
簡介
熟能生巧。
這與資料科學家有許多共同點。理論只是等式的一個面向;最關鍵的是將理論付諸實踐。我將努力記錄今天開發我的頂點專案的整個過程,其中將涉及研究電影資料集。
這些是目標:
目標:
1。資料收集
我決定使用 Kaggle 來尋找我的資料集。記住您正在使用的資料集所需的關鍵變數至關重要。重要的是,我的資料集應該包括以下內容:發行年份的趨勢、導演的受歡迎程度、收視率和電影類型。因此,我必須確保我選擇的資料集至少具有以下內容。
我的資料集位於 Kaggle 上,我將提供下面的連結。您可以透過下載資料集、解壓縮並提取來取得該檔案的 CSV 版本。您可以查看它以了解您已經擁有的內容,並真正了解您希望從將要檢查的數據中獲得什麼樣的見解。
2。描述資料
首先,我們必須導入所需的函式庫並載入必要的資料。我在我的專案中使用 Python 程式語言和 Jupyter Notebooks,以便我可以更有效率地編寫和查看程式碼。
您將導入我們將使用的庫並加載數據,如下所示。
然後我們將執行以下命令來獲取有關我們的資料集的更多詳細資訊。
data.head() # dispalys the first rows of the dataset. data.tail() # displays the last rows of the dataset. data.shape # Shows the total number of rows and columns. len(data.columns) # Shows the total number of columns. data.columns # Describes different column names. data.dtypes # Describes different data types.
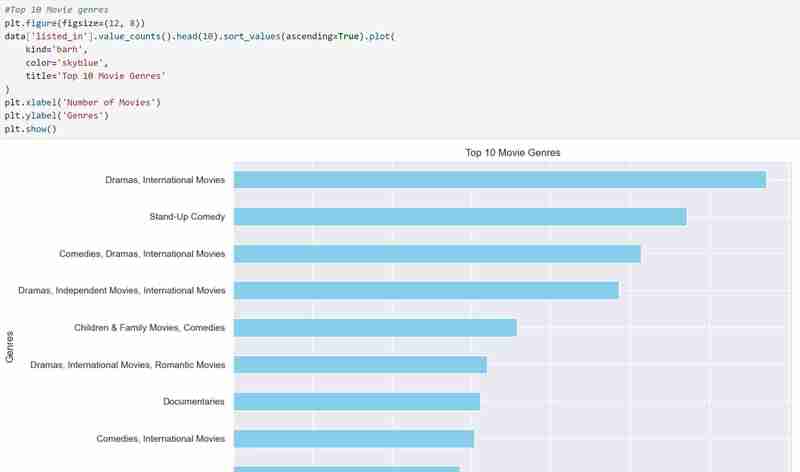
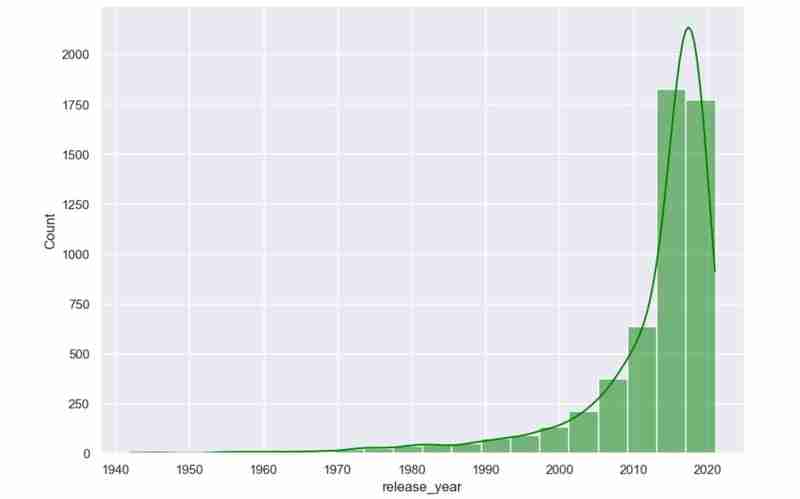
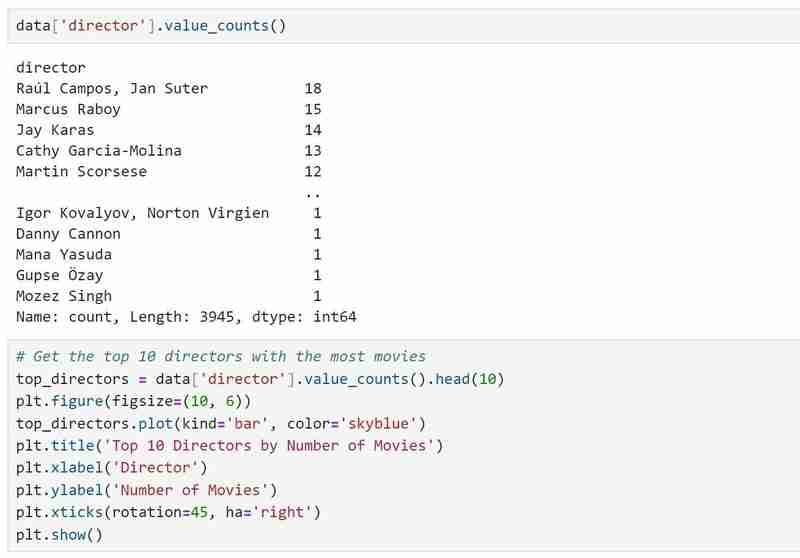
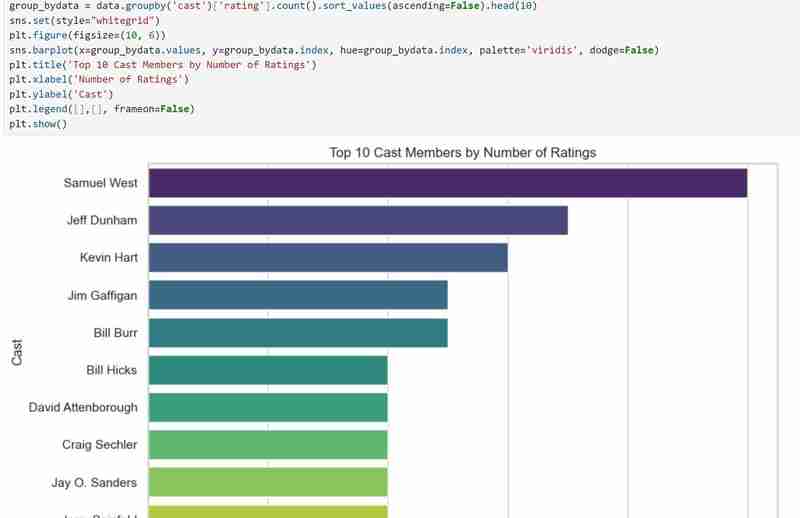
我們現在知道資料集包含什麼以及在獲得我們需要的所有描述後我們希望提取的見解。範例:使用我的資料集,我希望調查導演受歡迎程度、收視率分佈和電影類型的模式。我還想根據用戶選擇的偏好推薦電影,例如喜歡的導演和類型。
3。資料清理
此階段涉及尋找所有空值並將其刪除。為了繼續資料視覺化,我們還將檢查資料集是否有重複項,並刪除我們發現的任何內容。為此,我們將運行以下程式碼:
1. data['show_id'].value_counts().sum() # Checks for the total number of rows in my dataset 2. data.isna().sum() # Checks for null values(I found null values in director, cast and country columns) 3. data[['director', 'cast', 'country']] = data[['director', 'cast', 'country']].replace(np.nan, "Unknown ") # Fill null values with unknown.
然後我們將刪除具有未知值的行並確認我們已刪除所有這些行。我們還將檢查已清理資料的剩餘行數。
下面的程式碼尋找獨特的特徵和重複項。儘管我的資料集中沒有重複項,但您可能仍然需要使用它,以防將來的資料集出現重複項。
data.duplicated().sum() # Checks for duplicates data.nunique() # Checks for unique features data.info # Confirms if nan values are present and also shows datatypes.
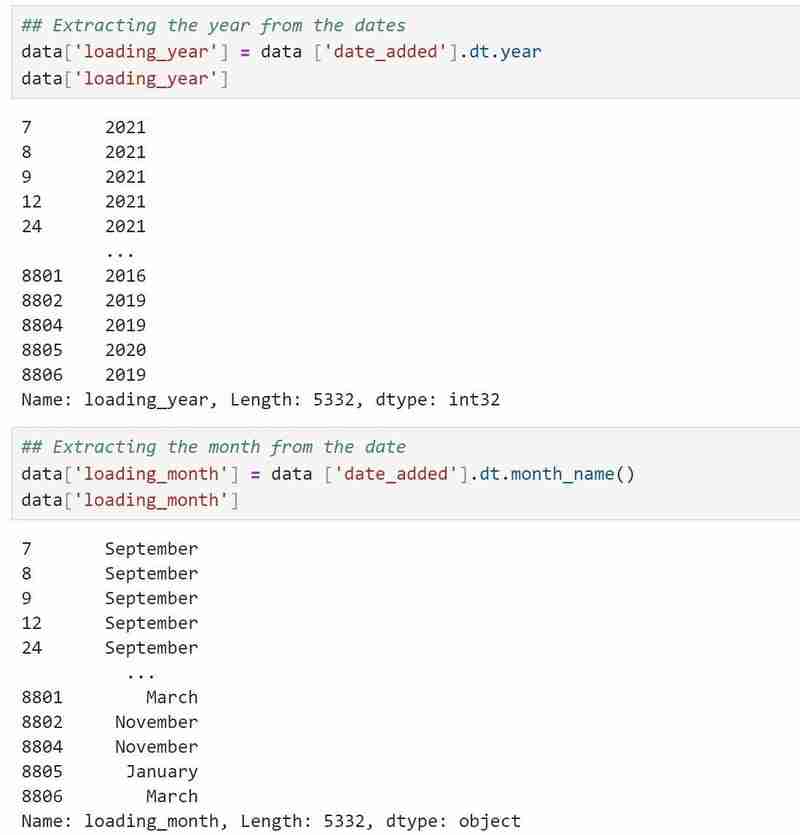
我的日期/時間資料類型是一個對象,我希望它採用正確的日期/時間格式,所以我使用了
data['date_added']=data['date_added'].astype('datetime64[ms]')將其轉換為正確的格式。
4。數據視覺化
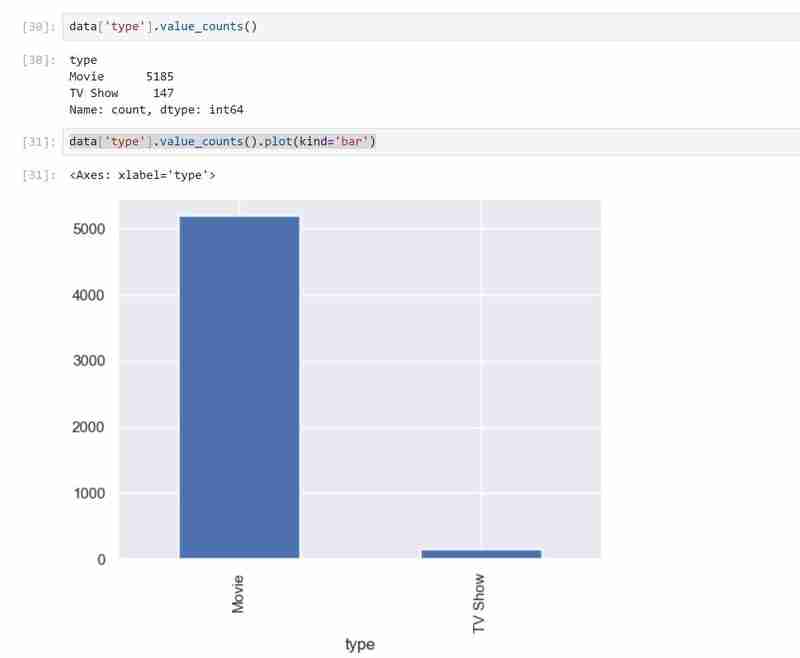
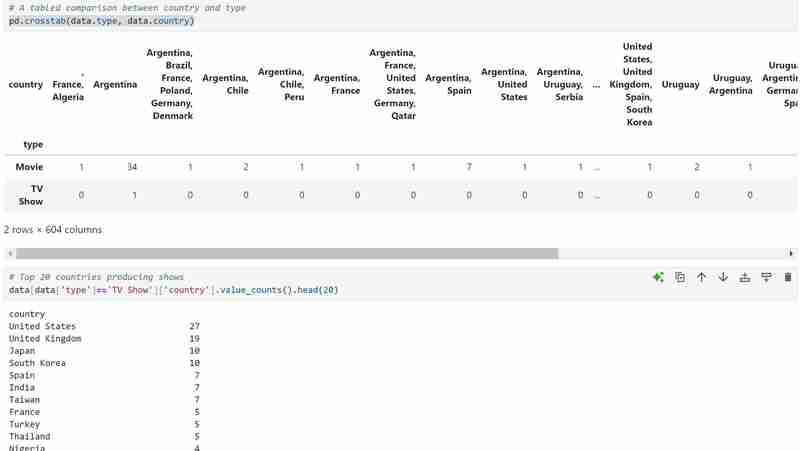
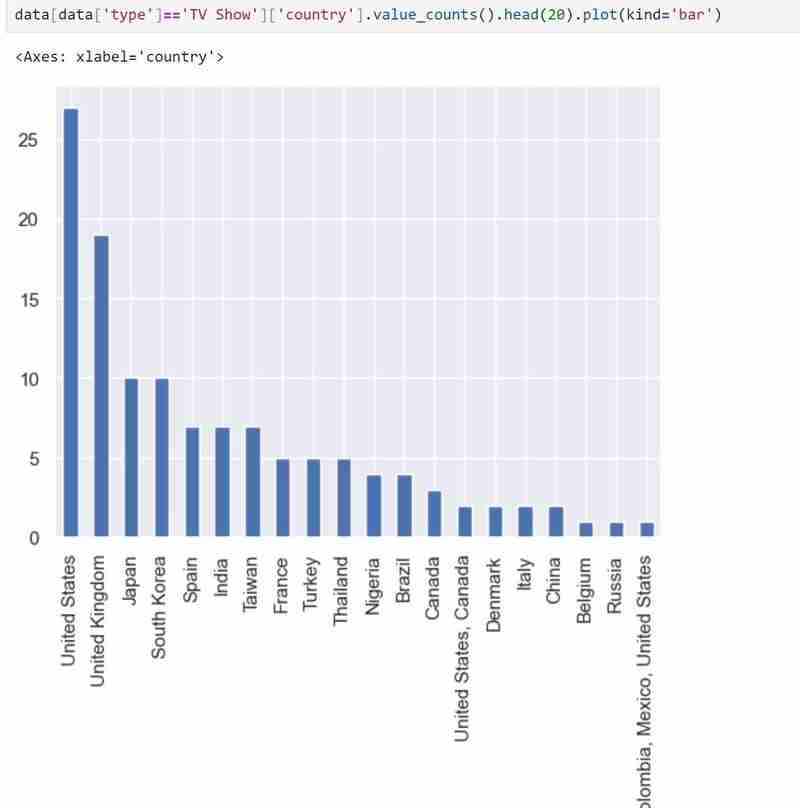
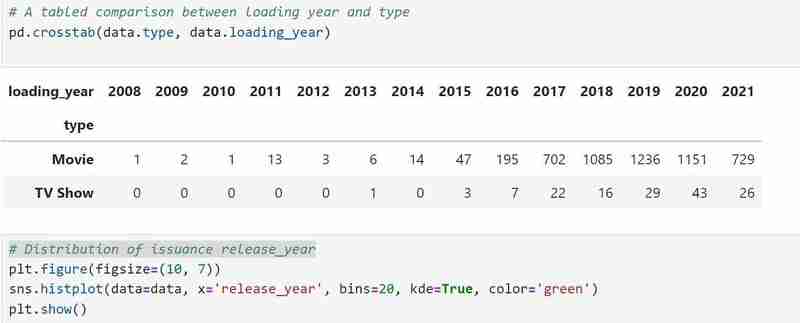
我的資料集有兩種類型的變量,即類型中的電視節目和電影,我使用長條圖來呈現分類資料及其代表的值。
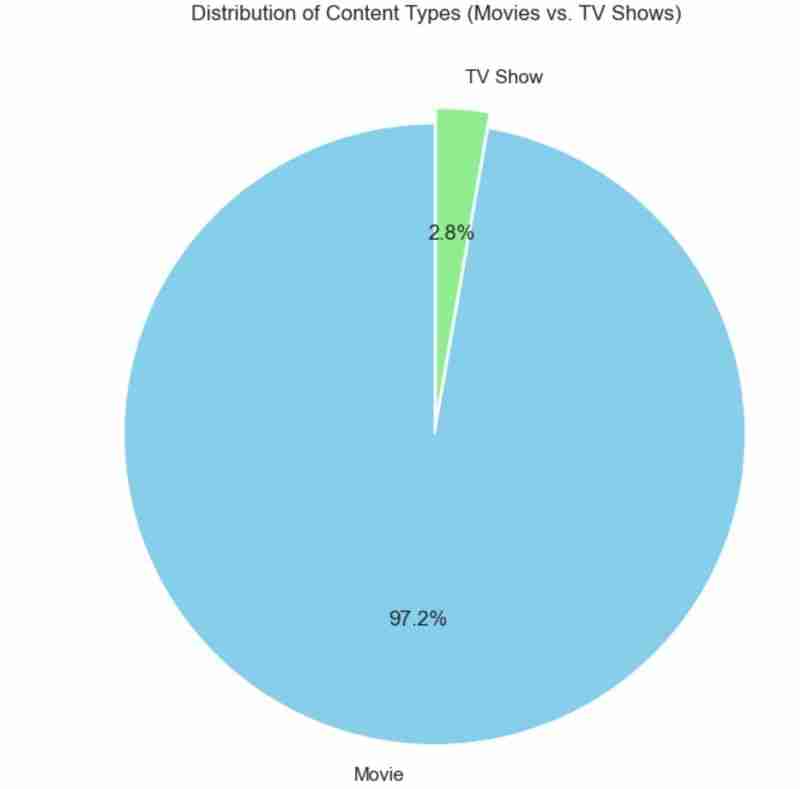
我也用圓餅圖來表示,跟上面一樣。使用的程式碼如下,預期結果如下所示。
## Pie chart display
plt.figure(figsize=(8, 8))
data['type'].value_counts().plot(
kind='pie',
autopct='%1.1f%%',
colors=['skyblue', 'lightgreen'],
startangle=90,
explode=(0.05, 0)
)
plt.title('Distribution of Content Types (Movies vs. TV Shows)')
plt.ylabel('')
plt.show()
5. Recommendation System
I then built a recommendation system that takes in genre or director's name as input and produces a list of movies as per the user's preference. If the input cannot be matched by the algorithm then the user is notified.

The code for the above is as follows:
def recommend_movies(genre=None, director=None):
recommendations = data
if genre:
recommendations = recommendations[recommendations['listed_in'].str.contains(genre, case=False, na=False)]
if director:
recommendations = recommendations[recommendations['director'].str.contains(director, case=False, na=False)]
if not recommendations.empty:
return recommendations[['title', 'director', 'listed_in', 'release_year', 'rating']].head(10)
else:
return "No movies found matching your preferences."
print("Welcome to the Movie Recommendation System!")
print("You can filter movies by Genre or Director (or both).")
user_genre = input("Enter your preferred genre (or press Enter to skip): ")
user_director = input("Enter your preferred director (or press Enter to skip): ")
recommendations = recommend_movies(genre=user_genre, director=user_director)
print("\nRecommended Movies:")
print(recommendations)
Conclusion
My goals were achieved, and I had a great time taking on this challenge since it helped me realize that, even though learning is a process, there are days when I succeed and fail. This was definitely a success. Here, we celebrate victories as well as defeats since, in the end, each teach us something. Do let me know if you attempt this.
Till next time!
Note!!
The code is in my GitHub:
https://github.com/MichelleNjeri-scientist/Movie-Dataset-Exploration-and-Visualization
The Kaggle dataset is:
https://www.kaggle.com/datasets/shivamb/netflix-shows
以上是電影資料集探索與視覺化的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















