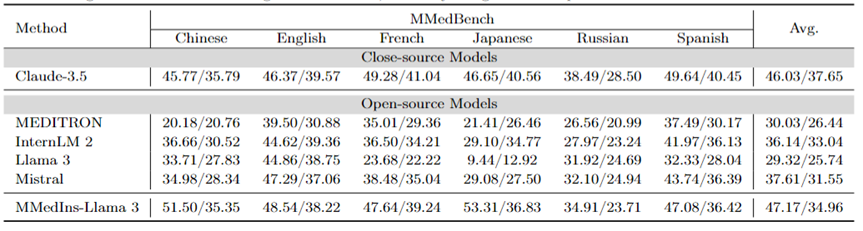
医療エンティティ抽出 (NER): 表 7 は、NER タスクの既存の 6 つのモデルを「F1」スコア パフォーマンスの形式でテストします。 GPT-4 は、すべての固有表現認識 (NER) タスクにわたって良好なパフォーマンスを発揮する唯一のモデルであり、平均 F1 スコアは 44.30 です。
BC5Chem 化学物質認識タスクで特に優れたパフォーマンスを示し、スコアは 63.77 でした。 InternLM 2 は平均 F1 スコア 40.81 でそれに続き、BC5Chem タスクと BC5Disease タスクの両方で良好なパフォーマンスを示しました。ラマ 3 とミストラルの平均 F1 スコアはそれぞれ 24.70 と 20.10 で、平均的なパフォーマンスです。 MEDITRON は NER タスク用に最適化されていないため、この分野ではパフォーマンスが低下します。 MMedIns-Llama 3 は他のすべてのモデルよりも大幅に優れたパフォーマンスを示し、平均 F1 スコアは 68.58 でした。
表 7: NER タスクの定量的結果。各指標は F1 スコアによって測定されます。「Rec.」は「認識」を表します。
診断、治療推奨、および臨床転帰予測: 表 8 診断ベンチマークとして DDXPlus データセット、治療推奨ベンチマークとして SEER データセット、および臨床転帰予測タスク ベンチマークとして MIMIC4ED データを使用した診断、治療推奨、および臨床転帰の評価表 8 に示すように、3 つの主要なタスクのモデルのパフォーマンスが予測され、結果は精度によって測定されます。
ここでは、これらのデータセットのそれぞれが元の問題を閉集合上の選択問題に還元するため、精度メトリクスを使用して生成された予測を評価できます。具体的には、DDXPlus は事前定義された疾患のリストを使用し、モデルは提供された患者の背景に基づいて疾患を選択する必要があります。 SEER では、推奨される治療法は 8 つの高レベルのカテゴリに分類されますが、MIMIC4ED では、最終的な臨床転帰の決定は常に 2 値 (True または False) で行われます。
全体的に、オープン ソース LLM は、これらのタスクに関してクローズ ソース LLM よりもパフォーマンスが悪く、場合によっては意味のある予測を提供できないこともあります。たとえば、Llama 3 は重大なトリアージの予測においてパフォーマンスが悪くなります。 DDXPlus 診断タスクでは、InternLM 2 と Llama 3 のパフォーマンスがわずかに向上し、精度は 32 でした。ただし、GPT-4 や Claude-3.5 などのクローズドソース モデルは、大幅に優れたパフォーマンスを示します。たとえば、Claude-3.5 は SEER で 90 の精度を達成できますが、GPT-4 は DDXPlus でより高い診断精度を持ち、スコアは 52 であり、オープン ソースとクローズド ソースの LLM の間に大きなギャップがあることが強調されています。
これらの結果にもかかわらず、これらのスコアは臨床使用に十分な信頼性がまだありません。対照的に、MMedIns-Llama 3 は、SEER で 98、DDXPlus で 95 など、臨床意思決定支援タスクで優れた精度を示し、臨床転帰予測タスク (入院、救急外来再診の 72 時間平均、重要トリアージ スコア) で平均精度 86.67 を示しました。 )。
テキスト分類: 表 8 には、HoC マルチラベル分類タスクの評価も示されており、マクロ精度、マクロ再現率、およびマクロ F1 スコアが報告されています。このタイプのタスクでは、すべての候補ラベルがリストの形式で言語モデルに入力され、モデルは対応する回答を選択するよう求められます (複数の選択肢が許可されています)。次に、モデルの最終選択出力に基づいて精度メトリクスが計算されます。
GPT-4 と Claude-3.5 はこのタスクで優れたパフォーマンスを示し、GPT-4 の Macro-F1 スコアは 60.38 で、Claude-3.5 はさらに優れており、63.32 を達成しています。どちらのモデルも強力なリコール能力を示しており、特に Claude-3.5 のマクロリコールは 80.96 です。 Mistral は、Macro-F1 スコア 40.8 で中程度のパフォーマンスを示し、精度と再現率のバランスをとりました。
対照的に、Llama 3 と InternLM 2 の全体的なパフォーマンスは低く、Macro-F1 スコアはそれぞれ 36.18 と 32.72 です。これらのモデル (特に InternLM 2) は高い再現率を示しますが、精度が低いため、Macro-F1 スコアが低くなります。
MEDITRON は、マクロ F1 スコア 26.21 で、このタスクでは最下位にランクされています。 MMedIns-Llama 3 は他のすべてのモデルを大幅に上回り、マクロ精度 91.29、マクロ再現率 85.57、マクロ F1 スコア 87.37 というすべての指標で最高のスコアを達成しました。これらの結果は、テキストを正確に分類する MMedIns-Llama 3 の機能を強調しており、MMedIns-Llama 3 がこのタイプの複雑なタスクにとって最も効果的なモデルとなっています。
表 8: 4 つのカテゴリのタスクの結果: 治療計画 (SEER)、診断 (DDXPlus)、臨床転帰予測 (MIMIC4ED)、およびテキスト分類 (HoC 分類)。最初の 3 つのタスクの結果は精度に基づいており、テキスト分類の結果は適合率、再現率、および F1 スコアに基づいています。
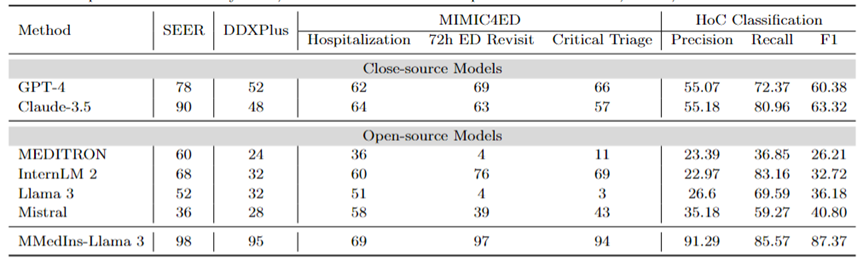
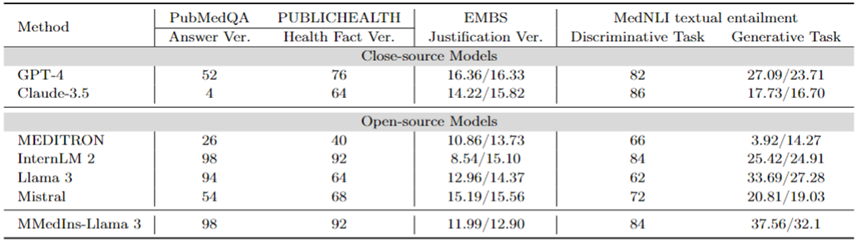
事実修正: 表 9 は、事実検証タスクのモデル評価結果を示しています。 PubMedQA 回答検証と HealthFact 検証では、LLM は提供された候補リストから回答を選択する必要があるため、精度が評価指標として使用されます。
対照的に、EBMS 位置揃え検証により、タスクには、BLEU-1 および ROUGE-1 スコアを使用してパフォーマンスを評価する自由形式のテキストの生成が含まれます。 InternLM 2 は、PubMedQA 回答検証と HealthFact 検証で最高の精度を達成し、それぞれ 98 と 92 のスコアを獲得しました。
EBMS ベンチマークでは、GPT-4 が最も強力なパフォーマンスを示し、BLEU-1/ROUGE-1 スコアはそれぞれ 16.36/16.33 でした。 Claude-3.5 は 14.22/15.82 のスコアで僅差で 2 番目ですが、PubMedQA の回答検証ではパフォーマンスが悪くなります。
Llama 3 の PubMedQA と HealthFact Verification の精度はそれぞれ 94 と 64、BLEU-1/ROUGE-1 スコアは 12.96/14.37 です。 MMedIns-Llama 3 は引き続き既存のモデルを上回っており、PubMedQA 回答検証タスクで InternLM 2 と並んで最高の精度スコアを達成しています。一方、EMBS では、MMedIns-Llama 3 は BLEU-1 および ROUGE-1 で 11.99/12.90 を達成しています。その結果は次のとおりです。 GPT-4よりわずかに遅れています。
医用テキスト含意 (NLI): 表 9 には、主に MedNLI を中心とした医用テキスト含意 (NLI) の評価結果も示します。テスト方法は 2 つあり、1 つは精度によって測定される識別タスク (候補リストから正しい答えを選択する) で、もう 1 つは BLEU/ROUGE メトリクスによって測定される生成タスク (自由形式のテキストの回答を生成する) です。
InternLM 2 は、オープンソース LLM の中で最高のスコア 84 を持っています。クローズドソース LLM の場合、GPT-4 と Claude-3.5 は両方とも、精度がそれぞれ 82 と 86 という比較的高いスコアを示しています。生成タスクでは、Llama 3 がグラウンド トゥルースとの一貫性が最も高く、BLEU および ROUGE スコアは 33.69/27.28 でした。ミストラルとラマ 3 は平均的なレベルでパフォーマンスを発揮しました。 GPT-4 は 27.09/23.71 のスコアで僅差で続きますが、Claude-3.5 は生成タスクで十分なパフォーマンスを発揮しません。
MMedIns-Llama 3 は、スコア 84 で識別タスクの精度が最も高くなりますが、Claude-3.5 にはわずかに遅れます。 MMedIns-Llama 3 は生成タスクでも良好なパフォーマンスを示し、BLEU/ROUGE スコアは 37.56/32.17 で、他のモデルよりも大幅に優れています。
表 9: 事実検証およびテキスト含意タスクの定量的結果 結果は、精度 (ACC) および BLEU/ROUGE によって測定されます。表中の「Ver.」は「検証」の略です。
一般に、研究チームはさまざまなタスクの側面で 6 つの主流モデルを評価しましたが、その研究結果は、現在の主流の LLM が臨床タスクを扱う場合には依然として非常に脆弱であることを示しています。多様で複雑な臨床シナリオにおいて深刻なパフォーマンスの欠陥を引き起こす可能性があります。
同時に、実験結果は、指示データセットに臨床タスクテキストを追加してLLMと実際の臨床応用との一致を強化することで、LLMのパフォーマンスを大幅に向上できることも示しています。
データ収集方法と学習プロセス
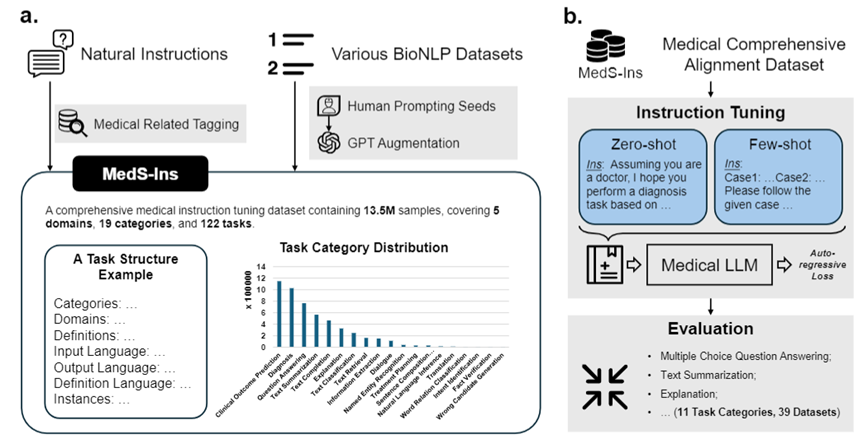
このセクションでは、図 3b に示すトレーニング プロセスを詳しく紹介します。具体的な方法は、以前の研究である MMedLM および PMC-LLaMA と同じであり、どちらも医療関連コーパスに対するさらなる自己回帰トレーニングを通じて、対応する医療知識をモデルに注入することができ、それにより、さまざまな下流タスクでのパフォーマンスを向上させることができます。
具体的には、研究チームは多言語 LLM ベース モデル (MMed-Llama 3) から開始し、MedS-Ins からの指導微調整データを使用してさらにトレーニングしました。
命令微調整用のデータには主に 2 つの側面が含まれます:
医学的にフィルタリングされた自然な命令データ: まず、スーパーナチュラル命令から。自然界 医療関連のタスクを除外します。 Super-NaturalInstructions は一般分野のさまざまな自然言語処理タスクに重点を置いているため、医療分野の分類粒度は比較的粗くなっています。
まず、「ヘルスケア」と「医療」カテゴリのすべての指示が抽出され、タスク カテゴリは変更されないまま、より詳細なドメイン ラベルが手動で追加されました。さらに、多くの一般的なドメイン構成の指示微調整データセットは、LIMA や ShareGPT などの一部の医療関連データもカバーしています。
これらのデータの医療部分を除外するために、研究チームは InsTag を使用して各指示の領域の大まかな分類を実行しました。具体的には、InsTag は、さまざまな命令サンプルにタグを付けるために設計された LLM です。指示クエリが与えられると、その指示がどのドメインとタスクに属しているかを分析し、これに基づいてヘルスケア、医療、または生物医学のラベルが付けられたサンプルをフィルタリングします。
最後に、一般ドメインで設定された命令データをフィルタリングすることにより、37 個のタスク、合計 75373 個のサンプルが収集されました。
既存の BioNLP データセットを構築するためのヒント: 既存のデータセットの中には、臨床シナリオでのテキスト分析に適した優れたデータセットが多数あります。ただし、ほとんどのデータセットはさまざまな目的で収集されるため、大規模な言語モデルのトレーニングに直接使用することはできません。ただし、これらの既存の医療 NLP タスクは、生成モデルのトレーニングに使用できる形式に変換することで、指導適応に組み込むことができます。
具体的には、研究チームは MIMIC-IV-Note を例に挙げました。 MIMIC-IV-Note は、所見と結論の両方を含む高品質で構造化されたレポートを提供します。所見から結論までの生成は、古典的な臨床文書の要約タスクと考えられています。まず、タスクを定義するためのプロンプトを手動で作成します。たとえば、「超音波画像診断の詳細な結果を踏まえて、その結果をいくつかの単語で要約してください」というもので、指導調整の多様性のニーズを考慮して、研究チームは 5 人の被験者に 3 つの異なる方法を個別に使用するよう依頼しました。特定のタスクについて説明するよう求められます。
これにより、タスクごとに 15 個の自由テキスト プロンプトが作成され、同様のセマンティクスを確保しながらも可能な限り多様な文言と書式が確保されました。次に、Self-Instruct に触発されて、これらの手動で書かれた命令がシード命令として使用され、GPT-4 はそれらに従って命令を書き換えて、より多様な命令を取得するように求められます。
上記のプロセスを通じて、追加の 85 のタスクが統一された自由質問と回答形式にプロンプトされ、フィルター処理されたデータと組み合わせることで、122 のタスクをカバーする合計 1,350 万の高品質のサンプルが取得されました。 MedS-Ins は、指導の微調整を通じて、新しい 8B サイズの医療 LLM をトレーニングしました。その結果、この方法が臨床タスクのパフォーマンスを大幅に向上させることが示されました。
命令の微調整において、研究チームは 2 つの命令形式に焦点を当てました:
ゼロサンプル プロンプト: ここでは、タスクの命令には意味論的なタスクの説明が含まれていますしたがって、モデルは内部モデルの知識に基づいて質問に直接答える必要があります。収集された MedS-In では、各タスクの「定義」内容がゼロポイントの指示入力として当然利用できます。さまざまな異なる医療タスクの定義がカバーされるため、モデルはさまざまなタスクの説明の意味的理解を学習することが期待されます。
いくつかのヒント: ここで、手順には、モデルがコンテキストからタスクのおおよその要件を学習できるようにする少数の例が含まれています。このような指示は、同じタスクのトレーニング セットから他のケースをランダムにサンプリングし、次の単純なテンプレートを使用して整理するだけで取得できます:
Case1: 入力: {CASE1_INPUT}、出力: {CASE1_OUTPUT} ... CaseN: 入力: {CASEN_INPUT}、出力: {CASEN_OUTPUT} {INSTRUCTION} 数ショットのケースから学習してください。出力する必要があるコンテンツを確認してください。 入力: {INPUT}
Discussion
全体として、この論文はいくつかの重要な貢献をしています :
包括的な評価ベンチマーク - MedS-Bench
医療 LLM の開発は、多肢選択質問回答 (MCQA) ベンチマーク テストに大きく依存しています。ただし、この狭い評価枠組みでは、さまざまな複雑な臨床シナリオにおける LLM の真の機能が無視されます。
したがって、この研究では、研究チームは、さまざまな臨床タスクにおけるクローズドソースおよびオープンソースの LLM のパフォーマンスを評価するために設計された包括的なベンチマークである MedS-Bench を導入します。モデル 事前にトレーニングされたコーパスから事実を思い出したり、与えられたコンテキストから推論したりするタスク。
今回の調査結果は、既存の LLM は MCQA ベンチマークでは良好なパフォーマンスを示しているものの、特に治療の推奨や説明などのタスクにおいて、臨床実践と一致させるのに苦労していることを示しています。この発見は、より広範囲の臨床および医療シナリオに適応する医療用大規模言語モデルのさらなる開発の必要性を強調しています。
包括的な指導調整データセット -- MedS-Ins
研究チームは既存の BioNLP データセットからデータを広範囲に取得し、これらのサンプルを統一フォーマットに変換しました。同時に、半自動プロンプト戦略を使用して、新しい医療オーダー調整データセットである MedS-Ins を構築および開発しました。指導の微調整データセットに関するこれまでの研究は、主に日常会話、試験、または学術論文から質問と回答のペアを構築することに焦点を当てており、多くの場合、実際の臨床実践から生成されたテキストは無視されていました。
対照的に、MedS-Ins は、5 つの主要なテキスト領域と 19 のタスク カテゴリを含む、より広範囲の医療テキスト リソースを統合しています。このデータ構成の系統的な分析により、ユーザーは LLM の臨床応用の境界を理解しやすくなります。
医療用大規模言語モデル -- MMedIns-Llama 3
モデルに関して、研究チームは MedS-Ins で指示の微調整トレーニングを実行することでそれを証明しました。オープンソースの医療 LLM と臨床ニーズとの調整を大幅に改善できます。
最終モデル MMedIns-Llama 3 は、どちらかというと「概念実証」モデルであることを強調する必要があります。最終モデルは、8B の中程度のパラメーター スケールを使用しています。臨床タスクをサポートし、タスク固有のトレーニングをさらに必要とせずに、ゼロまたは少数の指示プロンプトを通じてさまざまな医療シナリオに柔軟に適応できます。
結果は、特定の臨床タスクの種類において、MMedIns-Llama 3 が GPT-4、Claude-3.5 などの既存の LLM よりも優れていることを示しています。
既存の制限
ここで、研究チームはこの記事の制限と将来の改善の可能性についても強調したいと考えています。
まず第一に、MedS-Bench は現在 11 の臨床タスクのみをカバーしており、すべての臨床シナリオの複雑さを完全にはカバーしていません。さらに、6 つの主流 LLM が評価されましたが、最新の LLM の一部は依然として分析に含まれていませんでした。これらの制限に対処するために、研究チームは、より多くの研究者が医療 LLM の包括的な評価ベンチマークを継続的に拡張および改善することを奨励することを目的として、この記事の公開と同時に Medical LLM Leaderboard をリリースする予定です。評価プロセスにさまざまなテキスト ソースからのより多くのタスク カテゴリを含めることで、医療における LLM の開発と使用の境界についてより深い理解が得られることが期待されます。
第二に、MedS-Ins は現在、幅広い医療業務をカバーしていますが、まだ不完全で、いくつかの実践的な医療シナリオが欠けています。この問題を解決するために、研究チームは収集したすべてのデータとリソースを GitHub 上でオープンソース化しました。私は、より多くの臨床医や研究者が協力して、一般分野の Super-NaturalInstructs と同様に、この指示調整データセットを維持および拡張できることを心から願っています。研究チームは、GitHub ページで詳細なアップロード手順を提供しており、論文の反復更新でデータセットの更新に参加したすべての貢献者に書面で感謝する予定です。
第三に、研究チームは、より強力な多言語医療 LLM の開発をサポートするために、MedS-Bench と MedS-Ins にさらに多くの言語を追加する予定です。現在、これらのリソースは主に英語中心ですが、MedS-Bench および MedS-Ins にはいくつかの多言語タスクが含まれています。これをより広範囲の言語に拡張することは、医療 AI の最近の進歩がより広範囲でより多様な地域に公平に利益をもたらすことができるようにするために、有望な将来の方向性となるでしょう。
ついに、研究チームはすべてのコード、データ、評価プロセスをオープンソース化しました。この研究により、医療 LLM の開発が、これらの強力な言語モデルを実際の臨床アプリケーションと統合する方法にさらに重点を置くようになることが期待されています。
以上是邁向「多面手」醫療大模型,上交大團隊發布大規模指令微調資料、開源模型與全面基準測試的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















