
應用程式中的計算困境
開發和框架,哪個優先?
Java 是應用程式開發中最常用的程式語言。但用 Java 寫處理資料的程式碼並不簡單。例如,以下是將兩個欄位分組和聚合的Java程式碼:
Map<Integer, Map<String, Double>> summary = new HashMap<>();
for (Order order : orders) {
int year = order.orderDate.getYear();
String sellerId = order.sellerId;
double amount = order.amount;
Map<String, Double> salesMap = summary.get(year);
if (salesMap == null) {
salesMap = new HashMap<>();
summary.put(year, salesMap);
}
Double totalAmount = salesMap.get(sellerId);
if (totalAmount == null) {
totalAmount = 0.0;
}
salesMap.put(sellerId, totalAmount + amount);
}
for (Map.Entry<Integer, Map<String, Double>> entry : summary.entrySet()) {
int year = entry.getKey();
Map<String, Double> salesMap = entry.getValue();
System.out.println("Year: " + year);
for (Map.Entry<String, Double> salesEntry : salesMap.entrySet()) {
String sellerId = salesEntry.getKey();
double totalAmount = salesEntry.getValue();
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
}
}
相較之下,SQL 對應的部分就簡單得多。一個 GROUP BY 子句足以關閉計算。
從訂單分組中選擇年份(訂單日期),賣家 ID,總和(金額)按年份(訂單日期),賣家 ID
事實上,早期的應用程式是透過 Java 和 SQL 的協作來運作的。應用端採用Java實作業務流程,後端資料庫採用SQL進行資料處理。由於資料庫限制,該框架難以擴展和遷移。這對於當代的應用來說是非常不友善的。而且很多時候沒有資料庫或涉及到跨庫運算時SQL是不可用的。
有鑑於此,後來許多應用程式開始採用完全基於Java的框架,資料庫只做簡單的讀寫操作,應用端的業務流程和資料處理都是用Java實現,尤其是微服務出現後。這樣應用程式就與資料庫解耦了,並且獲得了良好的可擴展性和可移植性,這有助於在面對前面提到的Java開發複雜性的同時獲得框架優勢。
看來我們只能專注於一個面向-開發或框架。要享受Java框架的優勢,就必須忍受開發的困難;而要使用SQL,就需要容忍框架的缺點。這就造成了一個兩難的境地。
那我們能做什麼呢?
那麼增強Java的資料處理能力呢?這不僅避免了 SQL 問題,也克服了 Java 的缺點。
其實Java Stream/Kotlin/Scala都在嘗試這樣做。
直播
Java 8中引入的Stream增加了許多資料處理方法。以下是實作上述計算的 Stream 程式碼:
Map<Integer, Map<String, Double>> summary = orders.stream()
.collect(Collectors.groupingBy(
order -> order.orderDate.getYear(),
Collectors.groupingBy(
order -> order.sellerId,
Collectors.summingDouble(order -> order.amount)
)
));
summary.forEach((year, salesMap) -> {
System.out.println("Year: " + year);
salesMap.forEach((sellerId, totalAmount) -> {
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
});
});
Stream確實在一定程度上簡化了程式碼。但整體來說還是比較麻煩,而且遠不如 SQL 簡潔。
科特林
號稱更強大的Kotlin,進一步進步:
val summary = orders
.groupBy { it.orderDate.year }
.mapValues { yearGroup ->
yearGroup.value
.groupBy { it.sellerId }
.mapValues { sellerGroup ->
sellerGroup.value.sumOf { it.amount }
}
}
summary.forEach { (year, salesMap) ->
println("Year: $year")
salesMap.forEach { (sellerId, totalAmount) ->
println(" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Kotlin 程式碼更簡單,但改進有限。和SQL相比還是有很大差距
斯卡拉
然後是 Scala:
val summary = orders
.groupBy(order => order.orderDate.getYear)
.mapValues(yearGroup =>
yearGroup
.groupBy(_.sellerId)
.mapValues(sellerGroup => sellerGroup.map(_.amount).sum)
)
summary.foreach { case (year, salesMap) =>
println(s"Year: $year")
salesMap.foreach { case (sellerId, totalAmount) =>
println(s" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Scala 比 Kotlin 簡單一點,但仍然無法與 SQL 相比。另外Scala太笨重,使用起來不方便。
事實上,這些技術雖然不完美,但走在正確的道路上。
編譯語言不可熱插拔
此外,Java 作為一種編譯語言,缺乏對熱插拔的支援。修改程式碼需要重新編譯和重新部署,通常需要重新啟動服務。當面對需求的頻繁變化時,這會導致體驗不佳。相比之下,SQL在這方面就沒有問題。

Java開發複雜,框架也有缺陷。 SQL很難滿足框架的要求。困境很難解決。還有別的辦法嗎?
終極解法-集算器SPL
集算器SPL是一種純Java開發的資料處理語言。它開發簡單,框架靈活。
簡潔的文法
讓我們回顧一下上述分組和聚合操作的 Java 實作:

與Java程式碼相比,SPL程式碼簡潔得多:
Orders.groups(year(orderdate),sellerid;sum(amount))
就像SQL實作一樣簡單:
SELECT year(orderdate),sellerid,sum(amount) FROM orders GROUP BY year(orderDate),sellerid
事實上,SPL 程式碼通常比 SQL 程式碼更簡單。由於支援基於順序和過程計算,SPL 能夠更好地執行複雜計算。考慮這個例子:計算股票連續上漲的最大天數。 SQL需要下面的三層巢狀語句,很難理解,更別說寫了。
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
SPL 只需一行程式碼即可實現計算。這比 SQL 程式碼還要簡單得多,更不用說 Java 程式碼了。
stock.sort(tradeDate).group@i(price<price[-1]).max(~.len())
Comprehensive, independent computing capability
SPL has table sequence – the specialized structured data object, and offers a rich computing class library based on table sequences to handle a variety of computations, including the commonly seen filtering, grouping, sorting, distinct and join, as shown below:
Orders.sort(Amount) // Sorting Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // Filtering Orders.groups(Client; sum(Amount)) // Grouping Orders.id(Client) // Distinct join(Orders:o,SellerId ; Employees:e,EId) // Join ……
More importantly, the SPL computing capability is independent of databases; it can function even without a database, which is unlike the ORM technology that requires translation into SQL for execution.
Efficient and easy to use IDE
Besides concise syntax, SPL also has a comprehensive development environment offering debugging functionalities, such as “Step over” and “Set breakpoint”, and very debugging-friendly WYSIWYG result viewing panel that lets users check result for each step in real time.
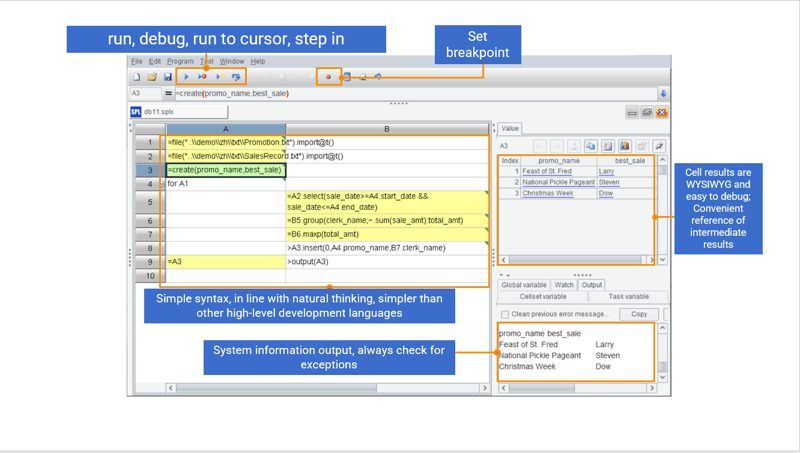
Support for large-scale data computing
SPL supports processing large-scale data that can or cannot fit into the memory.
In-memory computation:

External memory computation:

We can see that the SPL code of implementing an external memory computation and that of implementing an in-memory computation is basically the same, without extra computational load.
It is easy to implement parallelism in SPL. We just need to add @m option to the serial computing code. This is far simpler than the corresponding Java method.

Seamless integration into Java applications
SPL is developed in Java, so it can work by embedding its JARs in the Java application. And the application executes or invokes the SPL script via the standard JDBC. This makes SPL very lightweight, and it can even run on Android.
Call SPL code through JDBC:
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("call SplScript(?)");
st.setObject(1, "A");
st.execute();
ResultSet rs = st.getResultSet();
ResultSetMetaData rsmd = rs.getMetaData();
As it is lightweight and integration-friendly, SPL can be seamlessly integrated into mainstream Java frameworks, especially suitable for serving as a computing engine within microservice architectures.
Highly open framework
SPL’s great openness enables it to directly connect to various types of data sources and perform real-time mixed computations, making it easy to handle computing scenarios where databases are unavailable or multiple/diverse databases are involved.

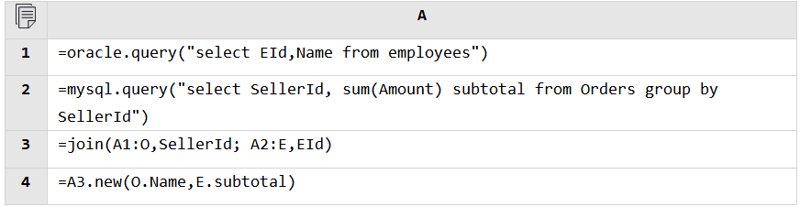
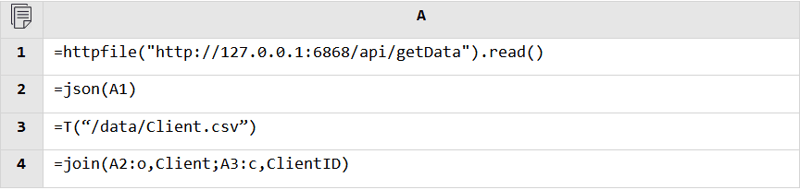
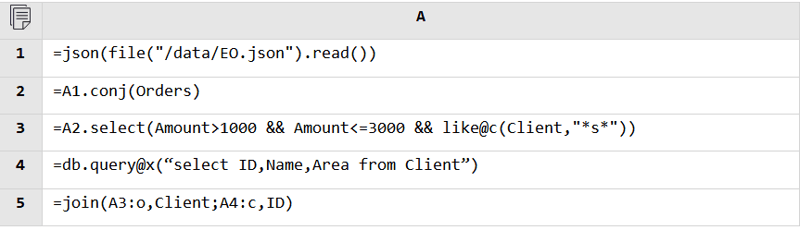
Regardless of the data source, SPL can read data from it and perform the mixed computation as long as it is accessible. Database and database, RESTful and file, JSON and database, anything is fine.
Databases:
RESTful and file:
JSON and database:
Interpreted execution and hot-swapping
SPL is an interpreted language that inherently supports hot swapping while power remains switched on. Modified code takes effect in real-time without requiring service restarts. This makes SPL well adapt to dynamic data processing requirements.

This hot—swapping capability enables independent computing modules with separate management, maintenance and operation, creating more flexible and convenient uses.
SPL can significantly increase Java programmers’ development efficiency while achieving framework advantages. It combines merits of both Java and SQL, and further simplifies code and elevates performance.
SPL open source address
以上是有些東西可以讓 Java 程式設計師的開發效率加倍的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















